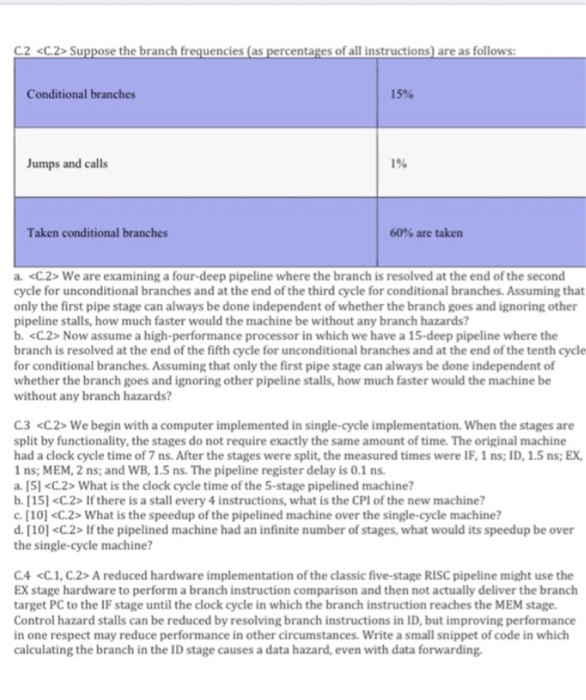
Question: C.5 For these problems, we will explore a pipeline for a register-memory architecture. The architecture has two instruction formats: a register-register format and a register-memory
C.5 For these problems, we will explore a pipeline for a register-memory architecture. The architecture has two instruction formats: a register-register format and a register-memory format. There is a single-memory addressing mode (offset + base register). There is a set of ALU operations with the format: ALUop Rdest, Rsrci, Rsrc2 ALUop Rdest, Rsrcl, MEM where the ALUop is one of the following: add, subtract, AND, OR, load (Rsrel ignored), or store. Rsrc or Rdest are registers. MEM is a base register and offset pair. Branches use a full compare of two registers and are PC relative. Assume that this machine is pipelined so that a new instruction is started every clock cycle. The pipeline structure, similar to that used in the VAX 8700 micropipeline [Clark 1987), is IF RF ALUI MEM WB IF RFALUI MEM ALU2 WB IF RF ALUI MEMALU2 WB IF RFALUI MEMALU2 WB IF RF ALUI MEM ALU2 WB IF RF ALUI MEMALU2 WB The first ALU stage is used for effective address calculation for memory references and branches. The second ALU cycle is used for operations and branch comparison. RF is both a decode and register-fetch cycle. Assume that when a register read and a register write of the same register occur in the same clock the write data are forwarded. a. C.2 Find the number of adders needed, counting any adder or incrementer, show a combination of instructions and pipe stages that justify this answer. You need only give one combination that maximizes the adder count. b. Find the number of register read and write ports and memory read and write ports required. Show that your answer is correct by showing a combination of instructions and pipeline stage indicating the instruction and the number of read ports and write ports required for that instruction c. Determine any data forwarding for any ALUs that will be needed. Assume that there are separate ALUs for the ALUI and ALU2 pipe stages. Put in all forwarding among ALUs necessary to avoid or reduce stalls. Show the relationship between the two instructions involved in forwarding using the format of the table in Eigure C.26 but ignoring the last two columns. Be careful to consider forwarding across an intervening instruction-for example, ADO R I,... any instruction RI, .. d. Show all of the data forwarding requirements necessary to avoid or reduce stalls when either the source or destination unit is not an ALU. Use the same format as in Figure C.26. again ignoring the last two columns. Remember to forward to and from memory references e. Show all the remaining hazards that involve at least one unit other than an ALU as the source or destination unit. Use a table like that shown in Figure 2.25, but replace the last column with the lengths of the hazards. f. Suppose the branch frequencies (as percentages of all instructions are as follows: Conditional branches Jumps and calls Taken conditional branches 60% are taken a. We are examining a four-deep pipeline where the branch is resolved at the end of the second cycle for unconditional branches and at the end of the third cycle for conditional branches. Assuming that only the first pipe stage can always be done independent of whether the branch goes and ignoring other pipeline stalls, how much faster would the machine be without any branch hazards? b. Now assume a high-performance processor in which we have a 15-deep pipeline where the branch is resolved at the end of the fifth cycle for unconditional branches and at the end of the tenth cycle for conditional branches. Assuming that only the first pipe stage can always be done independent of whether the branch goes and ignoring other pipeline stalls, how much faster would the machine be without any branch hazards? C.3 We begin with a computer implemented in single-cycle implementation. When the stages are split by functionality, the stages do not require exactly the same amount of time. The original machine had a clock cycle time of 7 ns. After the stages were split, the measured times were IF, 1 ns; ID, 1.5 ns; EX, 1 ns; MEM, 2 ns; and WB, 1.5 ns. The pipeline register delay is 0.1 ns. a. [5] What is the clock cycle time of the 5-stage pipelined machine? b. [15] If there is a stall every 4 instructions, what is the CPI of the new machine? peedup of the pipelined machine over the single-cycle machine? d. [10] If the pipelined machine had an infinite number of stages, what would its speedup be over the single-cycle machine? C.4