First let us look at quantity of coffee produced by these households. Below is a table of descriptive statistics for kilograms of coffee produced by
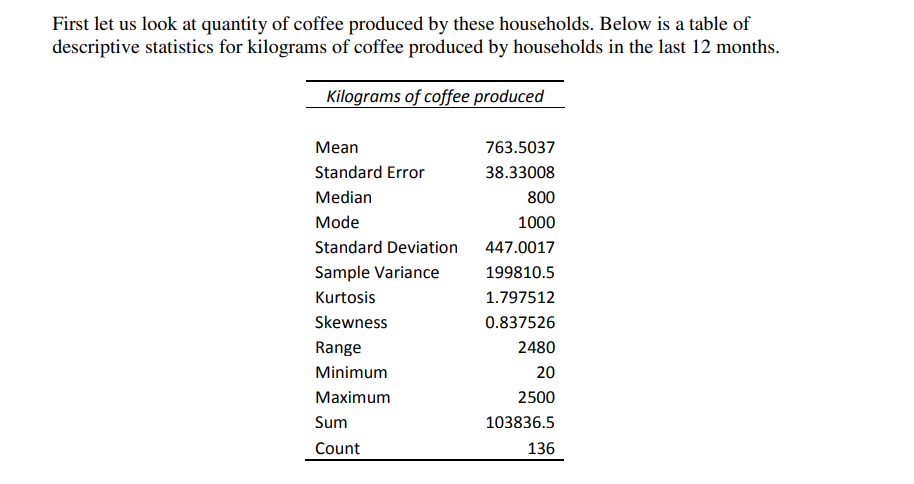
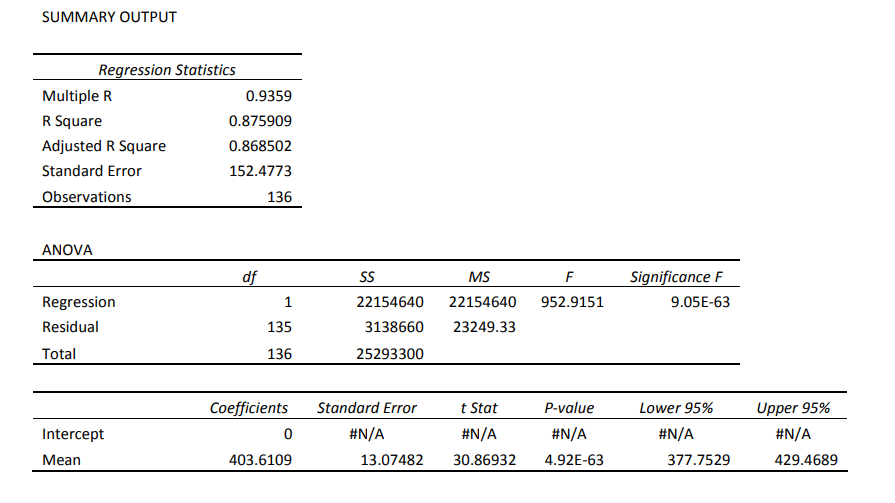
First let us look at quantity of coffee produced by these households. Below is a table of descriptive statistics for kilograms of coffee produced by households in the last 12 months. Kilograms of coffee produced Mean 763.5037 Standard Error 38.33008 Median 800 Mode 1000 Standard Deviation 447.0017 Sample Variance 199810.5 Kurtosis 1.797512 Skewness 0.837526 Range 2480 Minimum 20 Maximum 2500 Sum 103836.5 Count 136(a) Interpret the values for the Mean, Median and Mode. What do these three values tell you about the shape of the distribution for coffee production? (b) Interpret the Standard Deviation. Would you say this is large? Explain your reasoning. (c) There is actually a total of 187'r households in this sample, but only 136 of these grow coffee. Those that do not produce coffee have a blank for this variable, and so the Excel output above omits these blank values in the analysis [notice the Count is 135). In some data sets, these households may have had a \"0\" recorded instead of a blank. If this were the case here that is, we were to include these households with production =0 kilograms into the descriptive statistics what, if anything, would you expect to see happen to each of the Mean, Median, Mode and Standard Deviation? Explain your reasoning. A common standardisation used in measuring agricultural output is productivity relative to land area used. That is, a household's productivity in coffee production can be captured by: Yield = quantity of coffee produced in kilograms coffee land area in hectares {d} What does this standardisation allow us to compare? Give an example comparing 2 coffeeproducing households to illustrate. [e] The following regression output estimates mean yield [kilograms per hectare]. SUMMARY OUTPUT Regression Statistics Multiple R 0.9359 R Square 0.875909 Adjusted R Square 0.868502 Standard Error 152.4773 Observations 136 ANOVA df SS MS F Significance F Regression 1 22154640 22154640 952.9151 9.05E-63 Residual 135 3138660 23249.33 Total 136 25293300 Coefficients Standard Error t Stat P-value Lower 95% Upper 95% Intercept 0 #N/A #N/A #N/A #N/A #N/A Mean 403.6109 13.07482 30.86932 4.92E-63 377.7529 429.4689ii) iii} (iii) Interpret the values for the Mean under the Lower 95% and Upper 95% columns. In neighbouring SouthrEast Asian countries, coffee yield averages around 1000 kilograms per hectare. What does your answer to [1) tell you about the average yield of coffee-producing households in TimorLeste compared to other countries? The confidence interval you discussed in (i) is quite a wide interval. Explain intuitively the role of sample size (n) and standard deviation (0] in determining the width of a condence interval
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance