

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
5. [Marks 5] See the following code. Tell which part will be executed on the master and which will run on each worker node?
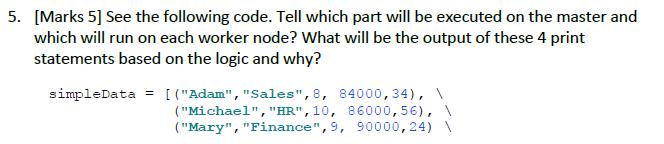
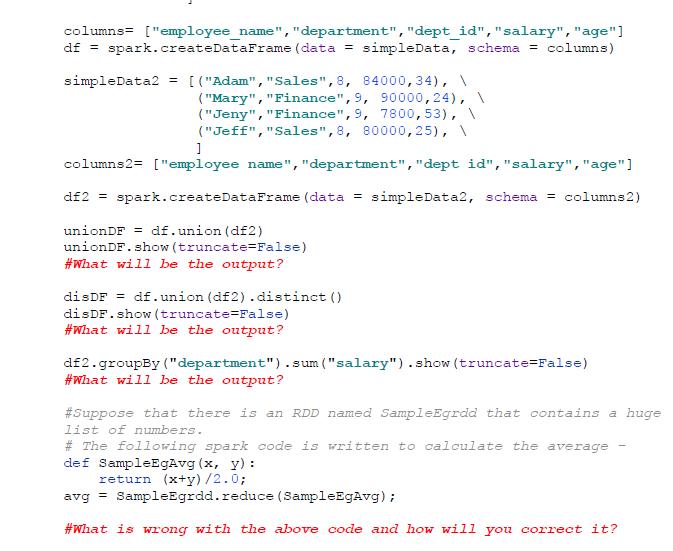
5. [Marks 5] See the following code. Tell which part will be executed on the master and which will run on each worker node? What will be the output of these 4 print statements based on the logic and why? simpleData = [("Adam", "Sales", 8, 84000, 34), \ ("Michael", "HR", 10, 86000,56), \ ("Mary", "Finance", 9, 90000,24) columns["employee_name", "department", "dept_id", "salary", "age"] df = spark.createDataFrame (data = simpleData, schema = columns) simpleData2 = [("Adam", "Sales", 8, 84000,34), \ ] ("Mary", "Finance", 9, 90000,24), \ ("Jeny", "Finance", 9, 7800,53), ("Jeff", "Sales", 8, 80000,25), columns2= ["employee name", "department", "dept id", "salary","age"] df2 spark.createDataFrame (data = simpleData2, schema = columns2) unionDF df.union (df2) unionDF. show (truncate=False) #What will be the output? disDF = df.union (df2).distinct () disDF.show (truncate=False) #What will be the output? df2.groupBy("department").sum ("salary").show (truncate=False) #What will be the output? #Suppose that there is an RDD named SampleEgrdd that contains a huge list of numbers.. # The following spark code is written to calculate the average def SampleEgAvg (x, y): return (x+y)/2.0; avg = SampleEgrdd. reduce (SampleEgAvg); #What is wrong with the above code and how will you correct it?
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Income Tax Fundamentals 2013
Authors: Gerald E. Whittenburg, Martha Altus Buller, Steven L Gill
31st Edition
1111972516, 978-1285586618, 1285586611, 978-1285613109, 978-1111972516