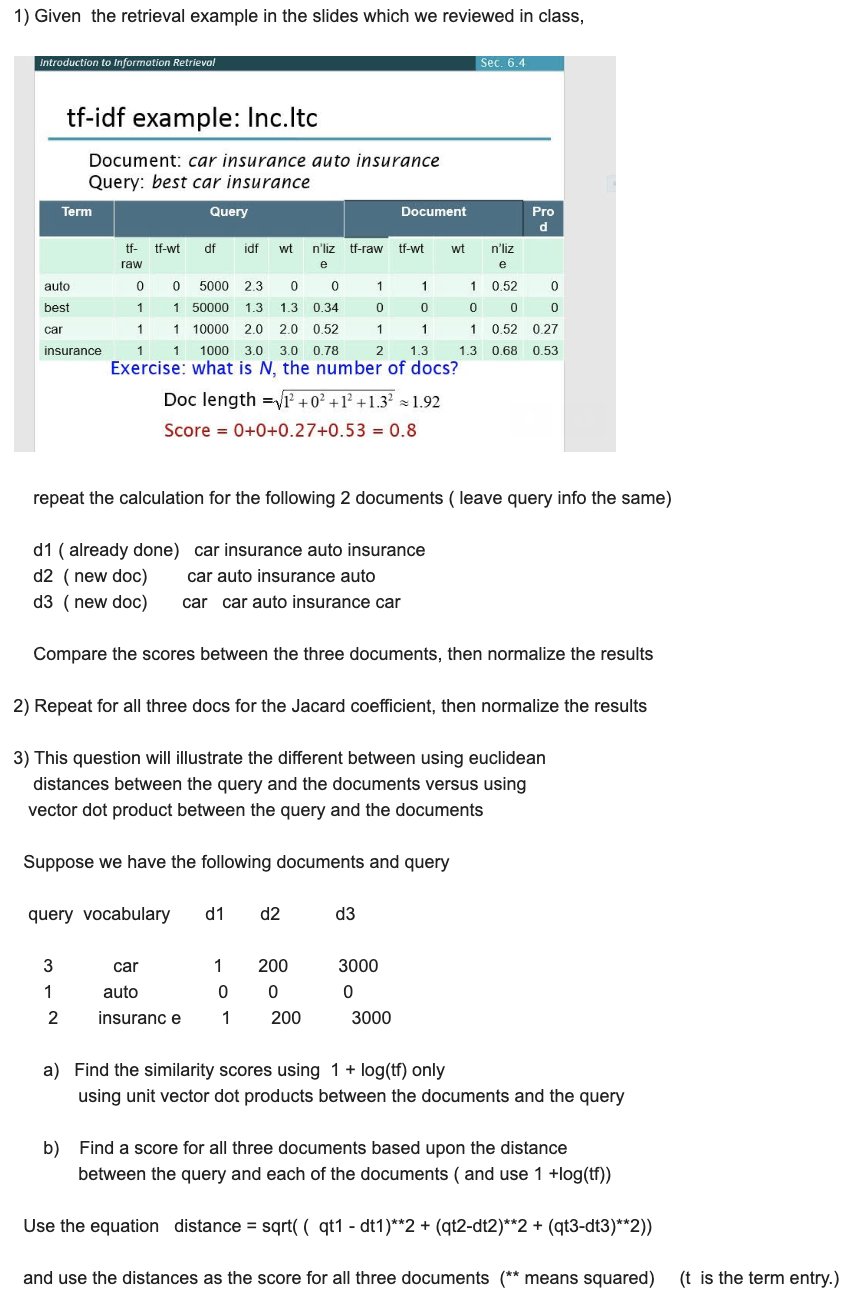
1) Given the retrieval example in the slides which we reviewed in class, Introduction to Information Retrieval Sec. 6.4 tf-idf example: Inc.ltc Document: car insurance auto insurance Query: best car insurance Term Query Document Pro d tf- tf-wt df idf wt n'liz tf-raw tf-wt wt n'liz raw auto 0 0 5000 23 0 0 1 1 1 0.520 best 1 1 50000 1.3 1.3 0.34 0 0 0 0 0 car 1 1 10000 2.0 2.0 0.52 1 1 1 0.52 0.27 insurance 1 1 1000 3.0 3.0 0.78 2 1.3 1.3 0.68 0.53 Exercise: what is N, the number of docs? Doc length =v1 +0 +1 +1.32 1.92 Score = 0+0+0.27+0.53 = 0.8 repeat the calculation for the following 2 documents ( leave query info the same) d1 ( already done) car insurance auto insurance d2 (new doc) car auto insurance auto d3 (new doc) car car auto insurance car Compare the scores between the three documents, then normalize the results 2) Repeat for all three docs for the Jacard coefficient, then normalize the results 3) This question will illustrate the different between using euclidean distances between the query and the documents versus using vector dot product between the query and the documents Suppose we have the following documents and query query vocabulary d1d2 d 3 3 1 2 car auto insurance 1 0 1 200 0 200 3000 0 3000 a) Find the similarity scores using 1 + log(tf) only using unit vector dot products between the documents and the query b) Find a score for all three documents based upon the distance between the query and each of the documents ( and use 1 +log(t)) Use the equation distance = sqrt(( qt1 - dt1)** 2 + (qt2-dt2)**2 + (qt3-dt3)**2)) and use the distances as the score for all three documents (** means squared) (t is the term entry.) 1) Given the retrieval example in the slides which we reviewed in class, Introduction to Information Retrieval Sec. 6.4 tf-idf example: Inc.ltc Document: car insurance auto insurance Query: best car insurance Term Query Document Pro d tf- tf-wt df idf wt n'liz tf-raw tf-wt wt n'liz raw auto 0 0 5000 23 0 0 1 1 1 0.520 best 1 1 50000 1.3 1.3 0.34 0 0 0 0 0 car 1 1 10000 2.0 2.0 0.52 1 1 1 0.52 0.27 insurance 1 1 1000 3.0 3.0 0.78 2 1.3 1.3 0.68 0.53 Exercise: what is N, the number of docs? Doc length =v1 +0 +1 +1.32 1.92 Score = 0+0+0.27+0.53 = 0.8 repeat the calculation for the following 2 documents ( leave query info the same) d1 ( already done) car insurance auto insurance d2 (new doc) car auto insurance auto d3 (new doc) car car auto insurance car Compare the scores between the three documents, then normalize the results 2) Repeat for all three docs for the Jacard coefficient, then normalize the results 3) This question will illustrate the different between using euclidean distances between the query and the documents versus using vector dot product between the query and the documents Suppose we have the following documents and query query vocabulary d1d2 d 3 3 1 2 car auto insurance 1 0 1 200 0 200 3000 0 3000 a) Find the similarity scores using 1 + log(tf) only using unit vector dot products between the documents and the query b) Find a score for all three documents based upon the distance between the query and each of the documents ( and use 1 +log(t)) Use the equation distance = sqrt(( qt1 - dt1)** 2 + (qt2-dt2)**2 + (qt3-dt3)**2)) and use the distances as the score for all three documents (** means squared) (t is the term entry.)




