

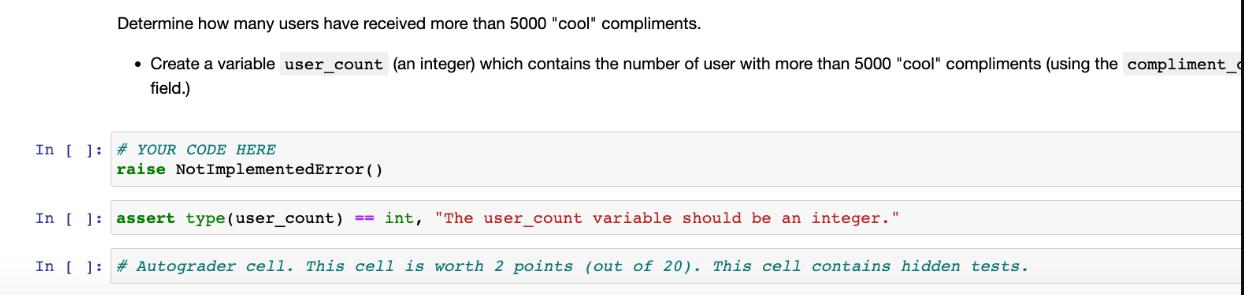
Determine how many users have received more than 5000 cool compliments. Create a variable user_count...
Fantastic news! We've Found the answer you've been seeking!
Question:
Transcribed Image Text:
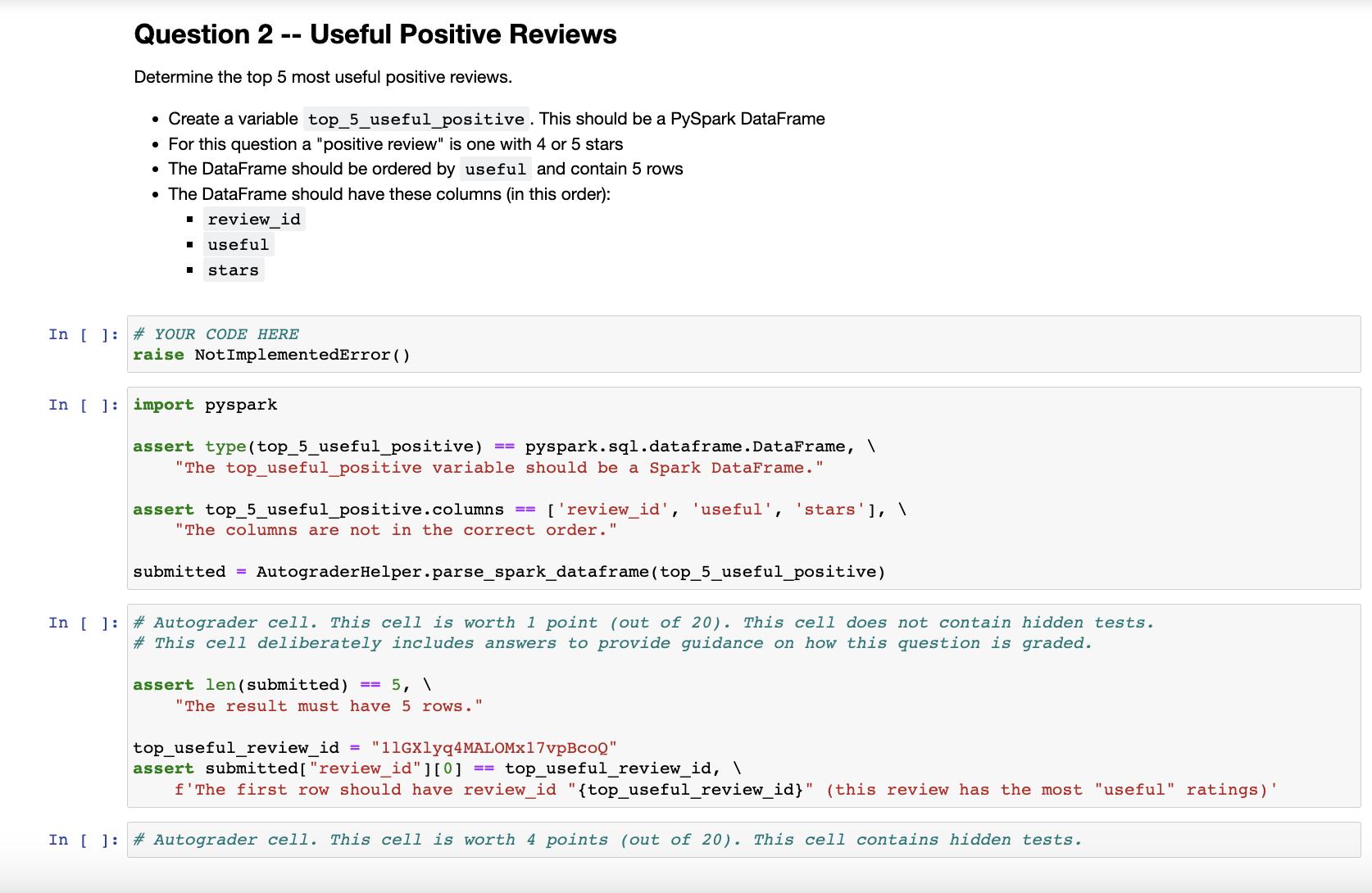
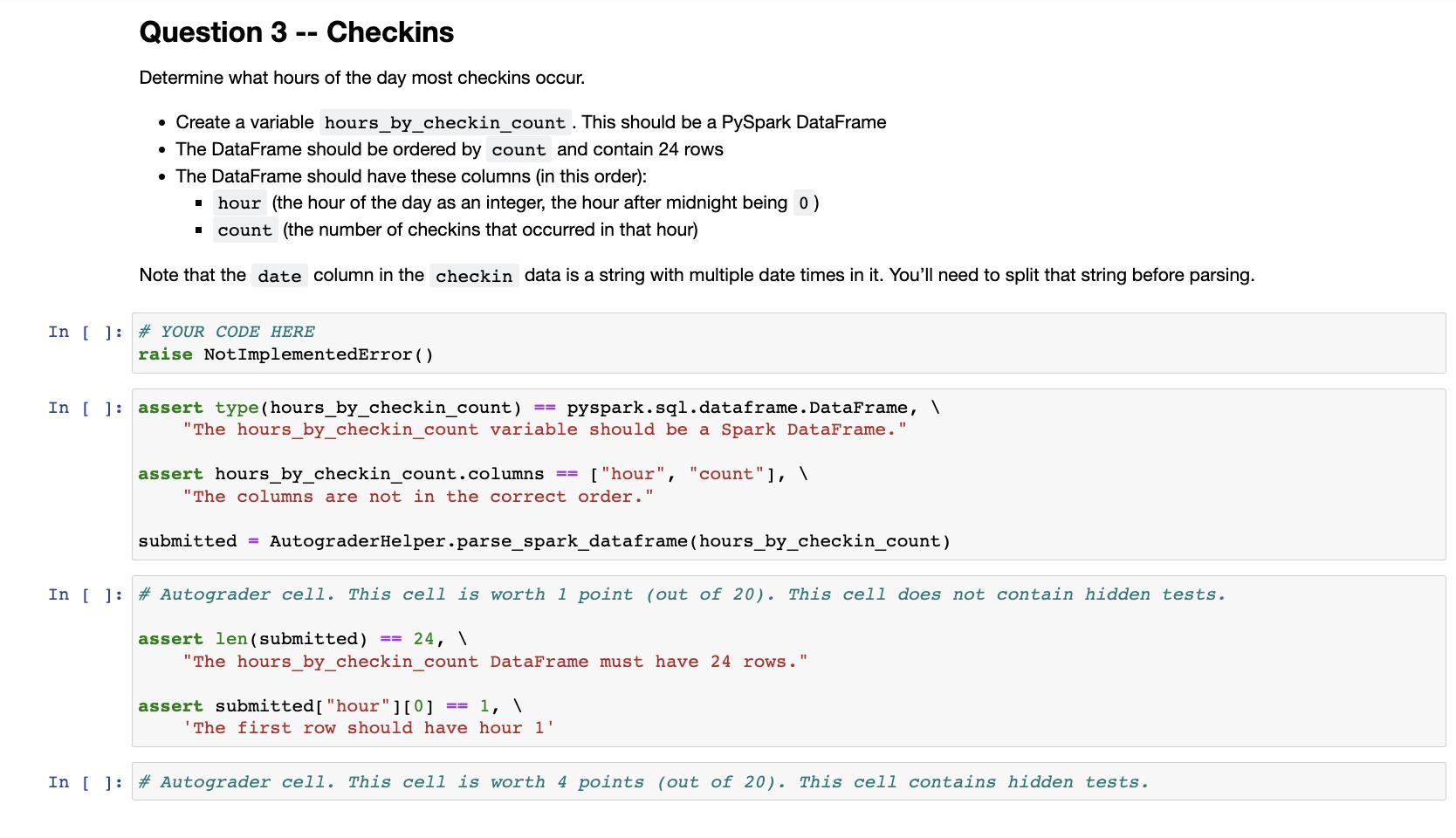
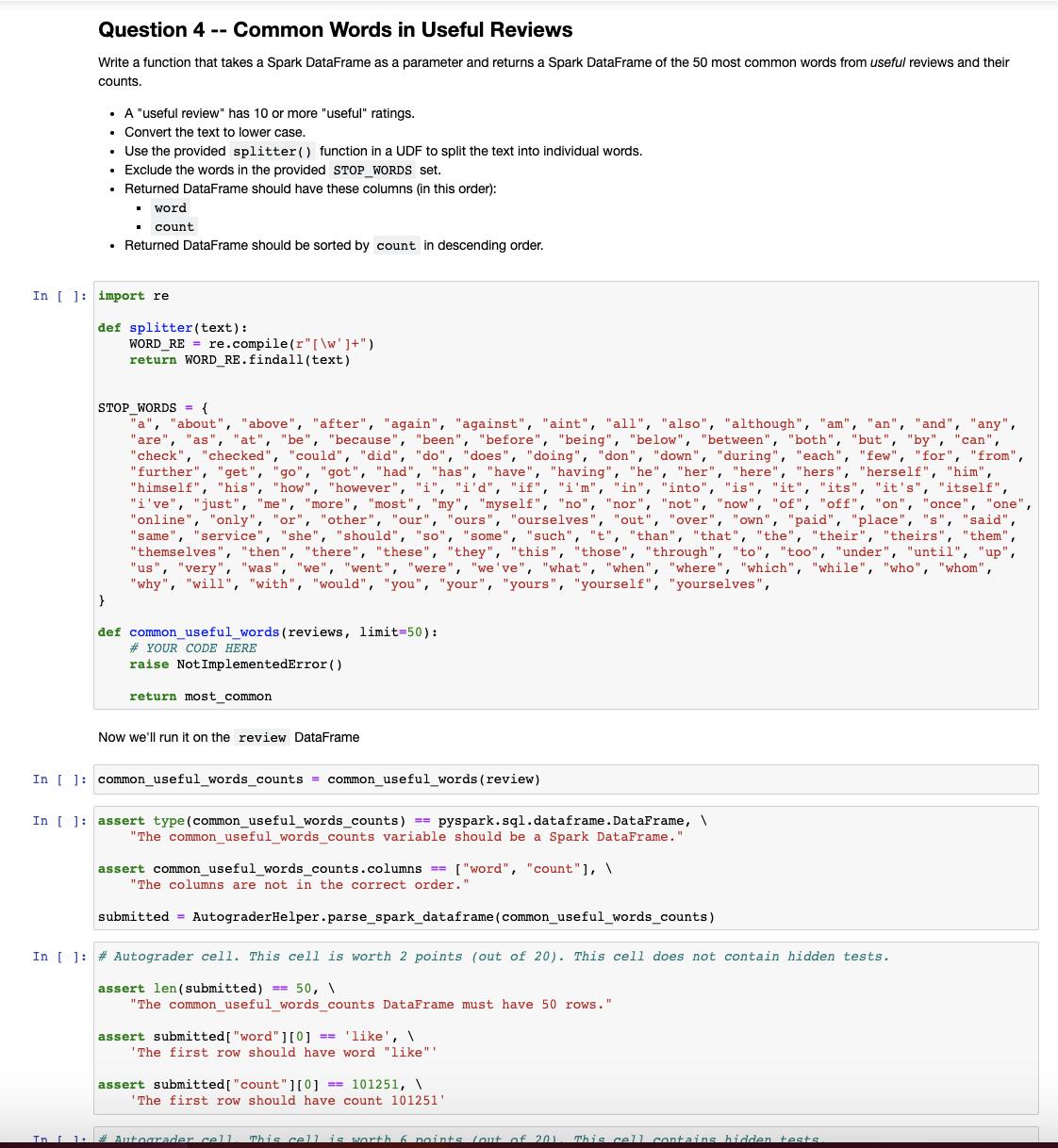
Determine how many users have received more than 5000 "cool" compliments. • Create a variable user_count (an integer) which contains the number of user with more than 5000 "cool" compliments (using the compliment_ field.) In [ ] # YOUR CODE HERE raise NotImplementedError() In [ ] assert type (user_count) == int, "The user_count variable should be an integer." In [ ] # Autograder cell. This cell is worth 2 points (out of 20). This cell contains hidden tests. Question 2 Determine the top 5 most useful positive reviews. • Create a variable top_5_useful_positive. This should be a PySpark DataFrame . For this question a "positive review" is one with 4 or 5 stars The DataFrame should be ordered by useful and contain 5 rows • The DataFrame should have these columns (in this order): ■ review_id ■ useful I stars. ● -- In [ ] # YOUR CODE HERE Useful Positive Reviews In [] import pyspark raise NotImplementedError() assert type (top_5_useful_positive) pyspark.sql.dataframe.DataFrame, \ "The top_useful_positive variable should be a Spark DataFrame." == assert top_5_useful_positive.columns "The columns are not in the correct order.' ['review_id', 'useful', 'stars'], \ submitted = AutograderHelper.parse_spark_dataframe (top_5_useful_positive) assert len (submitted) == 5, \ In [ ] # Autograder cell. This cell is worth 1 point (out of 20). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. "The result must have 5 rows." top_useful_review_id = "11GX1yq4MALOMx17vpBcOQ" assert submitted [ "review_id"][0] ==top_useful_review_id, \ f'The first row should have review_id "{top_useful_review_id}" (this review has the most "useful" ratings) In [] #Autograder cell. This cell is worth 4 points (out of 20). This cell contains hidden tests. Question 3 -- Checkins Determine what hours of the day most checkins occur. • Create a variable hours_by_checkin_count. This should be a PySpark DataFrame • The DataFrame should be ordered by count and contain 24 rows • The DataFrame should have these columns (in this order): hour (the hour of the day as an integer, the hour after midnight being 0) ■ count (the number of checkins that occurred in that hour) Note that the date column in the checkin data is a string with multiple date times in it. You'll need to split that string before parsing. In [ ] # YOUR CODE HERE raise NotImplementedError() In [ ]: assert type (hours_by_checkin_count) == pyspark.sql.dataframe. DataFrame, "The hours_by_checkin_count variable should be a Spark DataFrame." assert hours_by_checkin_count.columns == ["hour", "count"], \ "The columns are not in the correct order." submitted = AutograderHelper.parse_spark_dataframe (hours_by_checkin_count) In [ ] #Autograder cell. This cell is worth 1 point (out of 20). This cell does not contain hidden tests. assert len (submitted) == 24, \ "The hours_by_checkin_count DataFrame must have 24 rows. assert submitted [ "hour"][0] == 1, \ 'The first row should have hour 1' In [ ] # Autograder cell. This cell is worth 4 points (out of 20). This cell contains hidden tests. Question 4 -- Common Words in Useful Reviews Write function that takes a Spark DataFrame as a parameter and returns a Spark DataFrame of the 50 most common words from useful reviews and their counts. • A "useful review" has 10 or more "useful" ratings. . Convert the text to lower case. • Use the provided splitter() function in a UDF to split the text into individual words. Exclude the words in the provided STOP WORDS set. Returned DataFrame should have these columns (in this order): ■ word . count • Returned DataFrame should be sorted by count in descending order. . } . In [ ] import re def splitter (text): WORD_RE= re.compile(r"[\w']+") return WORD_RE.findall(text) STOP WORDS = { a "about", "above", "after", "again", "against", "aint", "all", "also", "although", "am", "an", "and", "any", "are", "as", "at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "can", "check", "checked", "could", "did", "do", "does", "doing", "don", "down", "during", "each", "few", "for", "from", "further", "get", "go", "got", "had", "has", "have", "having", "he", "her", "here", "hers", "herself", "him", "himself", "his", "how", "however", "i", "i'd", "if", "i'm", "in", "into", "is", "it", "its", "it's", "itself", "i've", "just", "me", "more", "most", "my", "myself", "no", "nor", "not", "now", "of", "off", "on", "once", "one", "online", "only", "or", "other", "our", "ours", "ourselves", "out", "over", "own", "paid", "place", "s", "said", "same", "service", "she", "should", "so", "some", "such", "t", "than", "that", "the", "their", "theirs", "them", "themselves", "then", "there", "these", "they", "this", "those", "through", "to", "too", "under", "until", "up", "us", "very", "was", "we", "went", "were", "we've", "what", "when", "where", "which", "while", "who", "whom", "why", "will", "with", "would", "you", "your", "yours", "yourself", "yourselves", def common_useful_words (reviews, limit=50): #YOUR CODE HERE raise Not ImplementedError() return most common Now we'll run it on the review DataFrame In [ ]: common_useful_words_counts = common_useful_words (review) In [ ] assert type (common_useful_words_counts) == pyspark.sql.dataframe.DataFrame, \ "The common_useful_words_counts variable should be a Spark DataFrame." assert common_useful_words_counts.columns == ["word", "count"], \ "The columns are not in the correct order." submitted = AutograderHelper.parse_spark_dataframe (common_useful_words_counts) In [ ] # Autograder cell. This cell is worth 2 points (out of 20). This cell does not contain hidden tests. assert len (submitted) == 50, \ "The common_useful_words_counts DataFrame must have 50 rows." assert submitted [ "word"][0] == 'like', \ 'The first row should have word "like"" assert submitted [ "count"][0]==101251, \ 'The first row should have count 101251' In [ 1: # Autograder cell I This cell is worth 6 points out of 201 This cell contains hidden tests. Determine how many users have received more than 5000 "cool" compliments. • Create a variable user_count (an integer) which contains the number of user with more than 5000 "cool" compliments (using the compliment_ field.) In [ ] # YOUR CODE HERE raise NotImplementedError() In [ ] assert type (user_count) == int, "The user_count variable should be an integer." In [ ] # Autograder cell. This cell is worth 2 points (out of 20). This cell contains hidden tests. Question 2 Determine the top 5 most useful positive reviews. • Create a variable top_5_useful_positive. This should be a PySpark DataFrame . For this question a "positive review" is one with 4 or 5 stars The DataFrame should be ordered by useful and contain 5 rows • The DataFrame should have these columns (in this order): ■ review_id ■ useful I stars. ● -- In [ ] # YOUR CODE HERE Useful Positive Reviews In [] import pyspark raise NotImplementedError() assert type (top_5_useful_positive) pyspark.sql.dataframe.DataFrame, \ "The top_useful_positive variable should be a Spark DataFrame." == assert top_5_useful_positive.columns "The columns are not in the correct order.' ['review_id', 'useful', 'stars'], \ submitted = AutograderHelper.parse_spark_dataframe (top_5_useful_positive) assert len (submitted) == 5, \ In [ ] # Autograder cell. This cell is worth 1 point (out of 20). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. "The result must have 5 rows." top_useful_review_id = "11GX1yq4MALOMx17vpBcOQ" assert submitted [ "review_id"][0] ==top_useful_review_id, \ f'The first row should have review_id "{top_useful_review_id}" (this review has the most "useful" ratings) In [] #Autograder cell. This cell is worth 4 points (out of 20). This cell contains hidden tests. Question 3 -- Checkins Determine what hours of the day most checkins occur. • Create a variable hours_by_checkin_count. This should be a PySpark DataFrame • The DataFrame should be ordered by count and contain 24 rows • The DataFrame should have these columns (in this order): hour (the hour of the day as an integer, the hour after midnight being 0) ■ count (the number of checkins that occurred in that hour) Note that the date column in the checkin data is a string with multiple date times in it. You'll need to split that string before parsing. In [ ] # YOUR CODE HERE raise NotImplementedError() In [ ]: assert type (hours_by_checkin_count) == pyspark.sql.dataframe. DataFrame, "The hours_by_checkin_count variable should be a Spark DataFrame." assert hours_by_checkin_count.columns == ["hour", "count"], \ "The columns are not in the correct order." submitted = AutograderHelper.parse_spark_dataframe (hours_by_checkin_count) In [ ] #Autograder cell. This cell is worth 1 point (out of 20). This cell does not contain hidden tests. assert len (submitted) == 24, \ "The hours_by_checkin_count DataFrame must have 24 rows. assert submitted [ "hour"][0] == 1, \ 'The first row should have hour 1' In [ ] # Autograder cell. This cell is worth 4 points (out of 20). This cell contains hidden tests. Question 4 -- Common Words in Useful Reviews Write function that takes a Spark DataFrame as a parameter and returns a Spark DataFrame of the 50 most common words from useful reviews and their counts. • A "useful review" has 10 or more "useful" ratings. . Convert the text to lower case. • Use the provided splitter() function in a UDF to split the text into individual words. Exclude the words in the provided STOP WORDS set. Returned DataFrame should have these columns (in this order): ■ word . count • Returned DataFrame should be sorted by count in descending order. . } . In [ ] import re def splitter (text): WORD_RE= re.compile(r"[\w']+") return WORD_RE.findall(text) STOP WORDS = { a "about", "above", "after", "again", "against", "aint", "all", "also", "although", "am", "an", "and", "any", "are", "as", "at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "can", "check", "checked", "could", "did", "do", "does", "doing", "don", "down", "during", "each", "few", "for", "from", "further", "get", "go", "got", "had", "has", "have", "having", "he", "her", "here", "hers", "herself", "him", "himself", "his", "how", "however", "i", "i'd", "if", "i'm", "in", "into", "is", "it", "its", "it's", "itself", "i've", "just", "me", "more", "most", "my", "myself", "no", "nor", "not", "now", "of", "off", "on", "once", "one", "online", "only", "or", "other", "our", "ours", "ourselves", "out", "over", "own", "paid", "place", "s", "said", "same", "service", "she", "should", "so", "some", "such", "t", "than", "that", "the", "their", "theirs", "them", "themselves", "then", "there", "these", "they", "this", "those", "through", "to", "too", "under", "until", "up", "us", "very", "was", "we", "went", "were", "we've", "what", "when", "where", "which", "while", "who", "whom", "why", "will", "with", "would", "you", "your", "yours", "yourself", "yourselves", def common_useful_words (reviews, limit=50): #YOUR CODE HERE raise Not ImplementedError() return most common Now we'll run it on the review DataFrame In [ ]: common_useful_words_counts = common_useful_words (review) In [ ] assert type (common_useful_words_counts) == pyspark.sql.dataframe.DataFrame, \ "The common_useful_words_counts variable should be a Spark DataFrame." assert common_useful_words_counts.columns == ["word", "count"], \ "The columns are not in the correct order." submitted = AutograderHelper.parse_spark_dataframe (common_useful_words_counts) In [ ] # Autograder cell. This cell is worth 2 points (out of 20). This cell does not contain hidden tests. assert len (submitted) == 50, \ "The common_useful_words_counts DataFrame must have 50 rows." assert submitted [ "word"][0] == 'like', \ 'The first row should have word "like"" assert submitted [ "count"][0]==101251, \ 'The first row should have count 101251' In [ 1: # Autograder cell I This cell is worth 6 points out of 201 This cell contains hidden tests.
Expert Answer:
Answer rating: 100% (QA)
1Here is the code to determine how many users have received more than 5000 cool compliments PYTHON from pysparksql import SparkSession spark SparkSessionbuilderappNameCool ComplimentsgetOrCreate Load ... View the full answer

Related Book For 

Business Analytics Methods Models and Decisions
ISBN: 978-0321997821
2nd edition
Authors: James R. Evans
Posted Date:
Students also viewed these programming questions
-
The forces in (Figure 1) act on a 1.1 kg object. Part A What is the value of a, the z-component of the object's acceleration? Express your answer with the appropriate units. Figure 3.0 N' 4.0 N y 3.0...
-
Planning is one of the most important management functions in any business. A front office managers first step in planning should involve determine the departments goals. Planning also includes...
-
4. The period of Jupiters moon lo is 1.5 x 10's and has a radius of orbit of 4.2 x 108 m calculate the mass of Jupiter using this information (1.9 x 1027 kg) 5. A lunar lander is to be placed in...
-
Bruceton Farms Equipment Company had goodwill valued at $80 million on its balance sheet at year-end. A review of the goodwill by the company's CFO indicated that the goodwill was impaired and was...
-
Explain the relative risk of the various types of securities in which a money market fund may invest.
-
(a) Redo Exercise 9.25 taking into account the thermal expansion of the tungsten filament. You may assume a thermal expansion coefficient of 12 x 10 -6 /C. (b) By what percentage does your answer...
-
\(5,345,324\) Use divisibility rules to determine if each of the following is divisible by 3.
-
Big Sky Mining Company must install $1.5 million of new machinery in its Nevada mine. It can obtain a bank loan for 100 percent of the purchase price, or it can lease the machinery. Assume that the...
-
how do I calculate this?. Consider a two-period at-the money call option written on a $10 stock that can go up or down 10 percent each period when the risk-free rate is 5 percent. That is, At t=0,...
-
Determine the amount of total assets, current assets, and noncurrent assets at the end of the period, given the following data: Current liabilities, ending balance Current ratio, ending Owners...
-
Watch the Carl Rogers interviews with Gloria . In your initial discussion post, make note of examples you see (from Carl Rogers) of the following skills: Nonexpert language First-person quotes that...
-
University Road is best described as the interval [0,1]. Two fast-food restaurants serving identical food are located at the edges of the road, so that restaurant 1 is located on the most left-hand...
-
what is the original revenue of the producer (before taxes imposed) when original equilibrium equals $100, producer revenue after tax $87 and indirect tax $28
-
Laker Company reported the following January purchases and sales data for its only product. For specific identification, ending inventory consists of 290 units from the January 30 purchase, 5 units...
-
Your team is investigating several assumptions about your company's new production process. Question: What strategies can your team use to investigate each assumption thoroughly? Instruction: Choose...
-
How does a company really decide which investment method to apply?
-
If a customer earns the loyalty points for purchases at an entity that is not owned by the Company (i.e., franchisee hotel or company managed property), that entity remits some cash to the Company...
-
Eleni Cabinet Company sold 2,200 cabinets during 2011 at $160 per cabinet. Its beginning inventory on January 1 was 130 cabinets at $56. Purchases made during the year were as follows: February . 225...
-
A national homebuilder builds single family homes and condominium style townhouses. The Excel file House Sales provides information on the selling price, lot cost, type of home, and region of the...
-
Fuller Legal Services wants to determine how much time to allocate to four different services: business consulting, criminal work, nonprofit consulting, and wills/ trusts. Mr. Fuller has determined...
-
In an example in, we developed the following cross tabulation of sales transaction data: a. Find the marginal probabilities that a sale originated in each of the four regions and the marginal...
-
Distinguish between the face value and the issue price of a bond. When are they the same? When are they different? Explain.
-
Explain the impact on interest of a bond discount and bond premium to (a) the issuer and (b) the investor.
-
Assume that a \(\$ 1,000,8 \%\) (payable semiannually), 10 -year bond is sold at a market rate of \(6 \%\). Explain how to compute the price of this bond.

Study smarter with the SolutionInn App