

Question
Could you provide a solution for problem 5.15 in the book that is titled Computer Systems: A Programmer's Perspective (Third Edition) by Bryant and O'Hallaron?
Could you provide a solution for problem 5.15 in the book that is titled "Computer Systems: A Programmer's Perspective (Third Edition)" by Bryant and O'Hallaron? The full text of problem 5.15 is provided below:
5.15
Please note, I have shared the full text of the problem, the full text of the problem that it references (below), and all diagrams associated with the reference problem. The Chegg expert has asked that I be more specific. I'm unsure of how to be more specific, because everything I have available related to this problem has been provided. If the experts can give me a more specific example of what would be helpful to them in answering the problem, please let me know and I will provide it. For example, if you still need me to be more specific, let me know which area of or aspect of the problem text that has been provided needs more clarification.
The Problem 5.15 above references another problem, 5.13. For reference, I've included the full test of problem 5.13 below. Please note that we do not need an answer for problem 5.13. I'm am copying and pasting all possible aspects of problem 5.15 for reference in case it may be helpful. The reference problem 5.13 is:


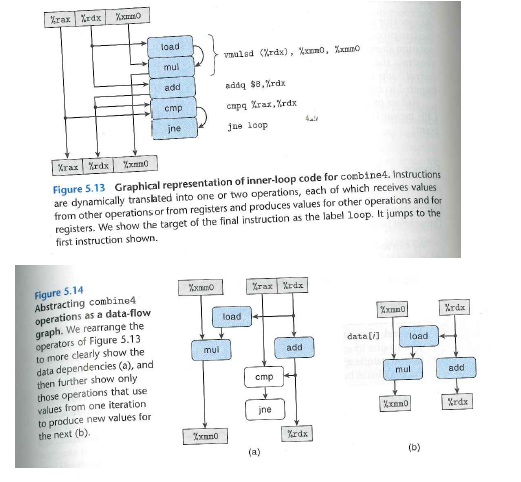
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Icdt 88 2nd International Conference On Database Theory Bruges Belgium August 31 September 2 1988 Proceedings Lncs 326
Authors: Marc Gyssens ,Jan Paredaens ,Dirk Van Gucht
1st Edition
3540501711, 978-3540501718