

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
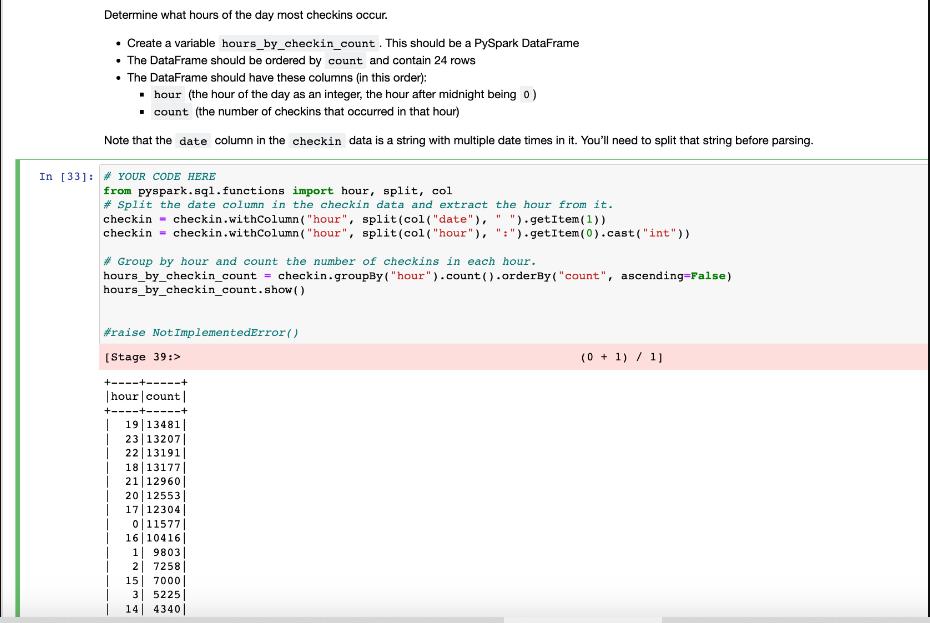
Determine what hours of the day most checkins occur. Create a variable hours_by_checkin_count. This should be a PySpark DataFrame The DataFrame should be ordered
![In [31]: assert type (hours_by_checkin_count) == pyspark.sql.dataframe.DataFrame,](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2023/09/64f2e50720e5c_1693639942153.jpg)
Determine what hours of the day most checkins occur. Create a variable hours_by_checkin_count. This should be a PySpark DataFrame The DataFrame should be ordered by count and contain 24 rows The DataFrame should have these columns (in this order): hour (the hour of the day as an integer, the hour after midnight being 0) count (the number of checkins that occurred in that hour) Note that the date column in the checkin data is a string with multiple date times in it. You'll need to split that string before parsing. In [33]: # YOUR CODE HERE from pyspark.sql.functions import hour, split, col #Split the date column in the checkin data and extract the hour from it. checkin "1 ").getItem(1)) checkin.withColumn ("hour", split(col ("date"), checkin= checkin.withColumn("hour", split(col ("hour"), ":").getItem(0).cast("int")) #Group by hour and count the number of checkins in each hour. hours_by_checkin_count = checkin.groupBy("hour").count().orderBy("count", ascending=False) hours_by_checkin_count.show() #raise NotImplementedError() [Stage 39:> +--- | hour count | +----+-----+ 1 19|13481| 23 13207| 22|13191| 18 13177 21 12960 20 12553 17|12304| 0|11577 | 16 10416 1 9803 | 2 7258 15 7000| 3 5225 14 4340 (0 + 1) / 1] In [31]: assert type (hours_by_checkin_count) == pyspark.sql.dataframe.DataFrame, \ "The hours_by_checkin_count variable should be a Spark DataFrame.' assert hours_by_checkin_count.columns == ["hour", "count"], \ "The columns are not in the correct order." submitted = AutograderHelper.parse_spark_dataframe (hours_by_checkin_count) In [32]: # Autograder cell. This cell is worth 1 point (out of 20). This cell does not contain hidden tests. assert len(submitted) == 24, \ "The hours_by_checkin_count DataFrame must have 24 rows." assert submitted [ "hour" ][0] == 1, \ 'The first row should have hour 1' AssertionError Cell In [32], line 6 1 # Autograder cell. This cell is 3 assert len (submitted) == 24, \ 4 11 Traceback (most recent call last) worth 1 point (out of 20). This cell does not contain hidden tests. "The hours_by_checkin_count DataFrame must have 24 rows." > 6 assert submitted [ "hour"][0] == 1, \ 7 'The first row should have hour 1' AssertionError: The first row should have hour 1 In [18] #Autograder cell. This cell is worth 4 points (out of 20). This cell contains hidden tests.
Step by Step Solution
★★★★★
3.50 Rating (157 Votes )
There are 3 Steps involved in it
Step: 1
appears that youre working with PySpark and trying to analyze checkin data to determine the ...
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Cost Management Measuring Monitoring And Motivating Performance
Authors: Leslie G. Eldenburg, Susan Wolcott, Liang Hsuan Chen, Gail Cook
2nd Canadian Edition
1118168879, 9781118168875