

Question: For my intro to coding with python class. Please help! Thank you! Start with the file HW5-2.py, which contains the appropriate code needed to use
For my intro to coding with python class. Please help! Thank you!
Start with the file HW5-2.py, which contains the appropriate code needed to use the nltk module function word_tokenize to break up each line of a file into words. Using the nltk module helps us deal with this task in an intelligent way, such as dealing with punctuation within the text.
Complete the program so that it performs a search and replace operation on an input file, producing an output file where the specified replacements have made.
The program should take 3 command line arguments, all of which should be required:
--input: the name of the input file containing the text to be processed
--replacements: a file containing replacements to be made, in the form
original=replacement
--output: the name of the file where the processed text should be stored
Your program should first read the contents of the file specified by the --replacements argument, storing the information in that file into a dictionary whose key is the original word, and whose value is the replacement word.
Next, each line of the input file should be read and tokenized using the word_tokenize function. Each word should then be checked to see if it should be replaced, and either the word or its replacement should be written to the output file.
Information on reading and writing files can be found in the textbook in chapter 6. I suggest using the for line in file pattern discussed at the end of section 6.1 in the textbook to read files the madlibs program we looked at in class uses this pattern. Using file.write()to write the output file is the easiest way to create the output file, and is described in section 6.2.
I have provided sample input and replacement files named calvin-hope-input.txt and calvin-hope-replacements.txt in the assignment folder. Heres the output your program should produce using these two files.
Hope College is one of the best places to attend college . Rooting for the Dutch makes you want to cheer , most of the time .
For this question, replacement patterns are case-sensitive. Also note the spaces before the periods at the end of each line and between the word cheer and the comma; you do not need to try to prevent that from occurring for this problem.
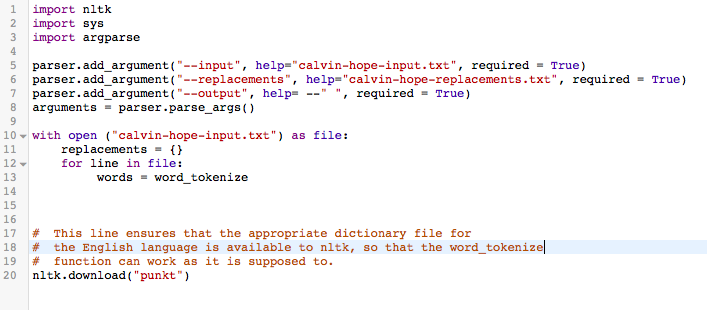
import nltk import sys import argparse parser.add_argument("--input", help="calvin-hope-input.txt", required = True) parser.add_argument("--replacements", help="calvin-hope-replacements.txt", required = True) parser.add_argument("--output", help= --" ", required = True) arguments = parser.parse_args() With open ("calvin-hope-input.txt") as file: replacements = {} for line in file: words = word_tokenize # This line ensures that the appropriate dictionary file for # the English language is available to nltk, so that the word_tokenize # function can work as it is supposed to. nltk.download("punkt") import nltk import sys import argparse parser.add_argument("--input", help="calvin-hope-input.txt", required = True) parser.add_argument("--replacements", help="calvin-hope-replacements.txt", required = True) parser.add_argument("--output", help= --" ", required = True) arguments = parser.parse_args() With open ("calvin-hope-input.txt") as file: replacements = {} for line in file: words = word_tokenize # This line ensures that the appropriate dictionary file for # the English language is available to nltk, so that the word_tokenize # function can work as it is supposed to. nltk.download("punkt")
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts