

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: 1d addi sd x1,0(x2) x1,x1,1 x1,0,(x2) x2, x2,4 x4, x3,x2 x4, Loop ;load x1 from address
![C.1[15/15/15/15/25/10/15]<A.2> Use the following code fragment:Loop: ld x1,0(x2) ;load xl from address 0+x2addi x1,x1,1 ;x](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2021/07/60e424c3048ff_1625564355082.jpg)
![d. [15]<C.2> Show the timing of this instruction sequence for the 5-stage RISCpipeline with full forwarding and bypassing ha](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2021/07/60e424c52f567_1625564356929.jpg)
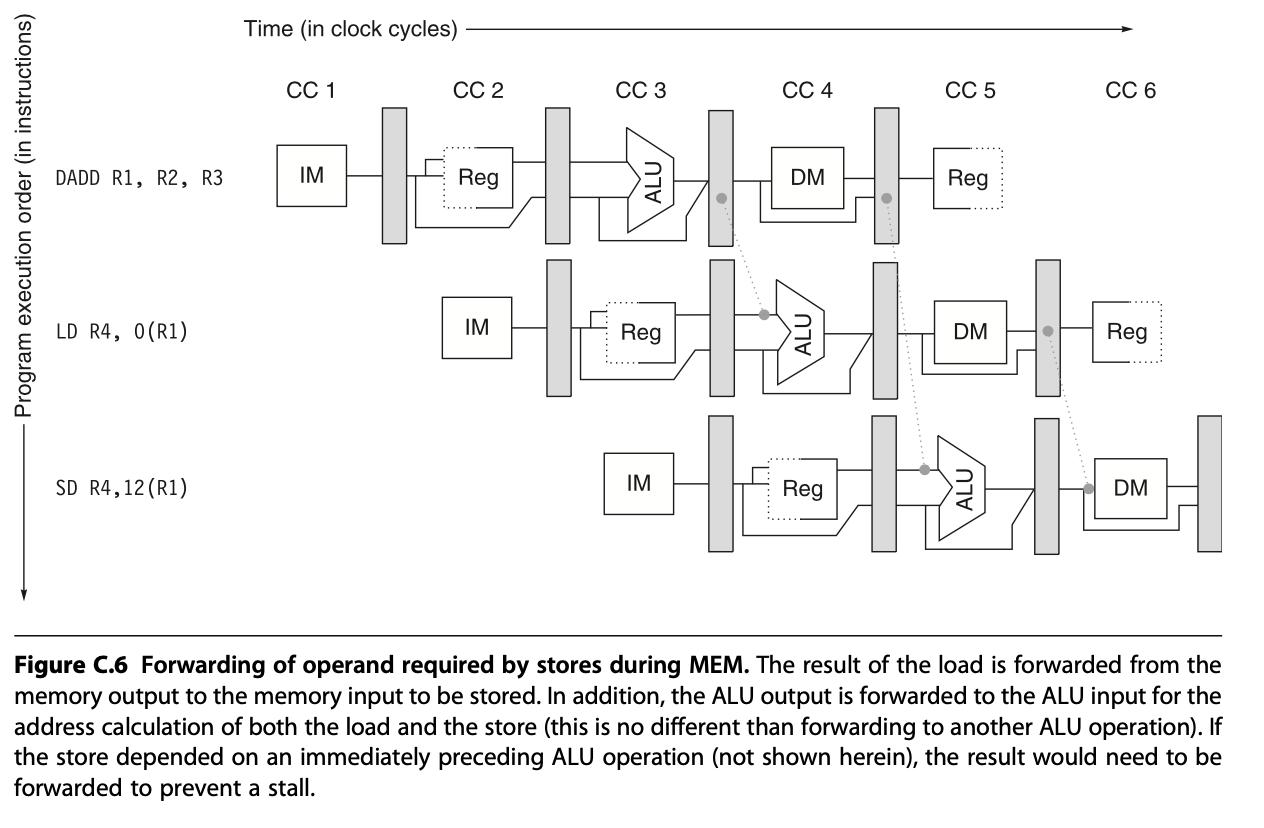
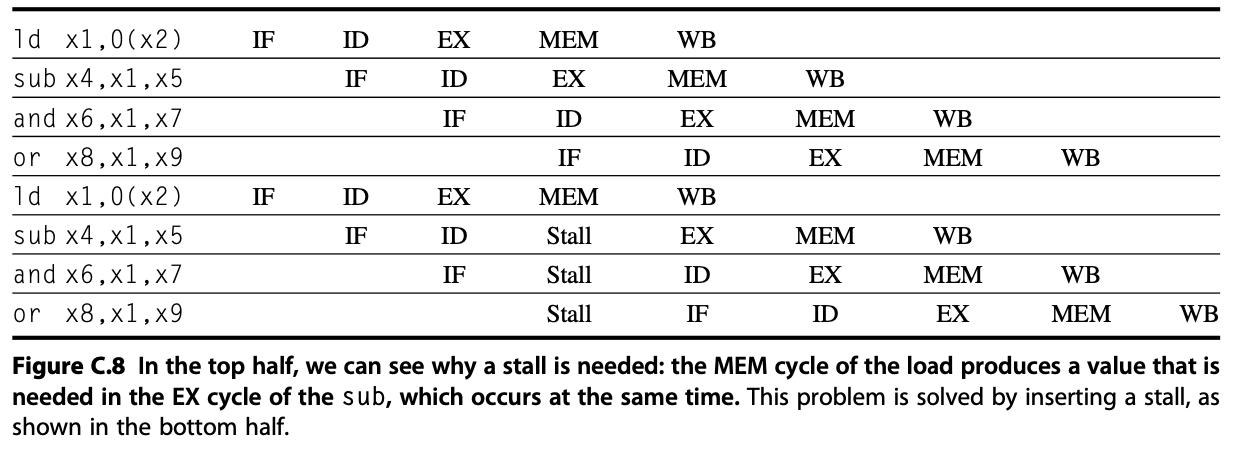
C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: 1d addi sd x1,0(x2) x1,x1,1 x1,0,(x2) x2, x2,4 x4, x3,x2 x4, Loop ;load x1 from address 0+x2 ;x1=x1+1 ;store x1 at address 0+x2 ;x2=x2+4 ;x4=x3-x2 addi sub bnez ;branch to Loop if x4!= 0 Assume that the initial value of x3 is x2+396. d. [15] Show the timing of this instruction sequence for the 5-stage RISC pipeline with full forwarding and bypassing hardware, as shown in Figure C.6. Use a pipeline timing chart like that shown in Figure C.8. Assume that the branch is handled by predicting it as taken. If all memory references take 1 cycle, how many cycles does this loop take to execute? e. [25] High-performance processors have very deep pipelines-more than 15 stages. Imagine that you have a 10-stage pipeline in which every stage of the 5-stage pipeline has been split in two. The only catch is that, for data for- warding, data are forwarded from the end of a pair of stages to the beginning of the two stages where they are needed. For example, data are forwarded from the output of the second execute stage to the input of the first execute stage, still causing a 1-cycle delay. Show the timing of this instruction sequence for the 10-stage RISC pipeline with full forwarding and bypassing hardware. Use a pipeline timing chart like that shown in Figure C.8 (but with stages labeled IF1, IF2, ID1, etc.). Assume that the branch is handled by predicting it as taken. If all memory references take 1 cycle, how many cycles does this loop take to execute? f. [10] Assume that in the 5-stage pipeline, the longest stage requires 0.8 ns, and the pipeline register delay is 0.1 ns. What is the clock cycle time of the 5-stage pipeline? If the 10-stage pipeline splits all stages in half, what is the cycle time of the 10-stage machine? Time (in clock cycles) 1 CC 2 3 4 5 6 DADD R1, R2, R3 IM Reg DM Reg LD R4, 0(R1) IM Reg DM Reg SD R4,12 (R1) IM Reg DM Figure C.6 Forwarding of operand required by stores during MEM. The result of the load is forwarded from the memory output to the memory input to be stored. In addition, the ALU output is forwarded to the ALU input for the address calculation of both the load and the store (this is no different than forwarding to another ALU operation). If the store depended on an immediately preceding ALU operation (not shown herein), the result would need to be forwarded to prevent a stall. Program execution order (in instructions) ALU 1d x1,0(x2) IF ID EX WB sub x4,x1,x5 IF ID EX WB and x6,x1,x7 IF ID EX WB or x8,x1,x9 1d x1,0(x2) IF ID EX MEM WB IF ID EX MEM WB sub x4,x1,x5 IF ID Stall EX WB and x6,x1,x7 IF Stall ID EX MEM WB or x8,x1,x9 Stall IF ID EX MEM WB Figure C.8 In the top half, we can see why a stall is needed: the MEM cycle of the load produces a value that is needed in the EX cycle of the sub, which occurs at the same time. This problem is solved by inserting a stall, as shown in the bottom half.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Introduction to Algorithms
Authors: Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest
3rd edition
978-0262033848