

Spam filters are built on principles similar to those used in logistic regression. We fit a probability
Question:
Spam filters are built on principles similar to those used in logistic regression. We fit a probability that each message is spam or not spam. We have several email variables for this problem: to multiple, cc, attach, dollar, winner, inherit, password, format, re subj, exclaim subj, and sent email. We won't describe what each variable means here for the sake of brevity, but .each is either a numerical or indicator variable.
(a) For variable selection, we fit the full model, which includes all variables, and then we also fit each model where we've dropped exactly one of the variables. In each of these reduced models, the AIC value for the model is reported below. Based on these results, which variable, if any, should we drop as part of model selection? Explain.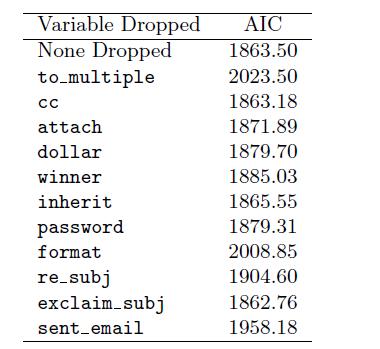
(b) Consider the following model selection stage. Here again we've computed the AIC for each leave-one- variable-out model. Based on the results, which variable, if any, should we drop as part of model selection? Explain.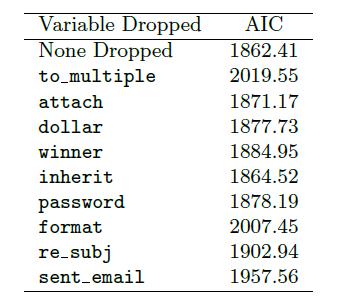
Step by Step Answer:
In both stages of model selection we are trying to determine which variable if any should be dropped ...View the full answer



OpenIntro Statistics
ISBN: 9781943450077
4th Edition
Authors: David Diez, Mine Çetinkaya-Rundel, Christopher Barr
