

Question: ***Can you help with my python project. This question is an exception handling question. All the details are below and the template for solving the
***Can you help with my python project. This question is an exception handling question. All the details are below and the template for solving the question is above.***


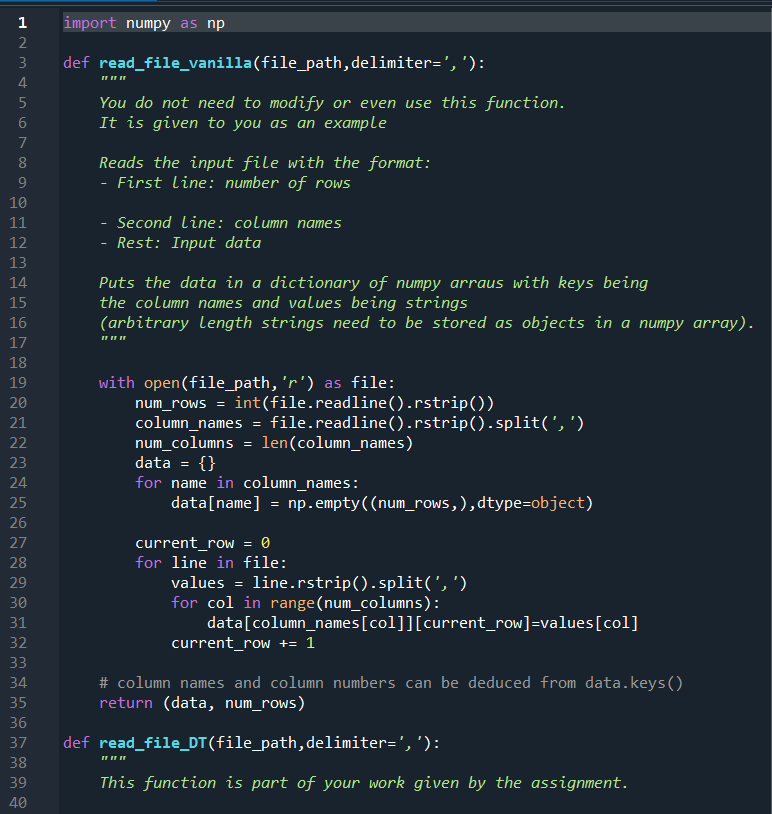
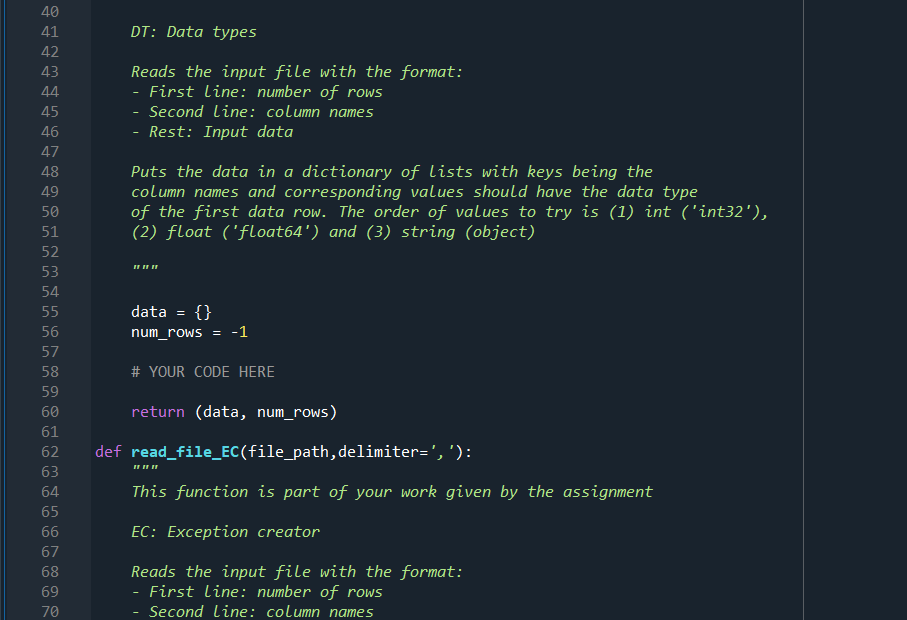
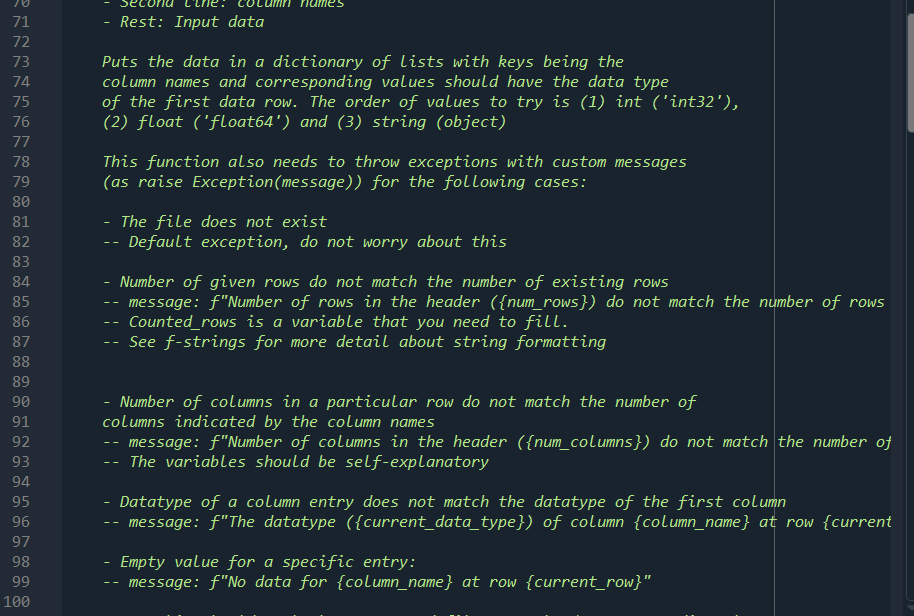
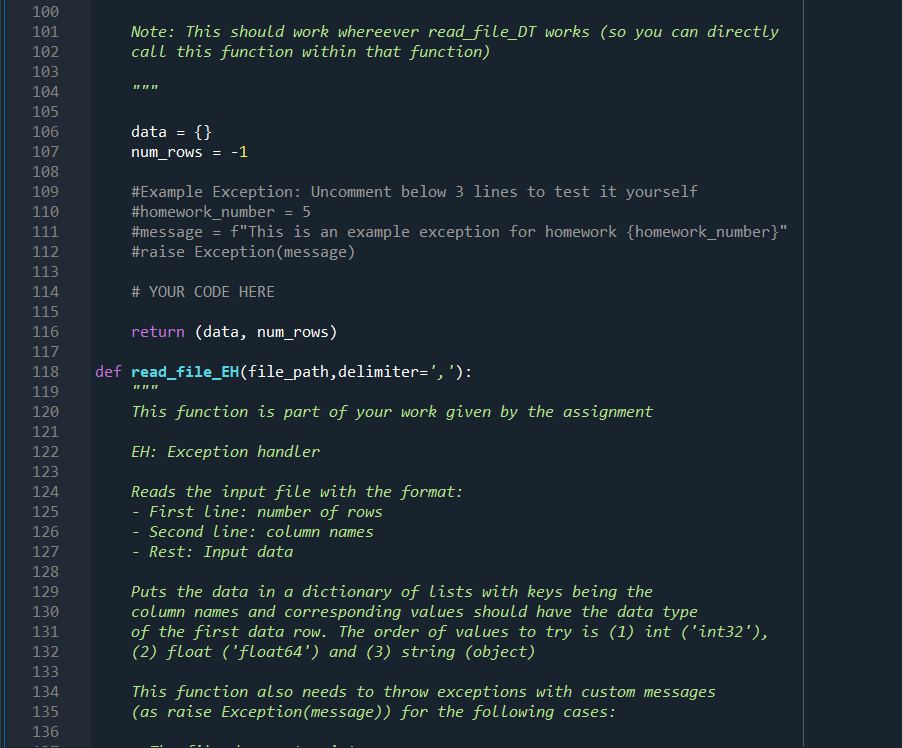
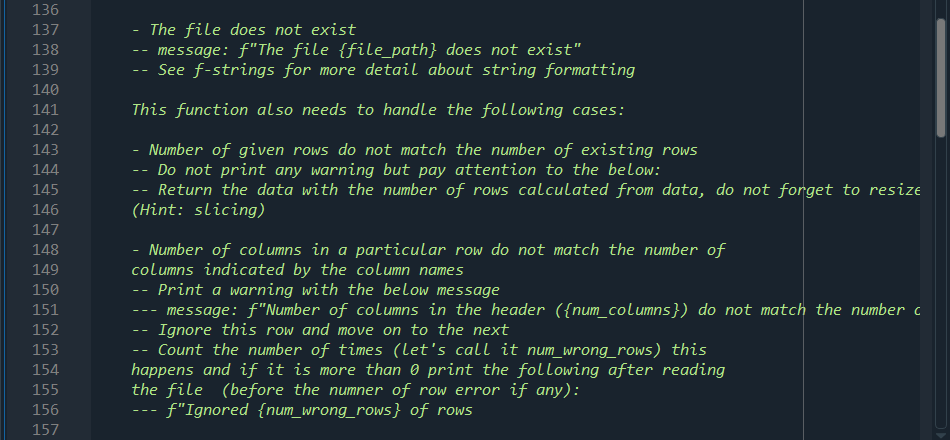
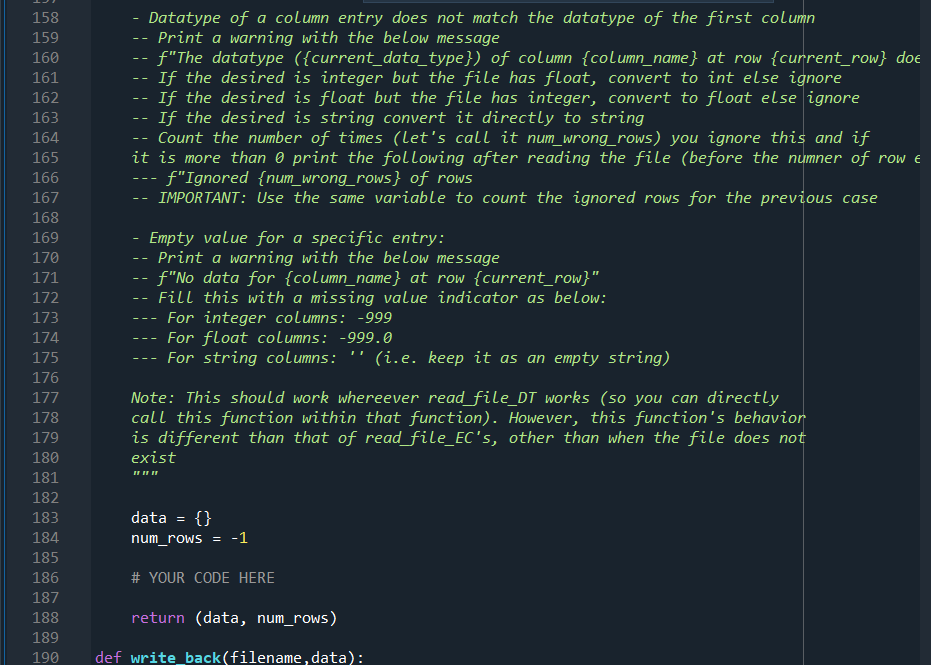
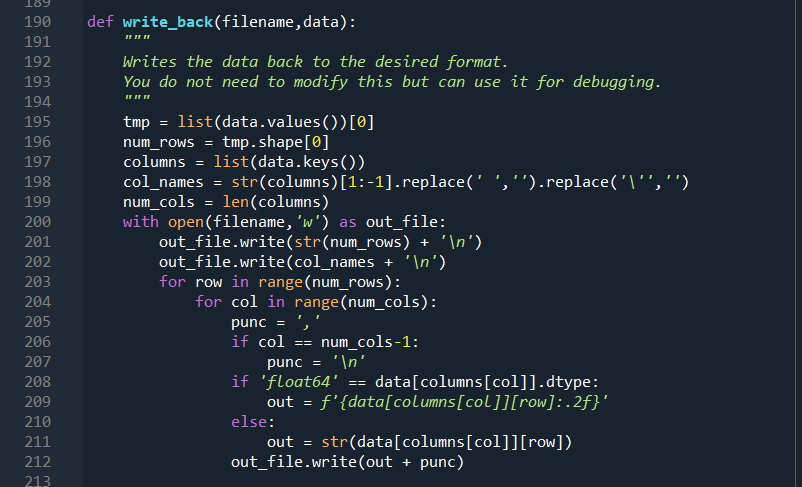
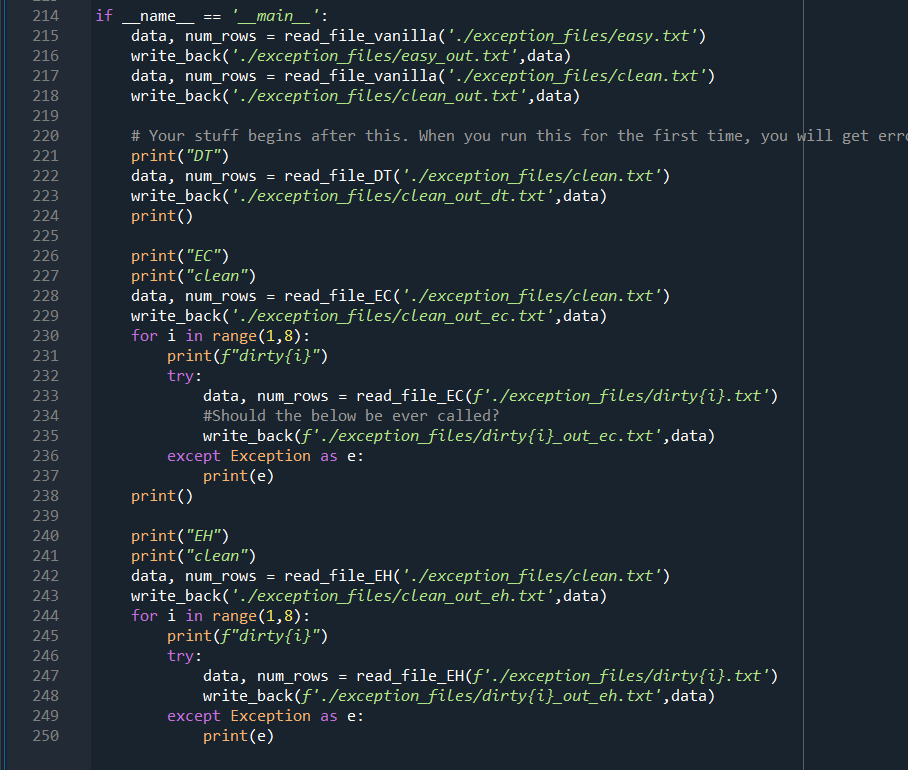
import numpy as np def read_file_vanilla(file_path, delimiter=','): 1 2 3 4. 5 6 7 8 9 10 11 You do not need to modify or even use this function. It is given to you as an example Reads the input file with the format: First line: number of rows Second Line: column names Rest: Input data 14 15 Puts the data in a dictionary of numpy arraus with keys being the column names and values being strings (arbitrary length strings need to be stored as objects in a numpy array). 16 17 18 19 20 21 with open(file_path, 'r') as file: num_rows = int(file.readline().rstrip()) column_names = file.readline().rstrip().split(',') num_columns = len(column_names) data = {} for name in column_names: data[name] = np.empty((num_rows,), dtype=object) 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 current_row = 0 for line in file: values = line.rstrip().split(',') for col in range(num_columns): data[column_names [col]][current_row]=values[col] current_row += 1 # column names and column numbers can be deduced from data.keys() return (data, num_rows) def read_file_DT(file_path, delimiter=', '): This function is part of your work given by the assignment. 40 DT: Data types Reads the input file with the format: First line: number of rows - Second line: column names - Rest: Input data Puts the data in a dictionary of lists with keys being the column names and corresponding values should have the data type of the first data row. The order of values to try is (1) int ('int32'), (2) float ('float64') and (3) string (object) 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 data = {} num_rows = -1 # YOUR CODE HERE return (data, num_rows) def read_file_EC(file_path, delimiter=','): This function is part of your work given by the assignment 65 66 67 EC: Exception creator 68 69 70 Reads the input file with the format: First line: number of rows Second Line: column names - Rest: Input data Puts the data in a dictionary of lists with keys being the column names and corresponding values should have the data type of the first data row. The order of values to try is (1) int ('int32'), (2) float ('float64') and (3) string (object) This function also needs to throw exceptions with custom messages (as raise Exception(message)) for the following cases: The file does not exist Default exception, do not worry about this 71 72 73 74. 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 Number of given rows do not match the number of existing rows message: f"Number of rows in the header ({num_rows}) do not match the number of rows Counted_rows is a variable that you need to fill. See f-strings for more detail about string formatting - Number of columns in a particular row do not match the number of columns indicated by the column names message: f"Number of columns in the header ({num_columns}) do not match the number of The variables should be self-explanatory Datatype of a column entry does not match the datatype of the first column message: f"The datatype ({current_data_type}) of column {column_name} at row {current Empty value for a specific entry: message: f"No data for {column_name} at row {current_row}" Note: This should work whereever read_file_DT works (so you can directly call this function within that function) IT IT IT data = {} num_rows = -1 #Example Exception: Uncomment below 3 lines to test it yourself #homework_number = 5 #message f"This is an example exception for homework {homework_number}" #raise Exception(message) # YOUR CODE HERE return (data, num_rows) 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 def read_file_EH(file_path, delimiter=', '): This function is part of your work given by the assignment EH: Exception handler Reads the input file with the format: First line: number of rows - Second line: column names Rest: Input data Puts the data in a dictionary of lists with keys being the column names and corresponding values should have the data type of the first data row. The order of values to try is (1) int ('int32'), (2) float ('float64') and (3) string (object) This function also needs to throw exceptions with custom messages (as raise Exception(message)) for the following cases: The file does not exist message: f"The file {file_path} does not exist" See f-strings for more detail about string formatting This function also needs to handle the following cases: Number of given rows do not match the number of existing rows Do not print any warning but pay attention to the below: Return the data with the number of rows calculated from data, do not forget to resize (Hint: slicing) 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 Number of columns in a particular row do not match the number of columns indicated by the column names -- Print a warning with the below message message: f"Number of columns in the header ({num_columns}) do not match the number c Ignore this row and move on to the next Count the number of times (let's call it num_wrong_rows) this happens and if it is more than a print the following after reading the file (before the numner of row error if any): f"Ignored {num_wrong_rows} of rows Datatype of a column entry does not match the datatype of the first column Print a warning with the below message f"The datatype ({current_data_type}) of column {column_name} at row {current_row} doe If the desired is integer but the file has float, convert to int else ignore If the desired is float but the file has integer, convert to float else ignore If the desired is string convert it directly to string Count the number of times (let's call it num_wrong_rows) you ignore this and if it is more than o print the following after reading the file (before the numner of rowe f"Ignored {num_wrong_rows} of rows IMPORTANT: Use the same variable to count the ignored rows for the previous case --- 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 Empty value for a specific entry: Print a warning with the below message f"No data for {column_name} at row {current_row}" Fill this with a missing value indicator as below: For integer columns: -999 For float columns: -999.0 For string columns: (i.e. keep it as an empty string) --- --- Note: This should work whereever read_file_DT works (so you can directly call this function within that function). However, this function's behavior is different than that of read_file_EC's, other than when the file does not exist data = {} num_rows = -1 # YOUR CODE HERE return (data, num_rows) def write_back(filename, data): 10 def write_back(filename, data): Writes the data back to the desired format. You do not need to modify this but can use it for debugging. 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 tmp = list(data.values())[0] num_rows tmp.shape[@] columns = list(data.keys()) col_names = str(columns)[1:-1).replace('','').replace('|','') num_cols = len(columns) with open(filename, 'w') as out_file: out_file.write(str(num_rows) + ' ') out_file.write(col_names + ' ') for row in range(num_rows): for col in range(num_cols): punc = if col == num_cols-1: punc = ' ' if 'float64' == data[columns [col]].dtype: out = f'{data[columns[col]][row]:.2f}' else: out = str(data[columns [col]][row]) out_file.write(out + punc) if name _main__': data, num_rows = read_file_vanilla('./exception files/easy.txt') write_back('./exception_files/easy_out.txt', data) data, num_rows = read_file_vanilla('./exception files/clean. txt') write_back('./exception files/clean_out. txt', data) # Your stuff begins after this. When you run this for the first time, you will get erre print("OT") data, num_rows = read_file_DT('./exception files/clean. txt') write_back('./exception_files/clean_out_dt.txt', data) print() 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 print("EC") print("clean") data, num_rows = read_file_EC('./exception files/clean. txt') write_back('./exception files/clean_out_ec. txt', data) for i in range(1,8): print(f"dirty{i}") try: data, num_rows = read_file_ECf'./exception files/dirty{i}.txt') #Should the below be ever called? write_back(f'./exception files/dirty{i}_out_ec. txt', data) except Exception as e: print(e) print() print("EH") print("clean") data, num_rows = read_file_EH('./exception files/clean. txt') write_back('./exception_files/clean_out_eh. txt', data) for i in range(1,8): print(f"dirty{i}") try: data, num_rows = read_file_EH(F'./exception files/dirty{i}. txt') write_back(f'./exception files/dirty{i}_out_eh. txt', data) except Exception as e: print(e) In this question, you are going to read files that have a very similar format to csv files. The format is as follows: The first line contains the number of rows The second line contains the name of the columns (which also dictate the number of columns) Each remaining line has the data points in a comma separated list An easy example with ten rows and three columns is given below: 10 id, username, grade 0, higrailw19,93.4 1, ghedicab, 22.1 2, resporym20,15.6 3, rsferezi18,84 4, fuskysto, 53.8 5, iouncove20,63.4 6, rneleyer17, 13.5 7, ermaryce19,57 8, airtives, 70.4 9, ricalfin, 62.53 You are asked to put this data in a dictionary of 10 NumPy arrays with the correct data type and error handling. The starter code for this question is given in FileReadExceptions.py. The read_file_vanilla function includes code to read a file without any errors and string data types. You are asked to fill the other file reading functions given in the document. Important Note: The FileReadExceptions.py file has very detailed comments. Make sure to read them! Part 1: The vanilla version of the code reads the file as string and stores it as a string. However, this is not very useful if you need numbers. This part of the question asks you to create the NumPy arrays for each column based on the first row. Note that you read the files as strings. You need to figure out the type of the column from these strings. One way to do it is to try to convert the string to another data type and check if you succeed or not. For this question, you will test whether a string is an integer or a float and select the type of the column. The test order should be integer (Python: int, NumPy: 'int32'), float (Python: float, NumPy: 'float64') and lastly string (Python: anything that is not an integer or a float, NumPy: object) In the example above, the first data columns are integers. We can deduce this by trying to convert the string corresponding to the first item of the first column (which is '0') to an integer and succeeding. The first item of the second column ("higrailw19') cannot be converted to a number so we it will be stored as a string. The first item of the third column (93.4') cannot be converted to an integer but it can be converted to a float. To create a Numpy array with the desired data type, we use the keyword dtype. Integer: np.empty (shape, dtype='int32') Float: np.empty(shape, dtype='float 64') String: np.empty (shape, dtype=object) Fill out the read_file_dt function for this part. This part does not require error handling. Part 2: This part is where we start checking for errors and raise exceptions when we find anything, on top of storing the data with the correct data types as described in part 1. There are four exception cases you need to watch for: 1. When there are less number of rows in the file than given in the header (e.g. the header says 10 rows but there are actually 3 rows in the file). 2. When the data type of an entry does not match the data type of its column 3. When there are less number of columns in a row than is implied with the column names (e.g. one row has 2 columns instead of 3 for the above example) 4. When there is missing data (Empty string between commas, e.g. 9,,62.53) You are required to raise an exception for these cases. The message required for each case is given in the comments of the FileReadExceptions.py. Fill out the read_file_ec function for this part. Again, the file has extensive comments on what to do and what to print to the screen. Part 3: This part is where we handle or ignore the aforementioned errors as follows: 1. When there are less number of rows in the file than given in the header: Nothing special during the file reading phase. Afterwards, you need to make sure that the Numpy arrays in the data dictionary have the correct lengths. 2. When the data type of an entry does not match the data type of its column: Try convert the values, int to float (1=1.0, float to int(1.2=1) and both to string is possible. All other scenarios, ignore but keep a counter 3. When there are less number of columns in a row than is implied with the column names: Ignore this but keep a counter (same counter given in the previous point) 4. When there is missing data: Fill it (integer = -999, float = -999.0, string = '') Fill out the read_file_eh function for this part. Again, the file has extensive comments on what to do and what to print to the screen. The files to be read are given under the exception_files folder within the zip. There is another helper function (write_back) to help you debug. We are also providing you with a text file, expected_output.txt, that has the desired output of your program. Do not assume that the test cases cover all the possibilities
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts