

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Create an RDD pipline to show the count of each part-of-speach tag sorted in descending order Complete the implementation of the pos_counts() function below
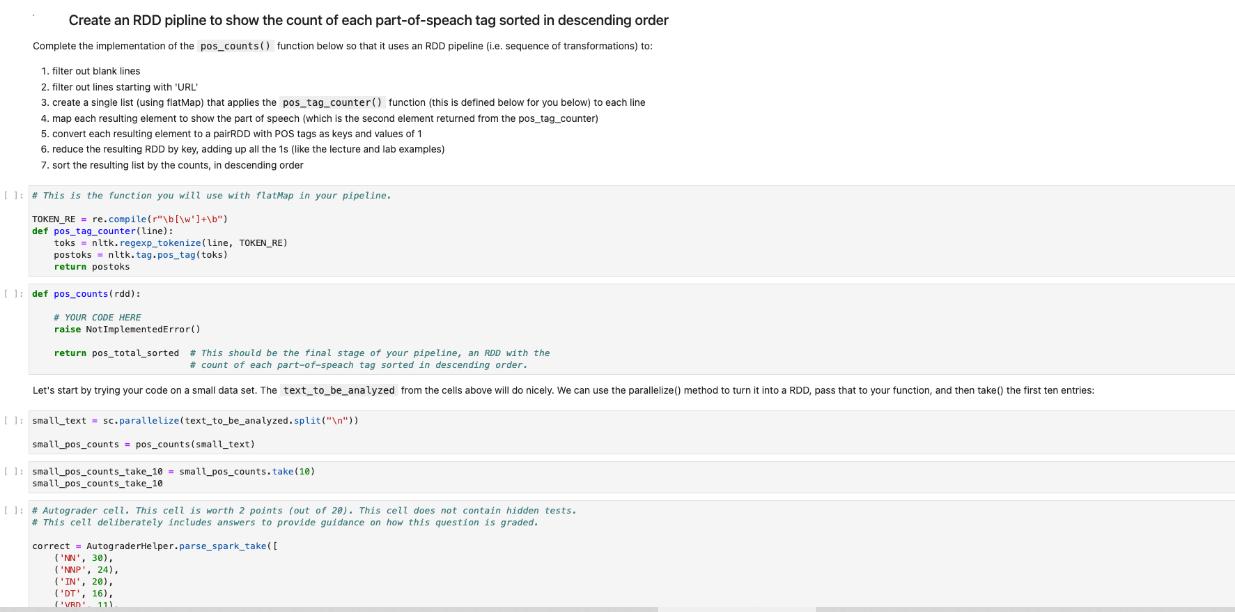
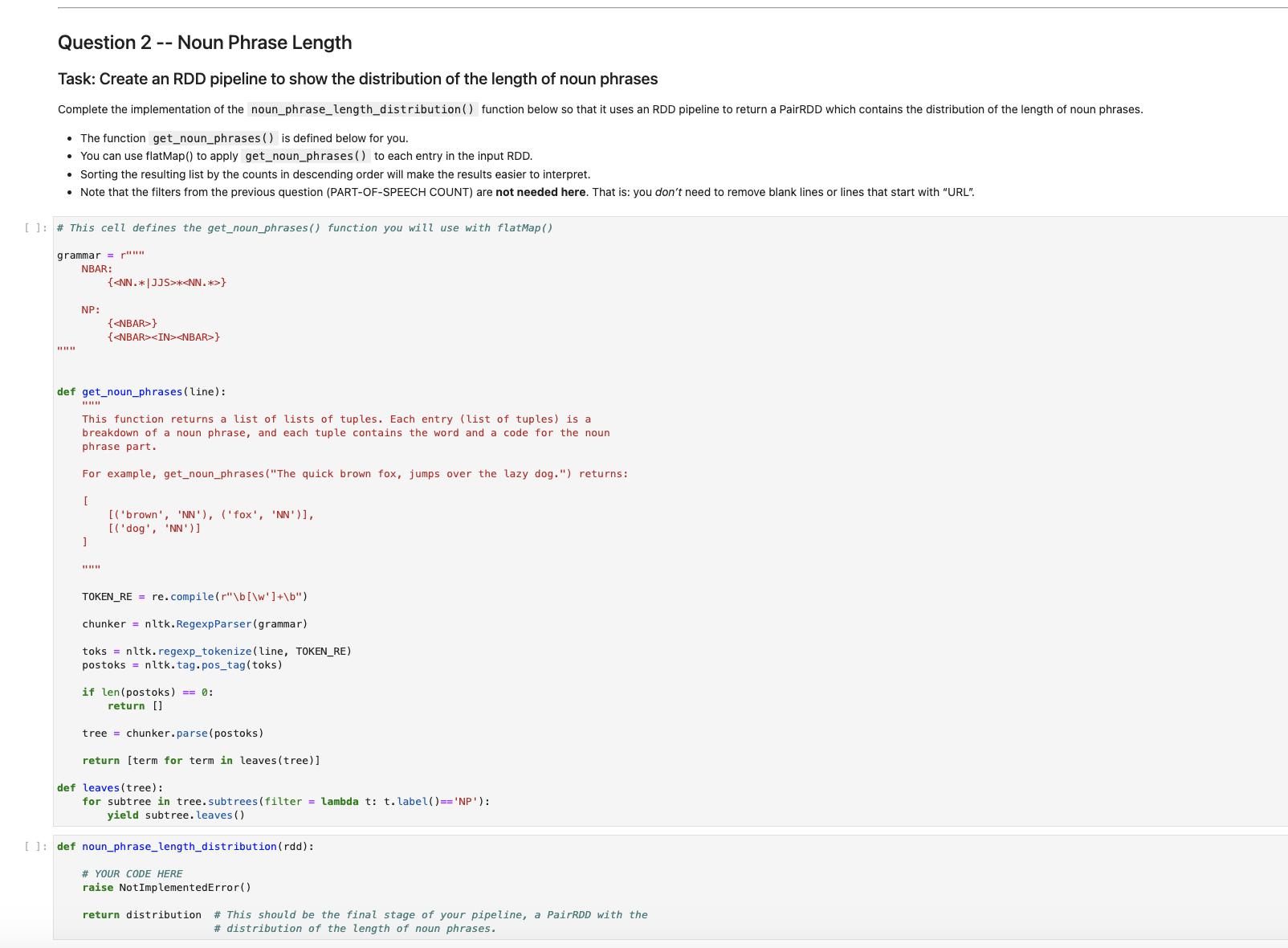
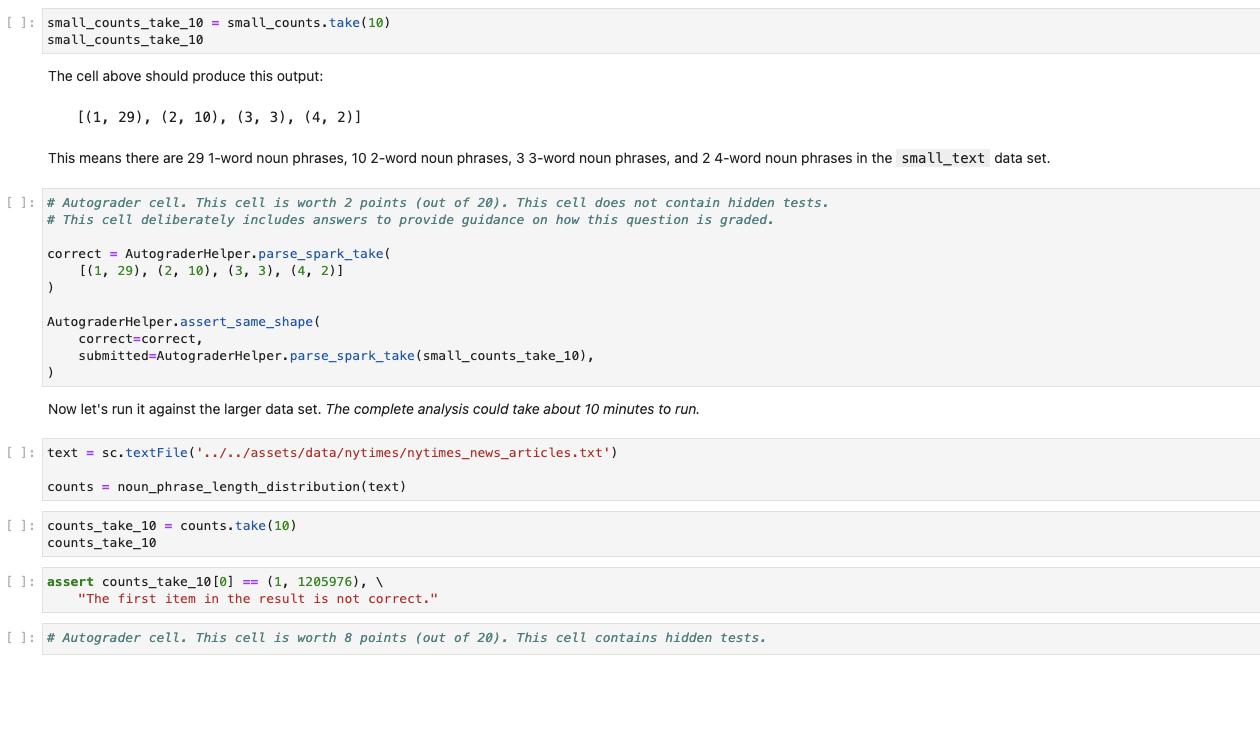
Create an RDD pipline to show the count of each part-of-speach tag sorted in descending order Complete the implementation of the pos_counts() function below so that it uses an RDD pipeline (i.e. sequence of transformations) to: 1. filter out blank lines 2. filter outlines starting with "URL" 3. create a single list (using flatMap) that applies the pos_tag_counter() function (this is defined below for you below) to each line 4. map each resulting element to show the part of speech (which is the second element returned from the pos_tag_counter) 5. convert each resulting element to a pairRDD with POS tags as keys and values of 1 6. reduce the resulting RDD by key, adding up all the 1s (like the lecture and lab examples) 7. sort the resulting list by the counts, in descending order 11:# This is the function you will use with flatMap in your pipeline. TOKEN_RE = re.compile(r"\b[\w]+\b") def pos_tag_counter(line): toks = nltk.regexp_tokenize (line, TOKEN_RE) postoks nltk.tag.pos_tag(toks) return postoks [1: def pos_counts (rdd): # YOUR CODE HERE raise Not ImplementedError() return pos_total_sorted # This should be the final stage of your pipeline, an RDD with the # count of each part-of-speach tag sorted in descending order. Let's start by trying your code on a small data set. The text_to_be_analyzed from the cells above will do nicely. We can use the parallelize() method to turn it into a RDD, pass that to your function, and then take() the first ten entries: II:small_text= sc.parallelize (text_to_be_analyzed.split(" ")) small_pos_counts = pos_counts (small_text) 11: small_pos_counts_take_10= small_pos_counts.take (10) small_pos_counts_take_10 11: # Autograder cell. This cell is worth 2 points (out of 280). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. correct = AutograderHelper.parse_spark_take([ ('NN', 30), ('NNP', 24), ('IN', 20), ('DT', 16), (VRD 11) Question 2 -- Noun Phrase Length Task: Create an RDD pipeline to show the distribution of the length of noun phrases Complete the implementation of the noun_phrase_length_distribution () function below so that it uses an RDD pipeline to return a PairRDD which contains the distribution of the length of noun phrases. The function get_noun_phrases () is defined below for you. You can use flat Map() to apply get_noun_phrases () to each entry in the input RDD. Sorting the resulting list by the counts in descending order will make the results easier to interpret. Note that the filters from the previous question (PART-OF-SPEECH COUNT) are not needed here. That is: you don't need to remove blank lines or lines that start with "URL". [ ]: # This cell defines the get_noun_phrases() function you will use with flatMap() grammar="" NBAR: ww NP: *** ] { * } def get_noun_phrases (line): This function returns a list of lists of tuples. Each entry (list of tuples) is a breakdown of a noun phrase, and each tuple contains the word and a code for the noun phrase part. For example, get_noun_phrases ("The quick brown fox, jumps over the lazy dog.") returns: [ www { } { } [('brown', 'NN'), ('fox', 'NN')], [('dog', 'NN')] TOKEN_RE= re.compile(r"\b[\w']+\b") chunker nltk.RegexpParser (grammar) toks = nltk. regexp_tokenize (line, TOKEN_RE) postoks nltk. tag.pos_tag (toks) if len(postoks) == 0: return [] tree chunker.parse(postoks) return [term for term in leaves (tree)] def leaves (tree): for subtree in tree. subtrees(filter = lambda t: t. label()== 'NP') : yield subtree. leaves () []: def noun_phrase_length_distribution (rdd): # YOUR CODE HERE raise NotImplementedError() return distribution # This should be the final stage of your pipeline, a PairRDD with the # distribution of the length of noun phrases. [ ]:small_counts_take_10=small_counts.take (10) small_counts_take_10 The cell above should produce this output: This means there are 29 1-word noun phrases, 10 2-word noun phrases, 3 3-word noun phrases, and 2 4-word noun phrases in the small_text data set. [(1, 29), (2, 10), (3, 3), (4, 2)] [ ]: # Autograder cell. This cell is worth 2 points (out of 20). This cell does not contain hidden tests. # This cell deliberately includes answers to provide guidance on how this question is graded. correct AutograderHelper.parse_spark_take( [(1, 29), (2, 10), (3, 3), (4, 2)] ) AutograderHelper.assert_same_shape ( correct correct, submitted=Autog raderHelper.parse_spark_take (small_counts_take_10), ) Now let's run it against the larger data set. The complete analysis could take about 10 minutes to run. []: text = sc.textFile('../../assets/data/nytimes/nytimes_news_articles.txt') counts = noun_phrase_length_distribution (text) [ ]: counts_take_10 = counts.take (10) counts_take_10 [ ]: assert counts_take_10 [0]== (1, 1205976), \ "The first item in the result is not correct." [ ]: # Autograder cell. This cell is worth 8 points (out of 20). This cell contains hidden tests.
Step by Step Solution
There are 3 Steps involved in it
Step: 1
To complete the implementation of the poscounts function and the nounphraselengthdistribution function using RDD pipelines in PySpark you can follow t...
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Using Excel & Access for Accounting 2010
Authors: Glenn Owen
3rd edition
1111532672, 978-1111532673