

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
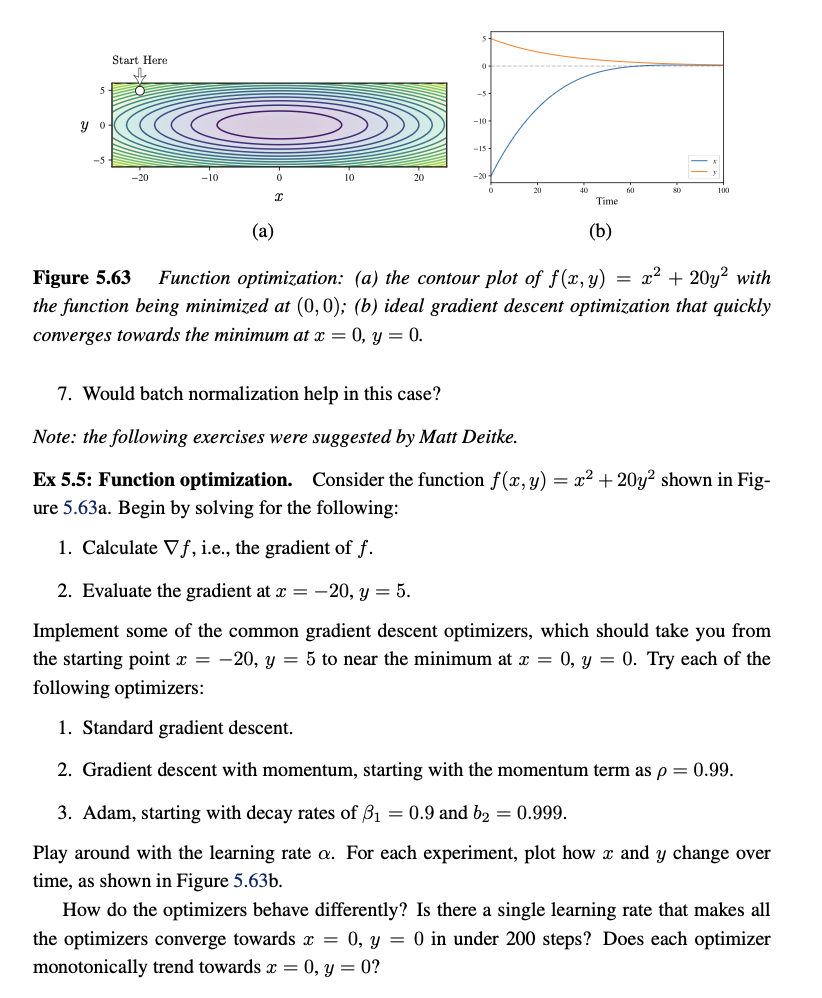
Ex 5 . 5 : Function optimization. Consider the function f ( x , y ) = x 2 + 2 0 y 2 shown
Ex : Function optimization. Consider the function shown in Fig
ure a Begin by solving for the following:
Calculate gradf, ie the gradient of
Evaluate the gradient at
Implement some of the common gradient descent optimizers, which should take you from
the starting point to near the minimum at Try each of the
following optimizers:
Standard gradient descent.
Gradient descent with momentum, starting with the momentum term as
Adam, starting with decay rates of and
Play around with the learning rate For each experiment, plot how and change over
time, as shown in Figure b
How do the optimizers behave differently? Is there a single learning rate that makes all
the optimizers converge towards in under steps? Does each optimizer
monotonically trend towards Figure Function optimization: a the contour plot of with
the function being minimized at ; ideal gradient descent optimization that quickly
converges towards the minimum at
Would batch normalization help in this case?
Note: the following exercises were suggested by Matt Deitke.
Ex : Function optimization. Consider the function shown in Fig
ure a Begin by solving for the following:
Calculate gradf, ie the gradient of
Evaluate the gradient at
Implement some of the common gradient descent optimizers, which should take you from
the starting point to near the minimum at Try each of the
following optimizers:
Standard gradient descent.
Gradient descent with momentum, starting with the momentum term as
Adam, starting with decay rates of and
Play around with the learning rate For each experiment, plot how and change over
time, as shown in Figure b
How do the optimizers behave differently? Is there a single learning rate that makes all
the optimizers converge towards in under steps? Does each optimizer
monotonically trend towards
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Real Time Database And Information Systems Research Advances
Authors: Azer Bestavros ,Victor Fay-Wolfe
1st Edition
1461377803, 978-1461377801