

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
(0) Please do this in Python! 1. You will simulate round robin sort and shortest remaining job process scheduling algorithms. You will be able to
(0)


Please do this in Python!
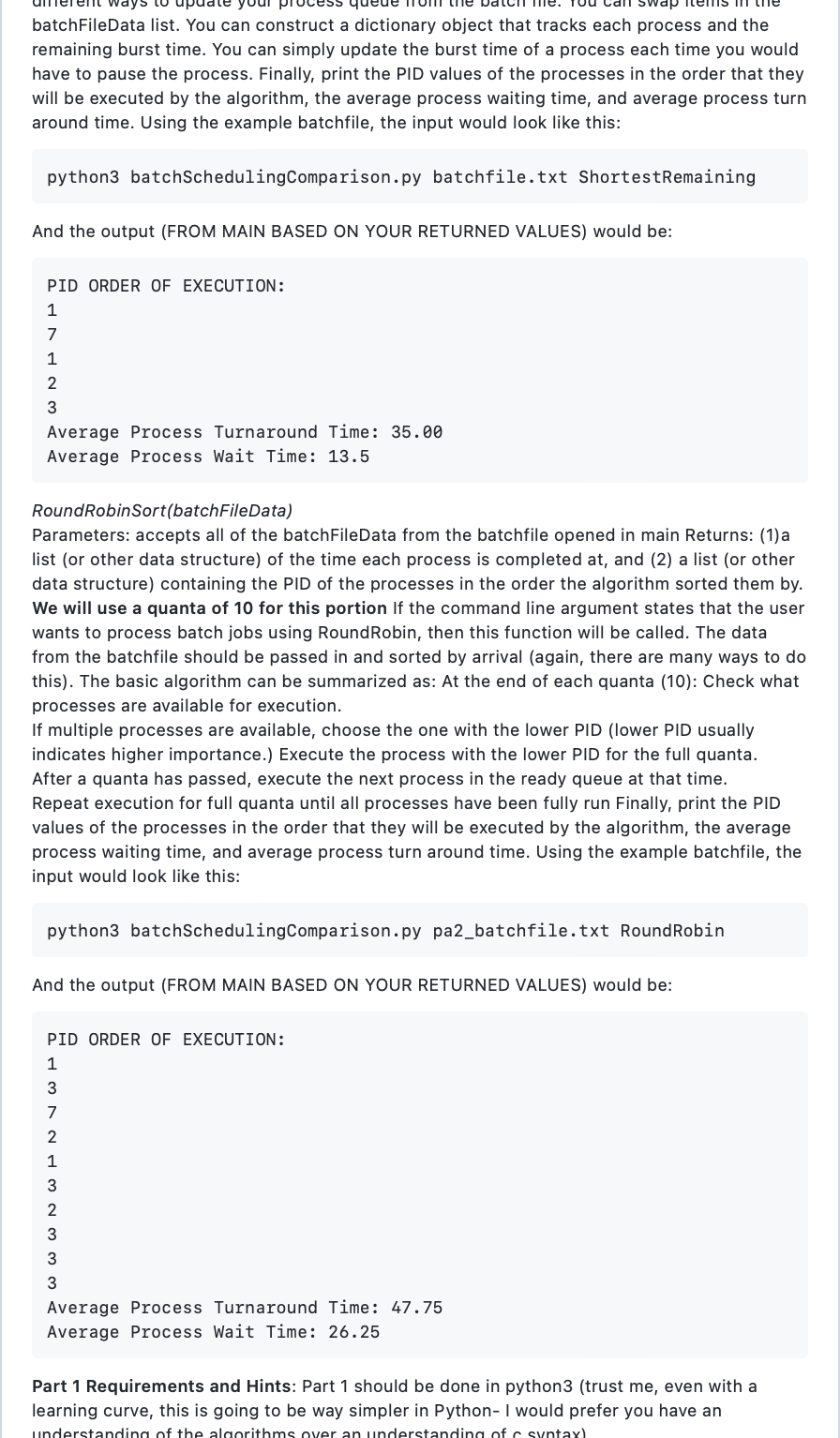
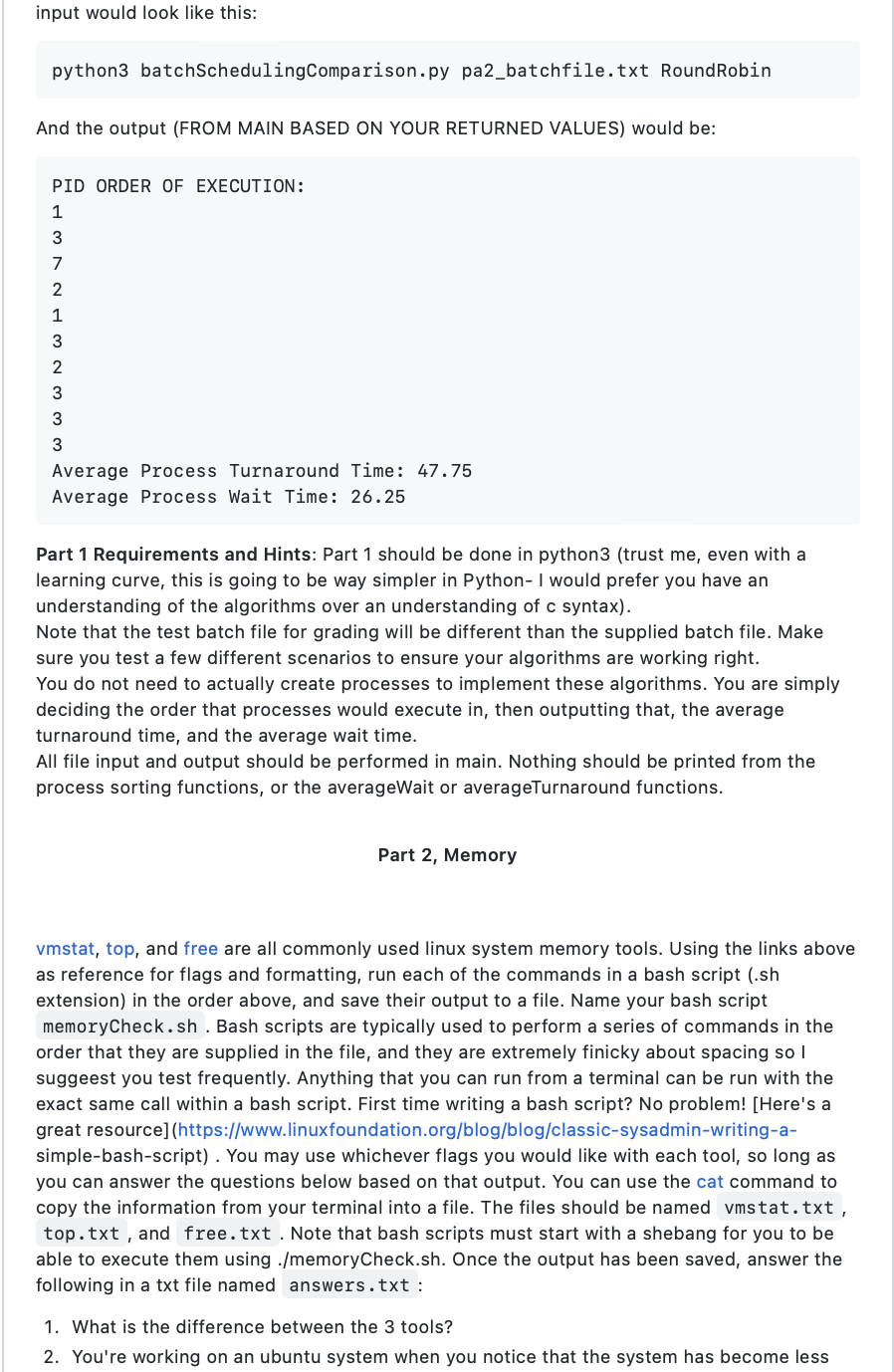
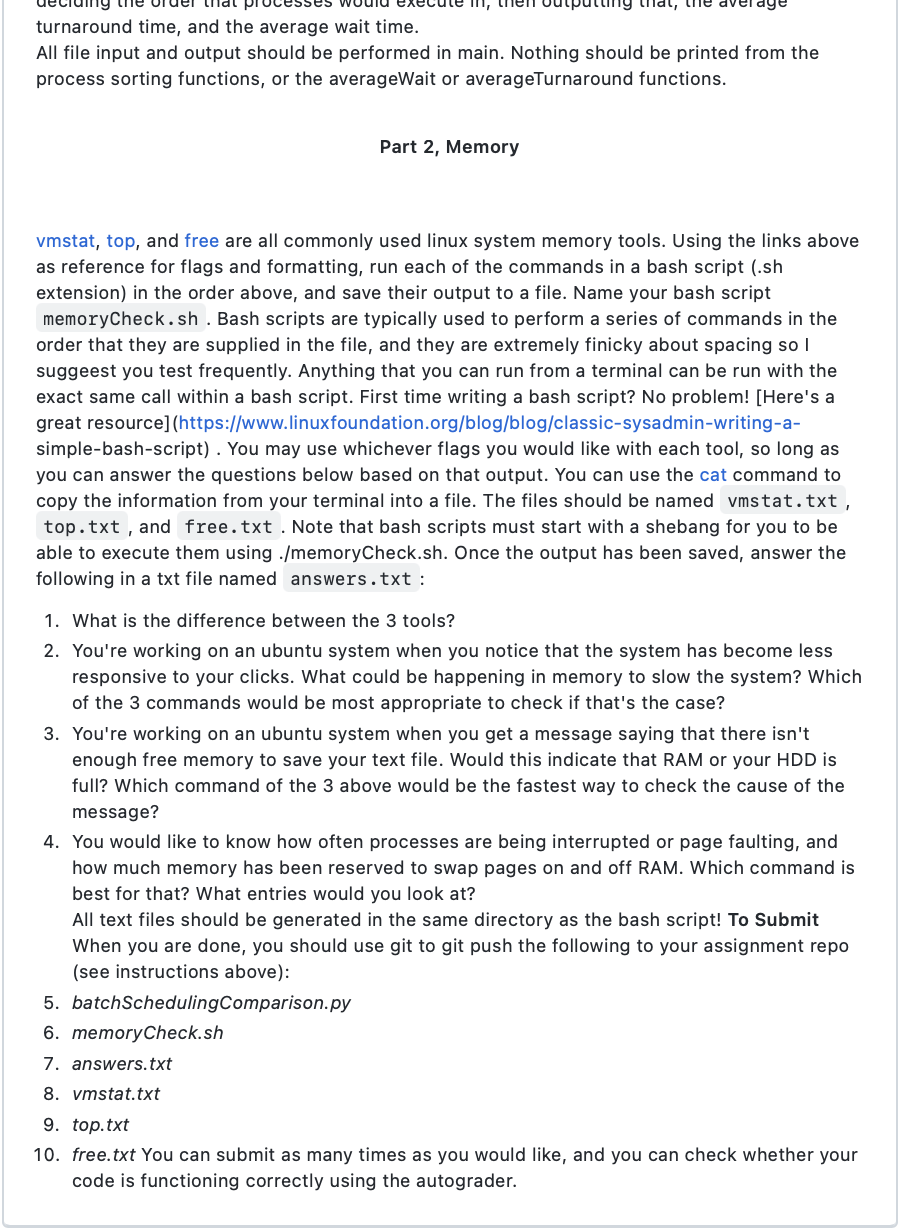
1. You will simulate round robin sort and shortest remaining job process scheduling algorithms. You will be able to compare and contrast the ease of implementation and the effect on turnaround and wait times. 2. You will learn to examine an existing operating system's memory usage General Instructions and Hints: -Name files exactly as described in the documentation below. -All functions should match the assignment descriptions. Do not add parameters, change names, or return different values. -All output should match exactly what is in this document (including spacing!). If it does not match, it will not pass the autograder. -When part 1 is done, open a terminal and cd to your github repo, wherever you saved it. Do the following: git add . then git commit - m then git push. -All work should be your own. -You may use the following libraries for part 1 (though you do not have to use any other than sys): numpy pandasunders sys Part 1, Process Scheduling Background Process scheduling algorithms come in many different variations, and they have many different tradeoffs to consider like resource sharing and simplicity of execution. Understanding how Shortest Remaining Job, and Round Robin Scheduling work will give you a better understanding of the ways in which these algorithms differ. Waiting time measures the amount of time from when a process enters the ready queue to when the process is executed. Turn around time measures the amount of time from when a process enters the ready queue to when the process is terminated. The are both used in operating systems to determine CPU usage efficiency. Directions The code for this portion should be written in Python (trust me, it's easier than C). There is a test batchfile for this assignment located in the repo. Each line of the batchfile contains 4 comma separated values. They are: PID, Arrival Time, Burst Time (also known as execution time). PID is the process id. Arrival time is the time since the process arrived in the ready queue. Burst time is the amount of time required to fully execute the process on the CPU. Let's look at a simplified example of the batchfile: 1,3,7,2,0,0,9,10,2050412 Your program should consist of 4 functions: Main, ShortestRemainingSort, RoundRobinSort, ComputeStat. Please note that the way Python implements main is different than the way that C or C++ implements it. Below, I provide the general description of each of the functions. You will notice that these descriptions are much less comprehensive than the first assignment. This is because I would like you to begin working on implementing algorithms from a general description (much like you would in an interview). Name your program batchSchedulingComparison.py You can implement sorting in many ways in Python: you can take your data and create a tuple (or other object) and sort a list of those objects, you can zip, sort and unzip lists, you can create parallel lists and sort (not recommended since mistakes with this method are common), etc. In each of the sort functions, it is up to you to decide what data structures and process you use to implement the sorting algorithm. If you want to create a list of dict objects containing each of the variables and sort by key or item, that's fine. Or you could create three separate lists (one for PID, one for arrival time, and one for burst time) and sort them using zip/unzip. There are many ways to sort in python, so pick whatever makes the most sense to you. main() From the terminal, the user should be able to enter the program name batchfile Name and type of process sort they would like to do. So for example: python 3 batchSchedulingComparison.py pa2_batchfile.txt RoundRobin could be entered on the commandline when you want to run the program. If the user does not enter your three main() From the terminal, the user should be able to enter the program name batchfile Name and type of process sort they would like to do. So for example: python 3 batchSchedulingComparison.py pa2_batchfile.txt RoundRobin could be entered on the commandline when you want to run the program. If the user does not enter your three arguments (program name batchfileName and sortType), then you should return 1 for failure and print the following: Please provide command line arguments when running. python 3 batchSchedulingComparison.py batchfile.txt ShortestRemaining There are many ways to accomplish this check. You will likely want to import sys and use sys.argv to get all of the arguments given from the command line. Once the user supplies the correct number of arguments (which you can get by taking the length of the sys.argv list, see [here](https://www.geeksforgeeks.org/command- line-arguments-in-c-cpp/)), use argv to get the batch file name, and then read all of the data from it, if you can. If you can't (because the user entered a non-existent file name), you should return 1 , and print the following: Input batchfile not found! If you're able to read from the file name provided by the user (again there are many ways to do this, but I like using readlines()), then you should get the algorithm name from the argv list. Expected algorithm names supplied by the user are and ShortestRemaining and RoundRobin (with that exact spelling and capitalization). If the user does not provide one of these arguments, you should return 1 and output the following: Unidentified sorting algorithm. Please input either ShortestRemaining or RoundRobin. If the user enters an acceptable algorithm name, perform a logical check to see which function you should call ( ShortestRemaining or RoundRobin). Call the appropriate algorithm, which returns a list of process execution times and sorted (by algorithm) PIDs. Call ComputeStats to get the average wait time and average turnaround time. For each algorithm, the output to the terminal should be the processes in the order that they should execute (each on their own line), the average process waiting time, and the average process turn around time, each on their own line. All input and output should be gathered and executed IN MAIN. In other words, your reading and printing should happen there. Examples of output for each algorithm are below, but please make sure that you print from main. The easiest way to do that is to have each of the algorithm functions return a list of the times that each process is completed at. Then you can pass that and the relevant data to ComputeStats, whose returns can be used to print the turnaround and wait times. ComputeStat(processCompletionTimes, processArrivalTimes, processBurstTimes) Parameters: accepts the time that the process would be completed at by the algorithm, accepts the time that each process arrives (I suggest using two lists) Returns: (1)the average turnaround, (2)a list of each process turnaround times, (3)the average wait time and (4)a list of each process wait times (note: Python will let you return multiple values at once. For ease of implementation, you should do that in this function) This function calculates your average turnaround time and average wait time stats, as well as the turnaround and wait time for each process (as lists). Turnaround time is calculated by subtracting each processArrivalTime from its final processCompletionTime. For example, using FCFS process 3 takes 50 seconds to execute and arrived at time 0, so process 3 has a turnaround time of 70 because it has to wait 20 seconds for process 1 to fully execute. To calculate the average, sum each process' turnaround time, and divide by the number of processes. So if we only executed process 1 and 3 , we would add 20 and 70 and divide by 2 - the turnaround time of those two processes averaged (ignoring 20 and 70 and divide by 2 - the turnaround time of those two processes averaged (ignoring the rest of the list for simplicity) is 45 . Wait time is calculated by subtracting each processBurstTime from its processTurnaroundTime. For example, using FCFS, we previously calculated that process 3 has a turnaround time of 70 , and process 1 has a turnaround time of 20. To calculate the waitTime for process 3 , we subtract the burst time from the turnaround (70-50) and get 20; doing the same for process 1 , we get 0 . To calculate the average, sum each process' wait time, and divide by the number of processes. So if we only executed process 1 and 3 , we would add 20 and 0 , and divide by 2 - the wait time of those two processes averaged (ignoring the rest of the list for simplicity) is 10. ShortestRemainingSort(batchFileData) Parameters: accepts all of the batchFileData from the batchfile opened in main Returns: (1) a list (or other data structure) of the time each process is completed at, and (2) a list (or other data structure) containing the PID of the processes in the order the algorithm sorted them by. If the command line argument states that the user wants to process batch jobs using ShortestRemaining, then this function will be called. The data from the batchfile should be passed in and sorted by arrival time (again, there are many ways to do this). For this version of shortest remaining, as processes arrive, they are added to the queue. If the burst time of the newest process in the queue is less than the remaining time to execute the current process, the current process should be added back to the queue and the new process should be executed. So in the batchfile above, process 1 and 3 arrive at the same time, but process 1 has a burst time of 20 seconds, so we run process 1 . At time =9, process 7 enters the queue. Process 1 has 11 seconds of execution remaining. Process 7 has a burst time of 4 . Therefore, we will pause process 1 , save its new burst time (which is the remaining time), and execute process 7 . At time 10, process 2 enters the queue. The current process, PID 7, has 3 seconds remaining until full execution, while process 2 needs 12 seconds to fully execute. Therefore, we continue to execute PID 7 until it completes, and check the queue for the process with the shortest remaining burst time- in this case, we would run PID 1 until it is fully executed, then PID 2, then PID 3. This would complete the batch file's process scheduling algorithm. The basic algorithm can be summarized as: At each time (think for loop) Check what processes have arrived in the queue. Compare the arrived process' burst time to the time that remains for the current process to fully execute. If the newest process has a shorter burst time than the remaining time on the current process, update the burst time for the current process to be the remaining time. Then execute the new process with the shorter burst time. Otherwise, continue executing the current process and decrement its remaining time. If two processes arrive at the same time and have the same burst time, execute the process with the smaller PID first The simplest way to check "at each time" is to sort all of the processes by arrival time, but there are a multitude of ways to simulate ShortestRemaining. There are many different ways to update your process queue from the batch file. You can swap items in the batchFileData list. You can construct a dictionary object that tracks each process and the remaining burst time. You can simply update the burst time of a process each time you would have to pause the process. Finally, print the PID values of the processes in the order that they will be executed by the algorithm, the average process waiting time, and average process turn around time. Using the example batchfile, the input would look like this: python 3 batchSchedulingComparison.py batchfile.txt ShortestRemaining batchFileData list. You can construct a dictionary object that tracks each process and the remaining burst time. You can simply update the burst time of a process each time you would have to pause the process. Finally, print the PID values of the processes in the order that they will be executed by the algorithm, the average process waiting time, and average process turn around time. Using the example batchfile, the input would look like this: python3 batchSchedulingComparison.py batchfile.txt ShortestRemaining And the output (FROM MAIN BASED ON YOUR RETURNED VALUES) would be: PID ORDER OF EXECUTION: 1 7 1 2 3 Average Process Turnaround Time: 35.00 Average Process Wait Time: 13.5 RoundRobinSort(batchFileData) Parameters: accepts all of the batchFileData from the batchfile opened in main Returns: (1)a list (or other data structure) of the time each process is completed at, and (2) a list (or other data structure) containing the PID of the processes in the order the algorithm sorted them by. We will use a quanta of 10 for this portion If the command line argument states that the user wants to process batch jobs using RoundRobin, then this function will be called. The data from the batchfile should be passed in and sorted by arrival (again, there are many ways to do this). The basic algorithm can be summarized as: At the end of each quanta (10): Check what processes are available for execution. If multiple processes are available, choose the one with the lower PID (lower PID usually indicates higher importance.) Execute the process with the lower PID for the full quanta. After a quanta has passed, execute the next process in the ready queue at that time. Repeat execution for full quanta until all processes have been fully run Finally, print the PID values of the processes in the order that they will be executed by the algorithm, the average process waiting time, and average process turn around time. Using the example batchfile, the input would look like this: python3 batchSchedulingComparison.py pa2_batchfile.txt RoundRobin And the output (FROM MAIN BASED ON YOUR RETURNED VALUES) would be: Part 1 Requirements and Hints: Part 1 should be done in python3 (trust me, even with a learning curve, this is going to be way simpler in Python-I would prefer you have an input would look like this: python3 batchSchedulingComparison.py pa2_batchfile.txt RoundRobin And the output (FROM MAIN BASED ON YOUR RETURNED VALUES) would be: PID ORDER OF EXECUTION: 1 3 7 2 1 3 2 3 3 3 Average Process Turnaround Time: 47.75 Average Process Wait Time: 26.25 Part 1 Requirements and Hints: Part 1 should be done in python 3 (trust me, even with a learning curve, this is going to be way simpler in Python- I would prefer you have an understanding of the algorithms over an understanding of c syntax). Note that the test batch file for grading will be different than the supplied batch file. Make sure you test a few different scenarios to ensure your algorithms are working right. You do not need to actually create processes to implement these algorithms. You are simply deciding the order that processes would execute in, then outputting that, the average turnaround time, and the average wait time. All file input and output should be performed in main. Nothing should be printed from the process sorting functions, or the averageWait or averageTurnaround functions. Part 2, Memory vmstat, top, and free are all commonly used linux system memory tools. Using the links above as reference for flags and formatting, run each of the commands in a bash script (.sh extension) in the order above, and save their output to a file. Name your bash script memoryCheck.sh. Bash scripts are typically used to perform a series of commands in the order that they are supplied in the file, and they are extremely finicky about spacing so I suggeest you test frequently. Anything that you can run from a terminal can be run with the exact same call within a bash script. First time writing a bash script? No problem! [Here's a great resource] (https://www.linuxfoundation.org/blog/blog/classic-sysadmin-writing-asimple-bash-script) . You may use whichever flags you would like with each tool, so long as you can answer the questions below based on that output. You can use the cat command to copy the information from your terminal into a file. The files should be named vmstat.txt, top.txt, and free.txt. Note that bash scripts must start with a shebang for you to be able to execute them using ./memoryCheck.sh. Once the output has been saved, answer the following in a txt file named answers.txt : 1. What is the difference between the 3 tools? 2. You're working on an ubuntu system when you notice that the system has become less turnaround time, and the average wait time. All file input and output should be performed in main. Nothing should be printed from the process sorting functions, or the averageWait or averageTurnaround functions. Part 2, Memory vmstat, top, and free are all commonly used linux system memory tools. Using the links above as reference for flags and formatting, run each of the commands in a bash script (.sh extension) in the order above, and save their output to a file. Name your bash script memoryCheck. sh. Bash scripts are typically used to perform a series of commands in the order that they are supplied in the file, and they are extremely finicky about spacing so I suggeest you test frequently. Anything that you can run from a terminal can be run with the exact same call within a bash script. First time writing a bash script? No problem! [Here's a great resource](https://www.linuxfoundation.org/blog/blog/classic-sysadmin-writing-asimple-bash-script) . You may use whichever flags you would like with each tool, so long as you can answer the questions below based on that output. You can use the cat command to copy the information from your terminal into a file. The files should be named vmstat.txt, top.txt, and free.txt. Note that bash scripts must start with a shebang for you to be able to execute them using ./memoryCheck.sh. Once the output has been saved, answer the following in a txt file named answers.txt : 1. What is the difference between the 3 tools? 2. You're working on an ubuntu system when you notice that the system has become less responsive to your clicks. What could be happening in memory to slow the system? Which of the 3 commands would be most appropriate to check if that's the case? 3. You're working on an ubuntu system when you get a message saying that there isn't enough free memory to save your text file. Would this indicate that RAM or your HDD is full? Which command of the 3 above would be the fastest way to check the cause of the message? 4. You would like to know how often processes are being interrupted or page faulting, and how much memory has been reserved to swap pages on and off RAM. Which command is best for that? What entries would you look at? All text files should be generated in the same directory as the bash script! To Submit When you are done, you should use git to git push the following to your assignment repo (see instructions above): 5. batchSchedulingComparison.py 6. memoryCheck.sh 7. answers.txt 8. vmstat.txt 9. top.txt 10. free.txt You can submit as many times as you would like, and you can check whether your code is functioning correctly using the autograderStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Advances In Databases 28th British National Conference On Databases Bncod 28 Manchester Uk July 2011 Revised Selected Papers Lncs 7051
Authors: Alvaro A.A. Fernandes ,Alasdair J.G. Gray ,Khalid Belhajjame
2011th Edition
3642245765, 978-3642245763