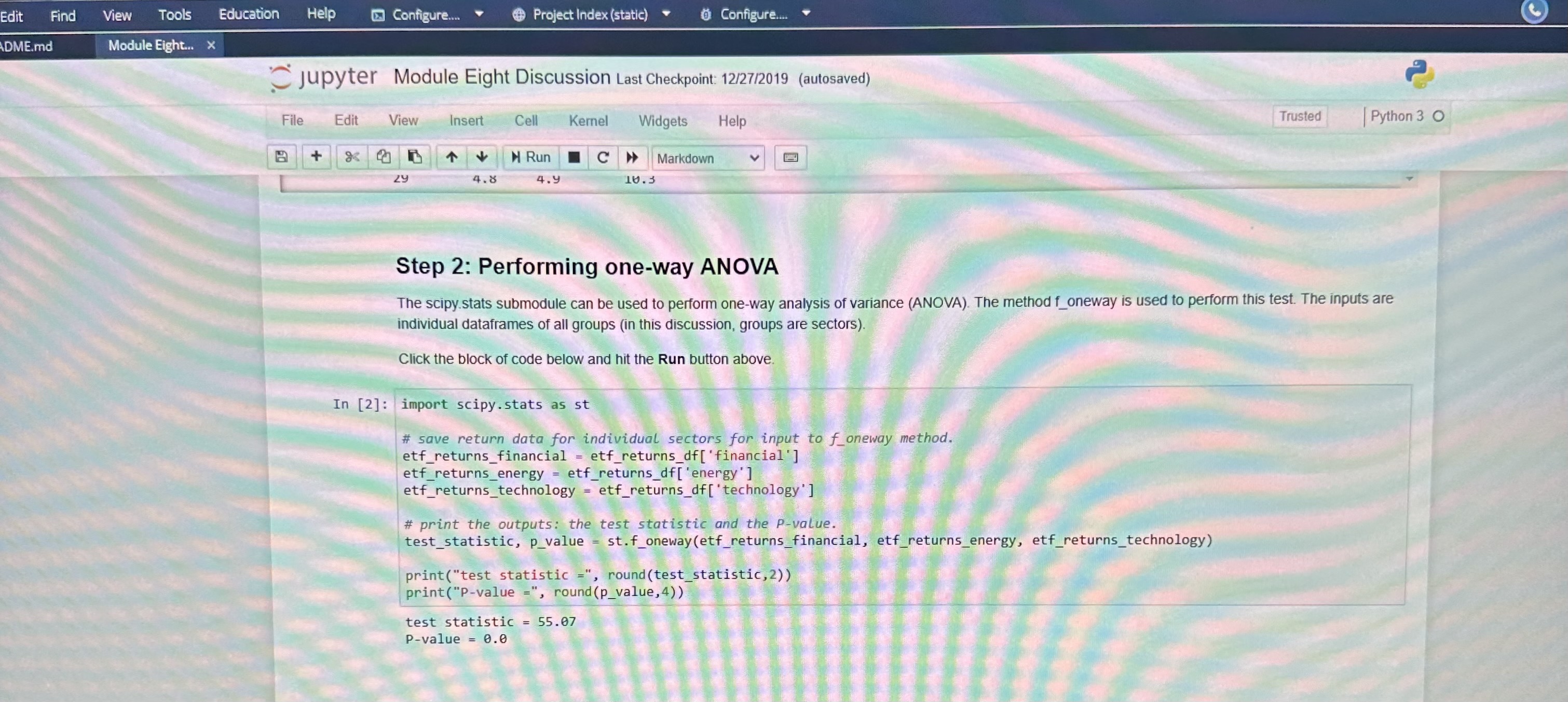
Define the null and alternative hypothesis in mathematical terms and in words. Report the level of significance. Include the test statistic and the P-value. See
Define the null and alternative hypothesis in mathematical terms and in words.
Report the level of significance.
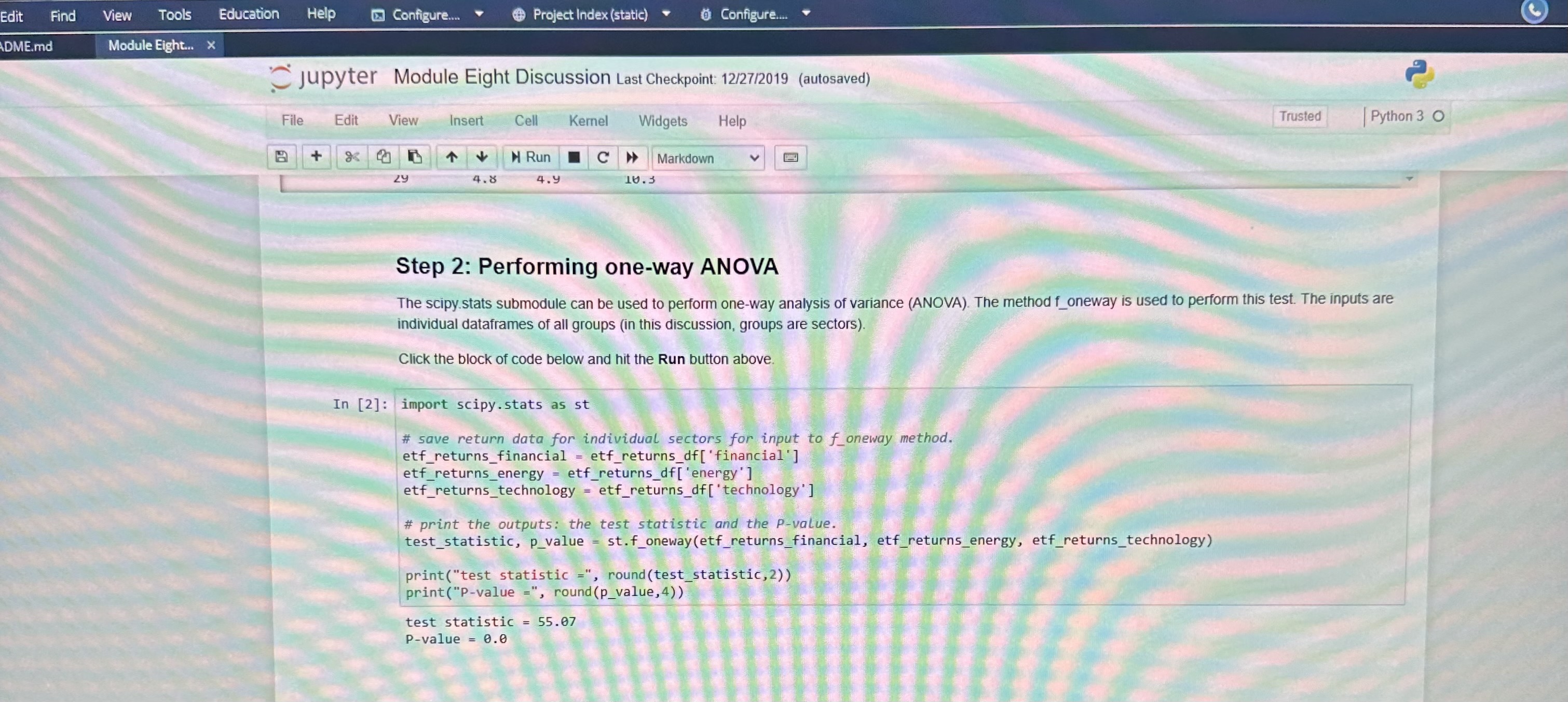
Include the test statistic and the P-value. See Step 2 in the Python script.
Provide your conclusion and interpretation of the test. Should the null hypothesis be rejected? Why or why not?
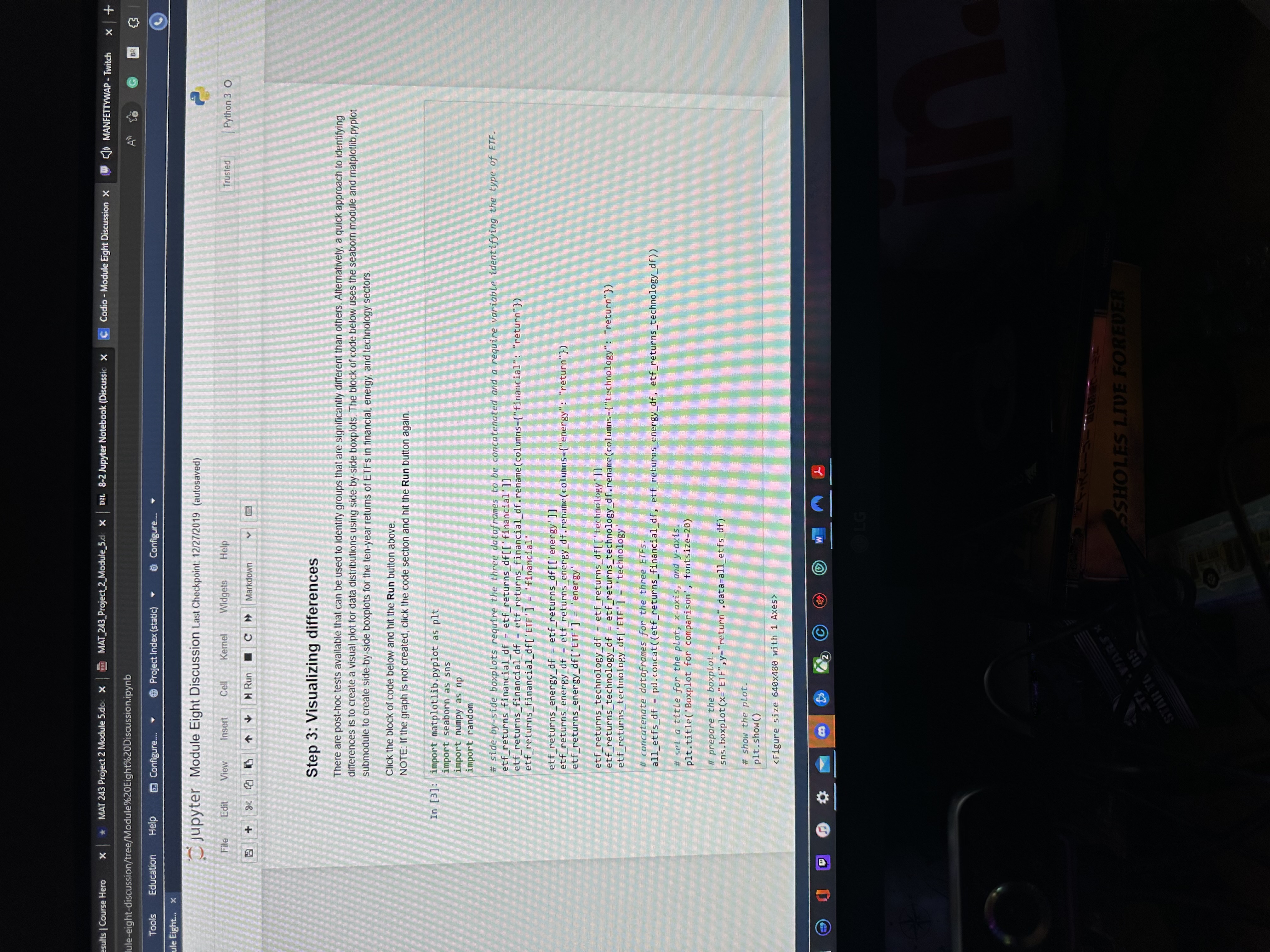
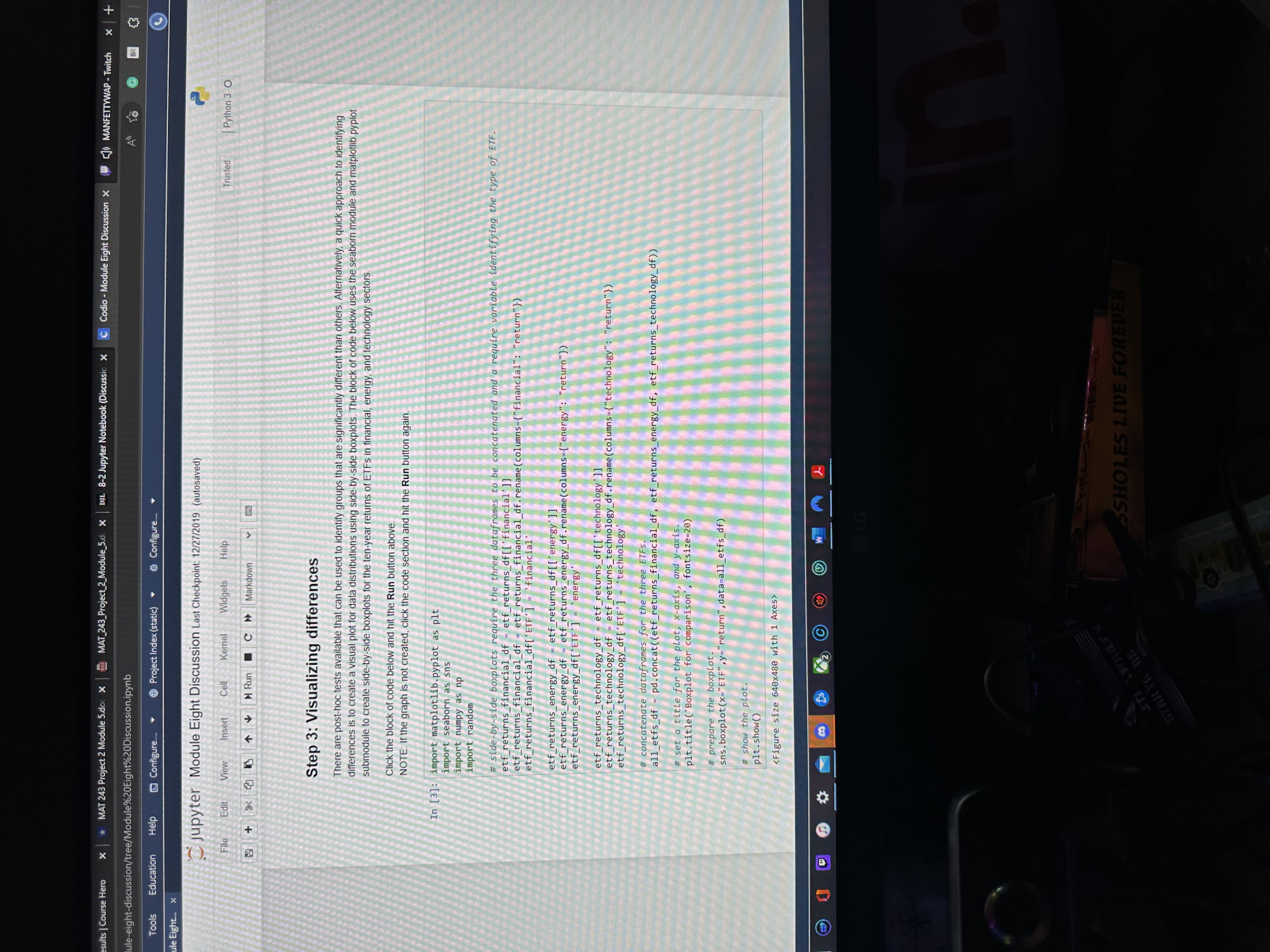
Does a side-by-side boxplot of the 10-year returns of ETFs from the three sectors confirm your conclusion of the hypothesis test? Why or why not? See Step 3 in the Python script.
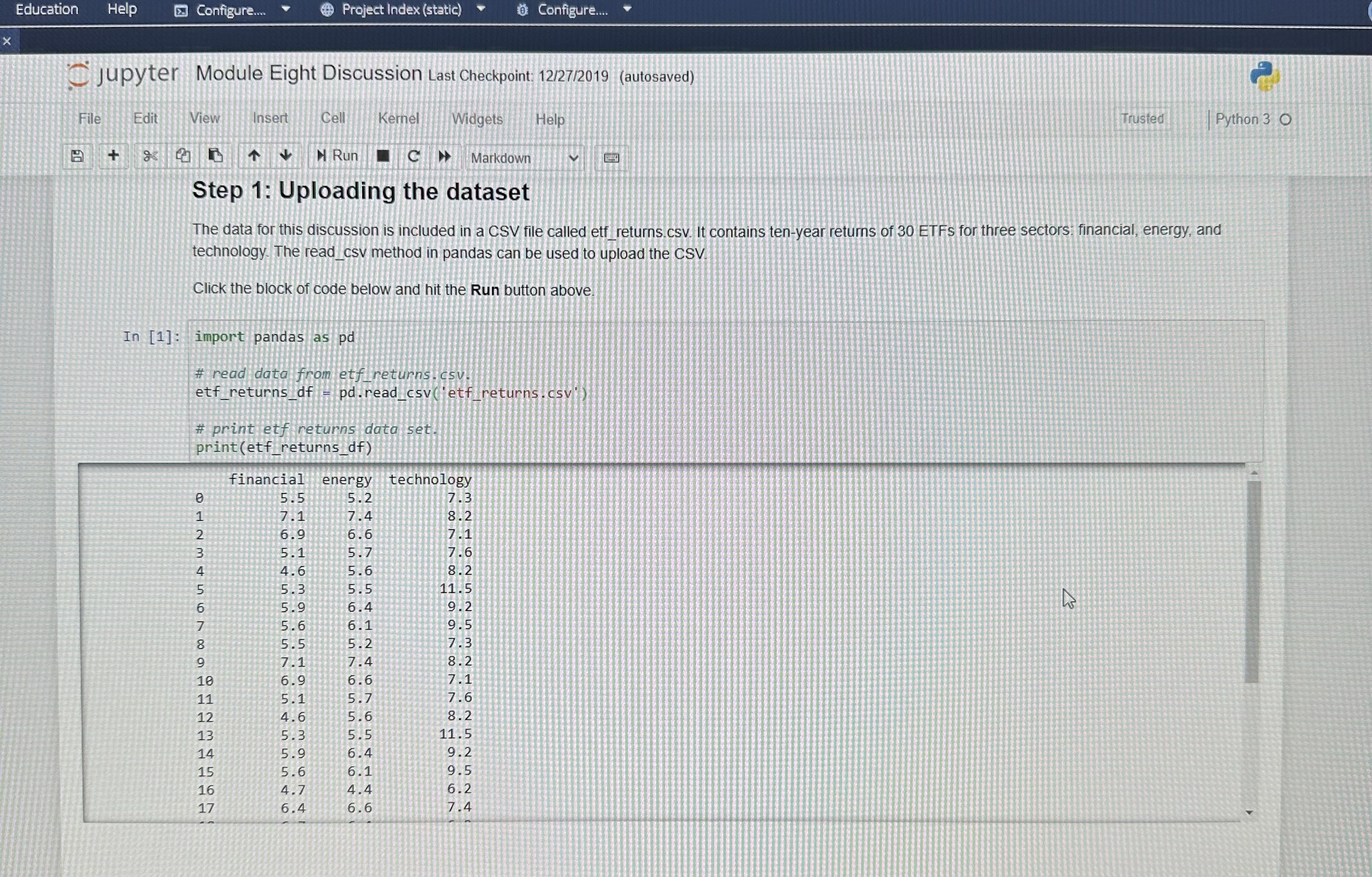
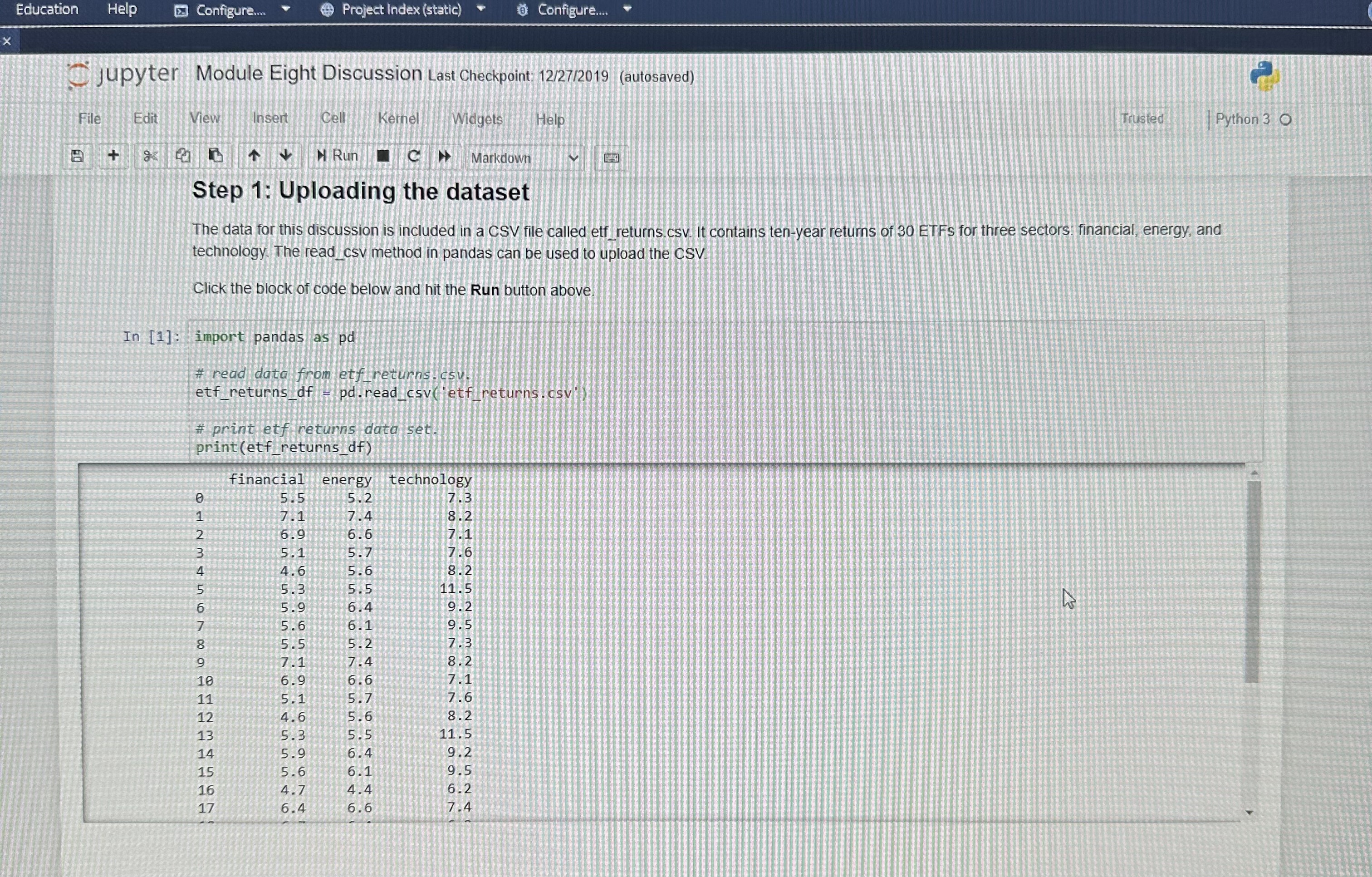
Education Help Configure. @ Project Index (static) Configure.. jupyter Module Eight Discussion Last Checkpoint: 12/27/2019 (autosaved Trusted Python 3 0 File Edit View Insert Cell Kernel Widgets Help at & |+ Run C Markdown Step 1: Uploading the dataset The data for this discussion is included in a CSV file called etf_returns.csv. It contains ten-year returns of 30 ETFs for three sectors. financial, energy, and technology. The read_csy method in pandas can be used to upload the CSV Click the block of code below and hit the Run button above. In [1] : import pandas as pd # read data from etf returns. csy etf_returns_df -pd. read_csvjetf_returns.csvi # print etf returns data set print (etf_returns_of) Financial energy technology 5.5 5.2 7.3 7.4 8.2 6. 6.6 7.1 5.7 7.6 4.6 5.6 8.2 5.5 11.5 5.9 6.4 9.2 5.6 6.1 9 .5 5.2 7 . 3 JOHANSSON NOUDWNHO 1 7.4 8 . 2 6.9 6.6 7.1 5 .7 7.6 4. 5 .6 8 . 2 in 5.3 11.5 5. 6.4 9 . 5 .6 9. 4.7 .4 6. .4 6.6 7.4Edit Find View Tools Education Help Configure. Project Index (static) Configure. DME.md Module Eight... > jupyter Module Eight Discussion Last Checkpoint: 12/27/2019 (autosaved) File Edit View Insert Cell Kernel Widgets Help Trusted Python 3 0 + H Run C > Markdown Zy 4.8 4.y F'AT Step 2: Performing one-way ANOVA The scipy stats submodule can be used to perform one-way analysis of variance (ANOVA). The method f_oneway is used to perform this test. The inputs are individual dataframes of all groups (in this discussion, groups are sectors). Click the block of code below and hit the Run button above. In [2]: import scipy . stats as st # save return data for individual sectors for input to f_oneway method. etf_returns_financial = etf_returns_df[ 'financial' ] etf_returns_energy = etf_returns_df[ 'energy' ] etf_returns_technology = etf_returns_of ['technology' ] # print the outputs: the test statistic and the P-value. test_statistic, p_value = st. f_oneway (etf_returns_financial, etf_returns_energy, etf_returns_technology) print("test statistic =", round(test_statistic, 2)) print ("P-value =", round(p_value, 4) ) test statistic = 55.07 P-value = 0.0sults | Course Hero * MAT 243 Project 2 Module 5.doc X MAT_243_Project_2_Module_5.d x DEL. 8-2 Jupyter Notebook (Discussion X C Codio - Module Eight Discussion X W ) MANFETTYWAP - Twitch x| + ule-eight-discussion/tree/Module%20Eight%20Discussion.ipynb A to G BR Tools Education Help Configure. Project Index (static) Configure. le Eight.. jupyter Module Eight Discussion Last Checkpoint: 12/27/2019 (autosaved) File Edit View Insert Cell Kernel Widgets Help Trusted | Python 3 0 B + 8 2 4 4 Run C > Markdown Step 3: Visualizing differences There are post-hoc tests available that can be used to identify groups that are significantly different than others. Alternatively, a quick approach to identifying differences is to create a visual plot for data distributions using side-by-side boxplots. The block of code below uses the seaborn module and matplotlib. pyplot submodule to create side-by-side boxplots for the ten-year returns of ETFs in financial, energy, and technology sector Click the block of code below and hit the Run button above. NOTE: If the graph is not created, click the code section and hit the Run button again. In [3]: import matplotlib. pyplot as plt import seaborn as sns import numpy as np import random # side by side boxplots require the three dataframes to be concatenated and a re identifying the type of ETF. etf_returns_financial_of =etf_returns_of[[ financial' ]] etf_returns_financial of ancial_of - etf_returns_financial_df. rename(columns-{"financial" etf_returns_financial_of[ ETF ] - 'financial' etf_returns_energy_of - etf_returns_of[ [ energy' ]] etf_returns_energy_of = etf_returns_energy_df. rename(columns={"energy"? "return"} etf_returns_energy_df['ETF ' ] = energy' etf_returns_technology_of = etf_returns_df[ ['technology ']] etf_returns_technology_df = etf_returns_technology_df. rename (columns-{"technology": "return" } etf_returns_technology_df['ETF' ] = 'technology. concatenate dataframes for the three ETFS. all_etfs_df = pd. concat( (etf_returns_financial_of, etf_returns_energy_of, etf_returns_technology_of) ) set a title for the plot, x-axis, and y-axis. pit. title('Boxplot for comparison', fontsize=20) # prepare the boxplot. sns . boxplot(x="ETF",y="return", data=all_etfs_df) show the plot. plt. show() Figure size 640x480 with 1 Axes WARSX SSHOLES LIVE FOREVER ST STAR TO 85
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance