Hi, I need help with this assignment, I have seen the previous question but they are not answered well enough. I need proper implementation as required, I am providing all the required information, Please don't break any requirements. Need this ASAP.

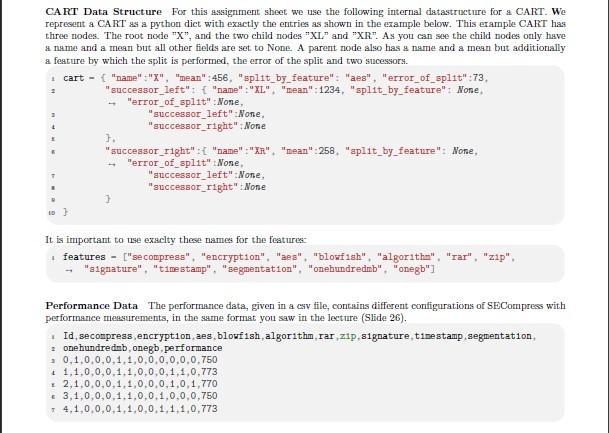
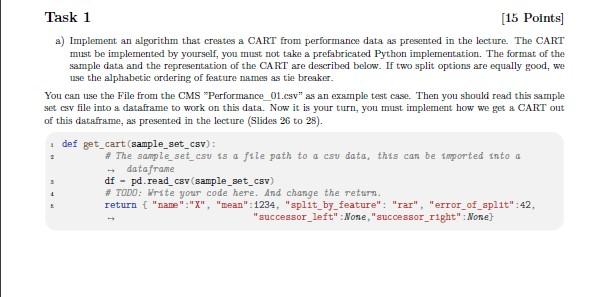
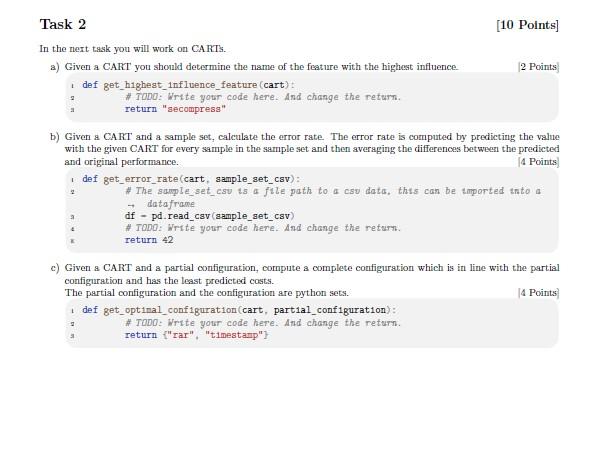
In this assignment, we analyze a non-functional property, performance, of a fictional tool "SECompress", a configurable command-line tool for compressing data. In addition, the data can be encrypted, signed, segmented, and/or timestamped. All this functionality is modeled by the feature diagram in Figure 4 For all the tasks in this Assignment we will use this tool with the festures given in this diagram. \begin{tabular}{|l|} \hline Legend: \\ Abstract Feature \\ Concrete Feature \\ Mandatory \\ Optional \\ A Alternative Group \\ \hline \end{tabular} Figure 1: The Feature Diagram of "SECompress" Jupyter Notebook You have to implement your solution using the provided .Jupyter Notebook "Template Assignment 04.ipynb" that can be downlosded from the CMS. - This Jupyter Notebook contains comments where your implementation goes, marked with "TODO" - It contains example test cases. For the tests, you need to download the "* esv" files from the material section in the CMS snd save them in the same folder. - No additional imports are allowed, otherwise your submission is invalid and leads to a desk reject. - No additional libraries are allowed, otherwise your submission is invalid and leads to a desk reject. - No changing of signatures is allowed, otherwise your submission is invalid and leads to a desk reject. To use the Jupyter Notebook Template you need to install Juypter. You can use the install guideline https: //1upyter.org/1nstall of Jupyter, but on Windows we recommend using Anaconda to use .Jupyter https://docs. anaconda.com/ae-notebooks/user-pu1de/bas1c-tasks/apps/1upyter/1ndex.html. If you encounter any problems try googling them, there are lots of tutorials and forum discussions already online Otherwise you can use the SE forum, but plesse try to google it on your own first. CA RT Data Structure For this assignment sheet we use the following internal datastructure for a CART. We represent a CART as a python dict with exactly the entries as shown in the example below. This erarnple CAFT has three nodes. The root node " X ", and the two child nodes "XL" and "XR". As you can see the child nodes ouly have a name and a mean but all other fields are set to None. A parent node also has a name and a mean but additionally a feature by which the split is performed, the error of the split and two sucessors. It is important to nuse exaclty these names for the features: features - ["secompress", "encryption", "aes", "blowf1sh", "algorithm", "rar", "z1p", - "signature", "t1mestamp", "segmentation", "onehundrednb", "onegb"] Performance Data The performance data, given in a csv file, contains different configurations of SECompress with performance measurements, in the same format you saw in the lecture (Slide 26). Id, secompress, encryption, aes, blowfish, algorithm, rar, z1p, signature, tinestamp, segmentat1on, = onehundrednb, onegb, perf ormance a 0,1,0,0,0,1,1,0,0,0,0,0,0,750 i 1,1,0,0,0,1,1,0,0,0,1,1,0,773 = 2,1,0,0,0,1,1,0,0,0,1,0,1,770 \& 3,1,0,0,0,1,1,0,0,1,0,0,0,750 i 4,1,0,0,0,1,1,0,0,1,1,1,0,773 Task 1 [15 Points] a) Implement an algorithm that creates a CART from performance data as presented in the lecture. The CART must be implemented by yourself, you must not taku a prefabricated Python implementation. The format of the sample data and the representation of the CART are described below. If two split options are equally good, we use the alphabetic ordering of feature names as tie breaker. You can use the File from the CMS "Performance_01.esv" as an example test case. Then you should read this sample set csv file into a dataframe to work on this data. Now it is your turn, you must implement how we get a CART out of this dataframe, as presented in the lecture (Slides 26 to 28 ). Mask 2 [10 Points] In the next task you will work on CARTs. a) Given a CART you should determine the name of the feature with the highest influence 2 Points) i def get_h1ghest_ 1 nfluence_feature (cart): 2 a DoDo: Write your code here. And change the return. return "secompresa" b) Given a CART and a sample set, calculate the error rate. The error rate is computed by predicting the value with the given CART for every sample in the sample set and then averaging the differences between the predicted and original performance. [4. Points] c) Given a CART and a partial configuration, compute a complete configuration which is in line with the partial configuration and has the least predicted costs. The partial configuration and the configuration are python sets. [4 Points) def get_opt1na1_configuration(cart, part1al_configuration) : \# TODD: Write your code here. And change the return. return "rar", "timestamp




