

In Section 1 we introduced an example with two states and two actions in which the reward
Question:
In Section 1 we introduced an example with two states and two actions in which the reward function was \(r(A, 1)=4, r(B, 1)=3\), \(r(A, 2)=2, r(B, 2)=5\) and the transition matrices were as below. For a finite horizon stochastic dynamic programming problem with time horizon \(T=6\) and terminal reward \(R(A)=3, R(B)=5\), find the optimal policy.
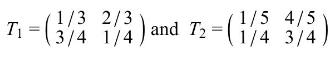
Fantastic news! We've Found the answer you've been seeking!
Step by Step Answer:

Answered By
CHARLES AMBILA
I am an experienced tutor with more than 7 years of experience. I have helped thousands of students pursue their academic goals. My primary objective as a tutor is to ensure that students have easy time handling their academic tasks.
109+ Reviews
324+ Question Solved
Related Book For 

Introduction To The Mathematics Of Operations Research With Mathematica
ISBN: 9781574446128
1st Edition
Authors: Kevin J Hastings
Question Posted:
