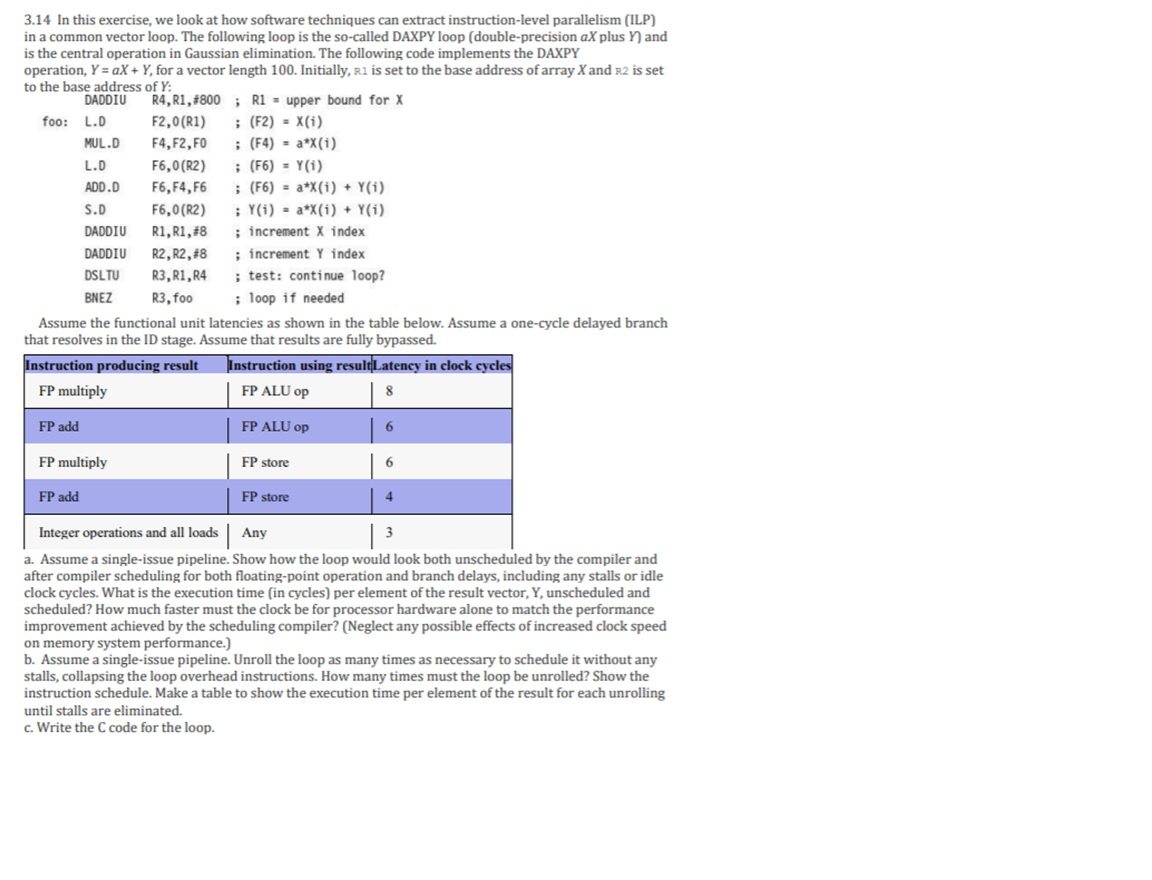
3.14 In this exercise, we look at how software techniques can extract instruction-level parallelism (ILP) in a common vector loop. The following loop is the so-called DAXPY loop (double-precision ax plus and is the central operation in Gaussian elimination. The following code implements the DAXPY operation, Y = AX + Y, for a vector length 100. Initially, Ri is set to the base address of array X and R2 is set to the base address of Y: DADDIU R4, R1, 4800; Ri - upper bound for X foo: L.D F2,0(R1) (F2) - X(i) MUL.D F4,F2,FO (F4) = a*X(i) L.D F6,0(R2) ; (F6) = Y(i) ADD.D F6,F4,F6 ; (F6) = a*X(i) + y(i) S. D F 6,0(R2) ; Y(i) = a*X(i) + y(i) DADDIU R1, R1,#8 ; increment X index DADDIU R2, R2,48 ; increment Y index DSLTU R 3, R1, R4 ; test: continue loop? BNEZ R3, foo ; loop if needed Assume the functional unit latencies as shown in the table below. Assume a one-cycle delayed branch that resolves in the ID stage. Assume that results are fully bypassed. Instruction producing result Instruction using result Latency in clock cycles FP multiply FP ALU op | 8 FP add FP ALU Op 6 FP multiply FP store | 6 FP add FP store Integer operations and all loads Any | 3 a. Assume a single-issue pipeline. Show how the loop would look both unscheduled by the compiler and after compiler scheduling for both floating-point operation and branch delays, including any stalls or idle clock cycles. What is the execution time (in cycles) per element of the result vector, Y, unscheduled and scheduled? How much faster must the clock be for processor hardware alone to match the performance improvement achieved by the scheduling compiler? (Neglect any possible effects of increased clock speed on memory system performance.) b. Assume a single-issue pipeline. Unroll the loop as many times as necessary to schedule it without any stalls, collapsing the loop overhead instructions. How many times must the loop be unrolled? Show the instruction schedule. Make a table to show the execution time per element of the result for each unrolling until stalls are eliminated. c. Write the C code for the loop. 3.14 In this exercise, we look at how software techniques can extract instruction-level parallelism (ILP) in a common vector loop. The following loop is the so-called DAXPY loop (double-precision ax plus and is the central operation in Gaussian elimination. The following code implements the DAXPY operation, Y = AX + Y, for a vector length 100. Initially, Ri is set to the base address of array X and R2 is set to the base address of Y: DADDIU R4, R1, 4800; Ri - upper bound for X foo: L.D F2,0(R1) (F2) - X(i) MUL.D F4,F2,FO (F4) = a*X(i) L.D F6,0(R2) ; (F6) = Y(i) ADD.D F6,F4,F6 ; (F6) = a*X(i) + y(i) S. D F 6,0(R2) ; Y(i) = a*X(i) + y(i) DADDIU R1, R1,#8 ; increment X index DADDIU R2, R2,48 ; increment Y index DSLTU R 3, R1, R4 ; test: continue loop? BNEZ R3, foo ; loop if needed Assume the functional unit latencies as shown in the table below. Assume a one-cycle delayed branch that resolves in the ID stage. Assume that results are fully bypassed. Instruction producing result Instruction using result Latency in clock cycles FP multiply FP ALU op | 8 FP add FP ALU Op 6 FP multiply FP store | 6 FP add FP store Integer operations and all loads Any | 3 a. Assume a single-issue pipeline. Show how the loop would look both unscheduled by the compiler and after compiler scheduling for both floating-point operation and branch delays, including any stalls or idle clock cycles. What is the execution time (in cycles) per element of the result vector, Y, unscheduled and scheduled? How much faster must the clock be for processor hardware alone to match the performance improvement achieved by the scheduling compiler? (Neglect any possible effects of increased clock speed on memory system performance.) b. Assume a single-issue pipeline. Unroll the loop as many times as necessary to schedule it without any stalls, collapsing the loop overhead instructions. How many times must the loop be unrolled? Show the instruction schedule. Make a table to show the execution time per element of the result for each unrolling until stalls are eliminated. c. Write the C code for the loop




