

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
A - 3 . [ 1 0 marks: 2 . 5 each ] : a . Split the dataset into training and testing sets using
A marks: each:
a Split the dataset into training and testing sets using traintestsplit function with for
training and for training using random state
b Build a decision tree classifier for predicting the class label. Fit the classifier using the
training dataset. Set random state to criterion to entropy, and splitter to best.
c Draw the decision tree using scikitlearn sklearn
d Test the classifier on the testing data set, and print the confusion matrix and classification
metrics Accuracy sensitivity Recall Precision of the decision tree classifier.
A marks: each : Using the same dataset split in Aa
Page of
ISE: Homework
a Build a Random forest classifier for predicting the class label with trees. Fit the classifier
using the training set. Set criterion to entropy and randomstate to
b Draw the trees using scikit learn sklearn
c Test the classifier on the testing data set, and print the confusion matrix and classification
metrics Accuracy sensitivity Recall Precision of the Random forest classifier.
d Repeat Aac using a Random forest with trees instead of A marks: Calculate the Information Gain IG for the class variable "Drug" given the feature
selected BP as a root node.
A marks: From the decision tree built in A write three classification rules using the
normalized values first then return it to the original values.
A marks: Write an association rule for BP Cholestrol", which rule has the highest
accuracy? Write the corresponding support and accuracy.
A marks: Repeat parts b c and d in A using the Nave Bayes GaussianNB classifier.
A Compare the performance of the Nave Bayes against the built decision tree and random forest
classifiers using confusion matrix. Based on the comparison, which one is the best to use with
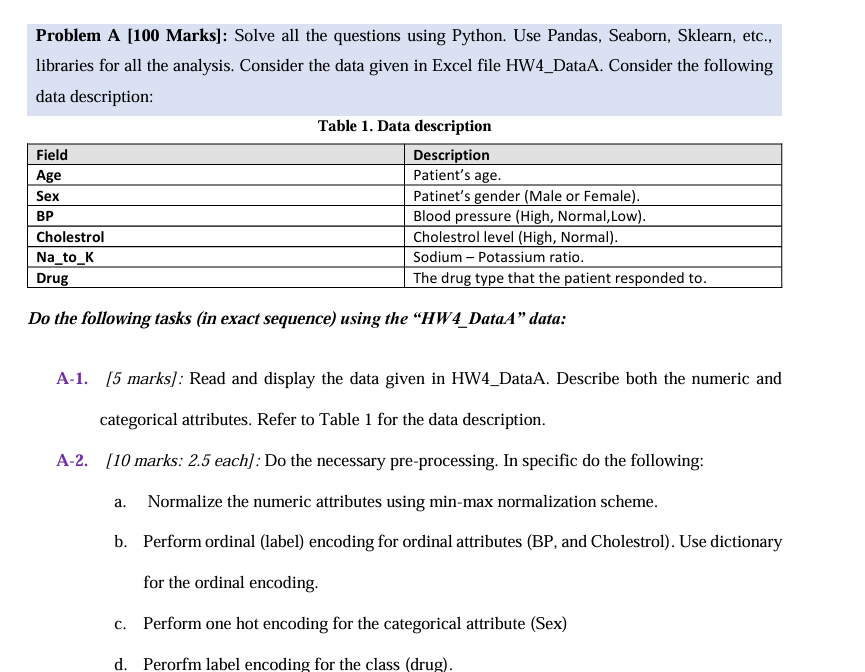
the given datat set? Problem A Marks: Solve all the questions using Python. Use Pandas, Seaborn, Sklearn, etc.,
libraries for all the analysis. Consider the data given in Excel file HWDataA. Consider the following
data description:
Table Data description
Do the following tasks in exact sequence using the HWDataA" data:
A marks: Read and display the data given in HWDataA. Describe both the numeric and
categorical attributes. Refer to Table for the data description.
A marks: each: Do the necessary preprocessing. In specific do the following:
a Normalize the numeric attributes using minmax normalization scheme.
b Perform ordinal label encoding for ordinal attributes BP and Cholestrol Use dictionary
for the ordinal encoding.
c Perform one hot encoding for the categorical attribute Sex
d Perorfm label encoding for the class drug
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Pro PowerShell For Database Developers
Authors: Bryan P Cafferky
1st Edition
1484205413, 9781484205419