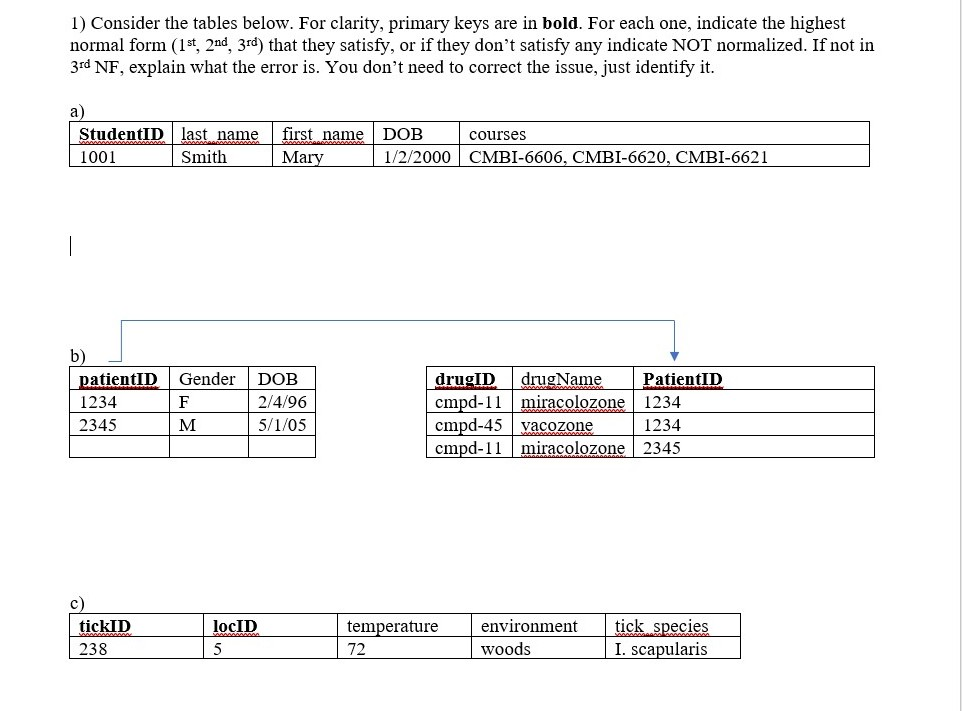

1) Consider the tables below. For clarity, primary keys are in bold. For each one, indicate the highest normal form (1st, 2nd, 3rd) that they satisfy, or if they don't satisfy any indicate NOT normalized. If not in 3rd NF, explain what the error is. You don't need to correct the issue, just identify it StudentID last name first name |DOB 1001 courses Smith Ma 1/2/2000 CMBI-6606, CMBI-6620, CMBI-6621 atientID |Gender DOB 1234 2345 drugID drugName cmpd-1 miracolozone 1234 cmpd-45 vacozone cmpd-1miracolozone 2345 PatientID 2/4/96 5/1/05 1234 tickID 238 environmenttick species woods locID temperature 72 I. scapularis 2) Design a database, creating an EER diagram in MySQL Workbench. As a hint, this design as described does NOT require sub-types. This is our first attempt to design a database from just a written description, so the number of attributes has been limited. Over time we will revisit this design and add complexity, including sub-types For the ER diagram clearly indicate primary keys, foreign keys and relationships, including cardinality (i.e. 1-to-many). Add key fields as needed. We have not discussed data type in detail but try select the most appropriate data type based on the description and/or examples below The database will store data about samples sequenced using Next-gen sequencing technology Specifically, it will store data about samples and the sequencing runs As a little background, a sample can be genomic DNA (gDNA) or RNA (cDNA). Each sample is bound to a glass slide-like structure called a flow cell, and a flow cell is then sequenced on an instrument. A single flow cell can hold many samples, but a given flowcell can only be sequenced once (then it's discarded). A sample can be sequenced multiple times on different flow cells. We usually refer to the sequencing of a particular flowcell on a specific instrument as a sequencing run Attributes to store: . sample description (name assigned by the client), i.e. sample XYZ-1 e sample mean Q (Quality) score, i.e. 33.8; this will likely vary if sequenced again e sample percent bases with Q greater than 30, i.e. 86.2; this will likely vary if sequenced again . sample type: will be gDNA, RNA or unknown . date sample collected flow cell ID, i.e. C5Y9JACXX. (These names are assigned by the manufacturer and are unique) instrument serial number, i.e. SN334 instrument model name, ie. MSSA, HSeq2500 number of clusters on flow cell (this is the number of DNA fragments; whole number, may be > 109 * . Number of clusters passing filter (usually ~90 % of number of clusters) instrument analysis software version (i.e. 1.18.61); this will be updated from time to time, we should know what version was in effect for each sequencing run. date sequencing run completed sequencing OK (this is a Boolean (True or False) flag to indicate if the data for a particular sample, run on a particular flow cell, is ok to report; next-gen technology doesn't always give usable results) e 1) Consider the tables below. For clarity, primary keys are in bold. For each one, indicate the highest normal form (1st, 2nd, 3rd) that they satisfy, or if they don't satisfy any indicate NOT normalized. If not in 3rd NF, explain what the error is. You don't need to correct the issue, just identify it StudentID last name first name |DOB 1001 courses Smith Ma 1/2/2000 CMBI-6606, CMBI-6620, CMBI-6621 atientID |Gender DOB 1234 2345 drugID drugName cmpd-1 miracolozone 1234 cmpd-45 vacozone cmpd-1miracolozone 2345 PatientID 2/4/96 5/1/05 1234 tickID 238 environmenttick species woods locID temperature 72 I. scapularis 2) Design a database, creating an EER diagram in MySQL Workbench. As a hint, this design as described does NOT require sub-types. This is our first attempt to design a database from just a written description, so the number of attributes has been limited. Over time we will revisit this design and add complexity, including sub-types For the ER diagram clearly indicate primary keys, foreign keys and relationships, including cardinality (i.e. 1-to-many). Add key fields as needed. We have not discussed data type in detail but try select the most appropriate data type based on the description and/or examples below The database will store data about samples sequenced using Next-gen sequencing technology Specifically, it will store data about samples and the sequencing runs As a little background, a sample can be genomic DNA (gDNA) or RNA (cDNA). Each sample is bound to a glass slide-like structure called a flow cell, and a flow cell is then sequenced on an instrument. A single flow cell can hold many samples, but a given flowcell can only be sequenced once (then it's discarded). A sample can be sequenced multiple times on different flow cells. We usually refer to the sequencing of a particular flowcell on a specific instrument as a sequencing run Attributes to store: . sample description (name assigned by the client), i.e. sample XYZ-1 e sample mean Q (Quality) score, i.e. 33.8; this will likely vary if sequenced again e sample percent bases with Q greater than 30, i.e. 86.2; this will likely vary if sequenced again . sample type: will be gDNA, RNA or unknown . date sample collected flow cell ID, i.e. C5Y9JACXX. (These names are assigned by the manufacturer and are unique) instrument serial number, i.e. SN334 instrument model name, ie. MSSA, HSeq2500 number of clusters on flow cell (this is the number of DNA fragments; whole number, may be > 109 * . Number of clusters passing filter (usually ~90 % of number of clusters) instrument analysis software version (i.e. 1.18.61); this will be updated from time to time, we should know what version was in effect for each sequencing run. date sequencing run completed sequencing OK (this is a Boolean (True or False) flag to indicate if the data for a particular sample, run on a particular flow cell, is ok to report; next-gen technology doesn't always give usable results) e




