Help me Bigram - NLP: "Write code to count bigrams and their contexts", Write code to calculate probabilities of n-grams,

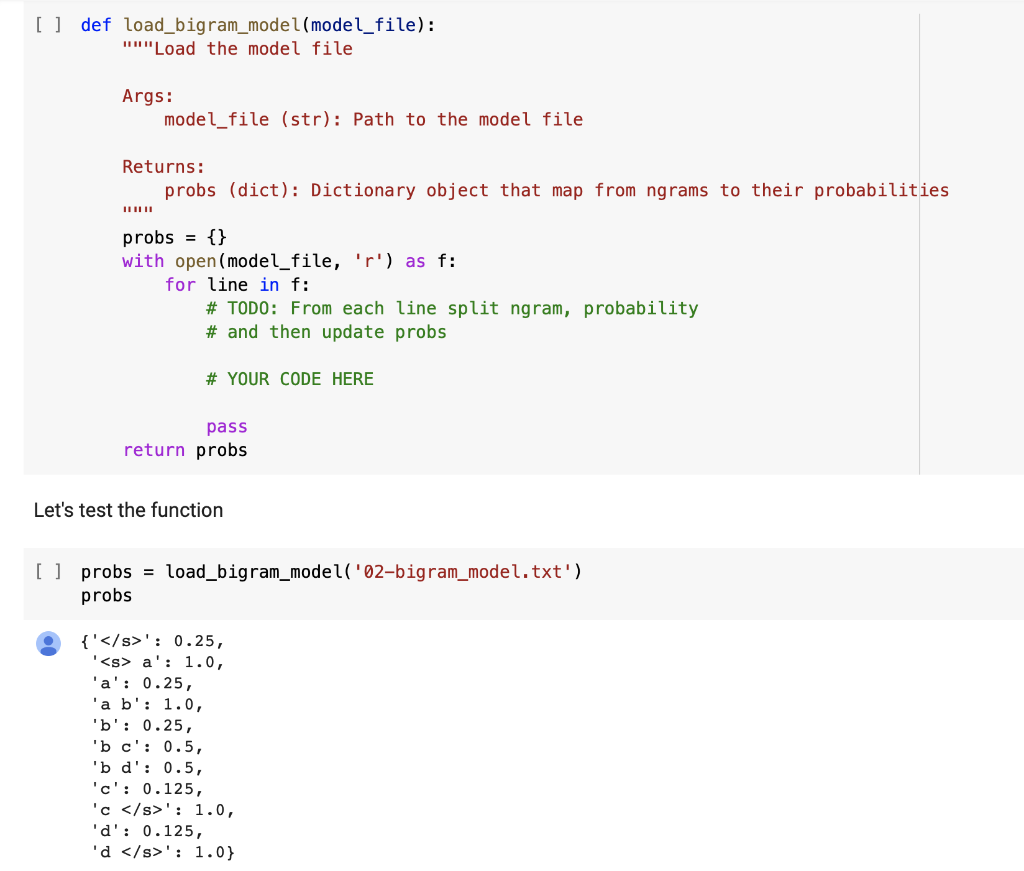 From each line split ngram, probability and then update probs
From each line split ngram, probability and then update probs
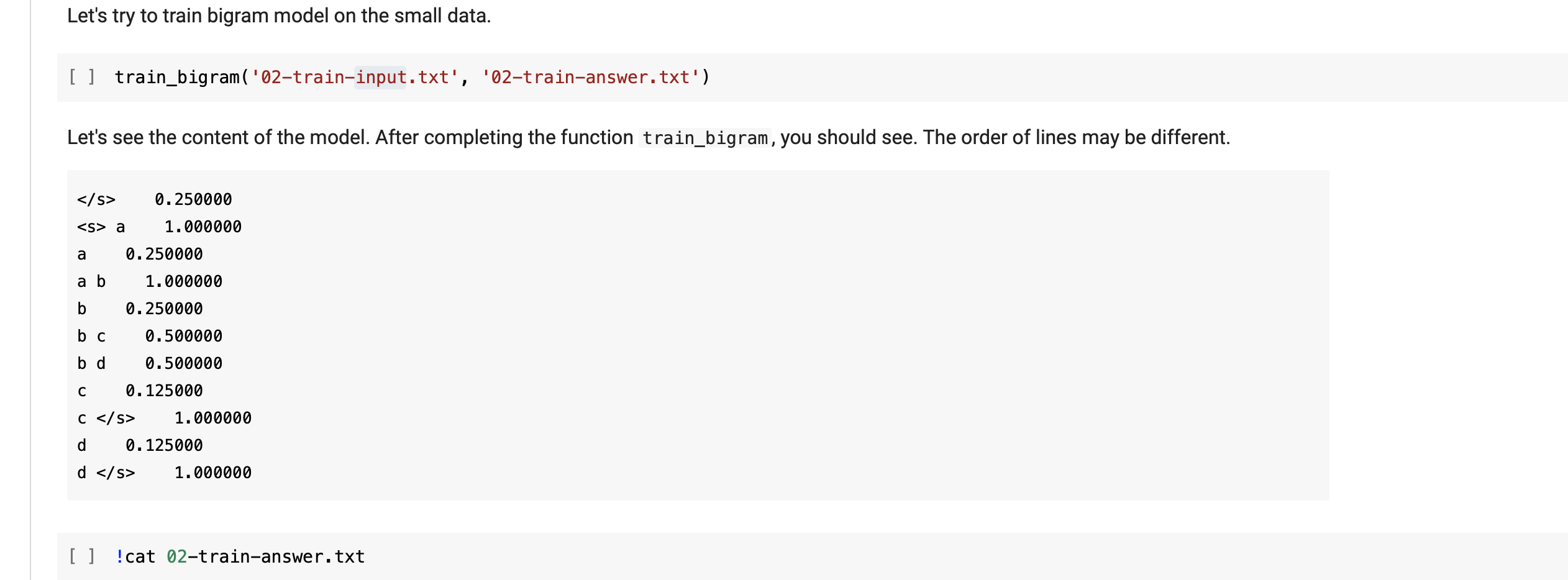
def train_bigram(train_file, model_file): """Train trigram language model and save to model file counts = defaultdict(int) # count the n-gram context_counts = defaultdict(int) # count the context with open(train_file) as f: for line in f: line = line.strip() if line == ": continue words = line.split() words.append('') words.insert(0, '
') for i in range(1, len(words)): # Note: starting at 1, after # TODO: Write code to count bigrams and their contexts # YOUR CODE HERE pass # Save probabilities to the model file with open(model_file, 'w') as fo: for ngram, count in counts.items(): # TODO: Write code to calculate probabilities of n-grams # (unigrams and bigrams) # Hint: probabilities of n-grams will be calculated by their counts # divided by their context's counts. # probability = counts [ngram]/context_counts [context] # After calculating probabilities, we will save ngram and probability # to the file in the format: # ngramprobability # YOUR CODE HERE pass Let's try to train bigram model on the small data. [ ] train_bigram( '02-train-input.txt', '02-train-answer.txt') Let's see the content of the model. After completing the function train_bigram, you should see. The order of lines may be different. 0.250000 a 1.000000 a 0.250000 a b 1.000000 b 0.250000 b c 0.500000 bd 0.500000 C 0.125000 1.000000 d 0.125000 d 1.000000 [] !cat 02-train-answer.txt [] def load_bigram_model(model_file): "Load the model file bigram model file Args: model_file (str): Path to the model file Returns: probs (dict): Dictionary object that map from ngrams to their probabilities probs = {} with open(model_file, 'r') as f: for line in f: # TODO: From each line split ngram, probability # and then update probs # YOUR CODE HERE pass return probs Let's test the function [] probs = load_bigram_model('02-bigram_model.txt') probs {'': 0.25, '
a': 1.0, 'a': 0.25, 'a b': 1.0, 'b': 0.25, 'bc': 0.5, 'b d': 0.5, 'c': 0.125, 'c ': 1.0, 'd': 0.125, 'd ': 1.0} def train_bigram(train_file, model_file): """Train trigram language model and save to model file counts = defaultdict(int) # count the n-gram context_counts = defaultdict(int) # count the context with open(train_file) as f: for line in f: line = line.strip() if line == ": continue words = line.split() words.append('') words.insert(0, '
') for i in range(1, len(words)): # Note: starting at 1, after # TODO: Write code to count bigrams and their contexts # YOUR CODE HERE pass # Save probabilities to the model file with open(model_file, 'w') as fo: for ngram, count in counts.items(): # TODO: Write code to calculate probabilities of n-grams # (unigrams and bigrams) # Hint: probabilities of n-grams will be calculated by their counts # divided by their context's counts. # probability = counts [ngram]/context_counts [context] # After calculating probabilities, we will save ngram and probability # to the file in the format: # ngramprobability # YOUR CODE HERE pass Let's try to train bigram model on the small data. [ ] train_bigram( '02-train-input.txt', '02-train-answer.txt') Let's see the content of the model. After completing the function train_bigram, you should see. The order of lines may be different. 0.250000 a 1.000000 a 0.250000 a b 1.000000 b 0.250000 b c 0.500000 bd 0.500000 C 0.125000 1.000000 d 0.125000 d 1.000000 [] !cat 02-train-answer.txt [] def load_bigram_model(model_file): "Load the model file bigram model file Args: model_file (str): Path to the model file Returns: probs (dict): Dictionary object that map from ngrams to their probabilities probs = {} with open(model_file, 'r') as f: for line in f: # TODO: From each line split ngram, probability # and then update probs # YOUR CODE HERE pass return probs Let's test the function [] probs = load_bigram_model('02-bigram_model.txt') probs {'': 0.25, '
a': 1.0, 'a': 0.25, 'a b': 1.0, 'b': 0.25, 'bc': 0.5, 'b d': 0.5, 'c': 0.125, 'c ': 1.0, 'd': 0.125, 'd ': 1.0}




