

Question
I am attempting to answer thefollowing: Utilize your Python environment to derive structure fromunstructured data. You will utilize the data set AirlineSentiment from Kaggle located
I am attempting to answer thefollowing:
Utilize your Python environment to derive structure fromunstructured data. You will utilize the data set "AirlineSentiment" from Kaggle located at Kaggles website. From Welkin10,the dataset "Airline Sentiment". /welkin10/airline-sentinment
Using this data set, you will create a text analytics Pythonapplication that extracts themes from each comment using termfrequency?inverse document frequency (TF?IDF) or simple wordcounts. For the deliverable, provide your Python file and a .csvwith your results added as a column to the original data set.
I have the following code:
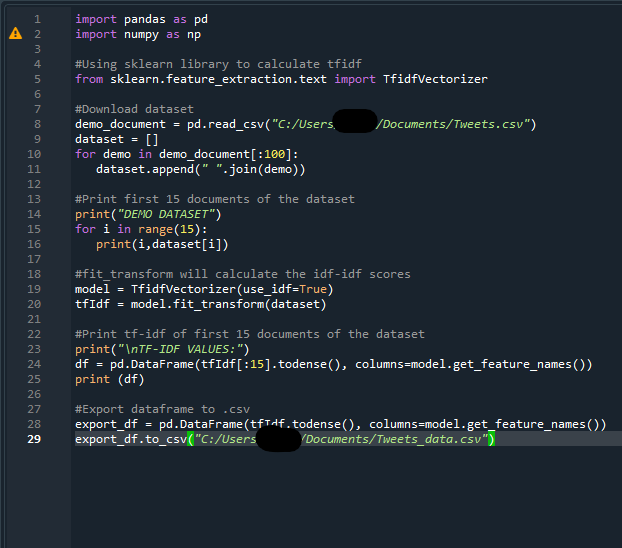
import pandas as pdimport numpy as np
#Using sklearn library to calculate tfidffrom sklearn.feature_extraction.text import TfidfVectorizer
#Download datasetdemo_document =pd.read_csv("C:/Users/Documents/Tweets.csv") dataset = []for demo in demo_document[:100]: dataset.append(" ".join(demo))
#Print first 15 documents of the datasetprint("DEMO DATASET")for i in range(15): print(i,dataset[i])
#fit_transform will calculate the idf-idf scoresmodel = TfidfVectorizer(use_idf=True)tfIdf = model.fit_transform(dataset)
#Print tf-idf of first 15 documents of the datasetprint("TF-IDF VALUES:")df = pd.DataFrame(tfIdf[:15].todense(),columns=model.get_feature_names())print (df)
#Export dataframe to .csvexport_df = pd.DataFrame(tfIdf.todense(),columns=model.get_feature_names())export_df.to_csv("C:/Users/Documents/Tweets_data.csv")
I am receiving the following error:
ValueError: empty vocabulary; perhaps the documents only containstop words.
How do I go about resolving this error?
Hami ND000 HN 1 A 2 3 4 5 6 7 8 9 10 11 12 13 998722ZHONG 20 21 23 import pandas as pd import numpy as np 14 15 16 17 18 #fit_transform will calculate the idf-idf scores 19 model = TfidfVectorizer (use_idf=True) tfIdf = model.fit_transform(dataset) 24 #Using sklearn library to calculate tfidf from sklearn.feature_extraction.text import TfidfVectorizer 26 #Download dataset demo_document = pd.read_csv ("C:/Users dataset= [] for demo in demo_document[:100]: dataset.append(" ".join(demo)) #Print first 15 documents of the dataset print("DEMO DATASET") for i in range(15): print(i, dataset[i]) /Documents/Tweets.csv") df = pd.DataFrame(tfIdf[:15].todense(), columns=model.get_feature_names()) 25 print (df) #Print tf-idf of first 15 documents of the dataset print(" TF-IDF VALUES: ") #Export dataframe to .cs .csv export_df = pd.DataFrame(tff.todense(), columns=model.get_feature_names ()) export_df.to_csv ("C:/Users /Documents/Tweets_data.csv")
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Below is the code to copy CODE STARTS HERE import pandas as pd from sklearnfeatureextractio...
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Microeconomics An Intuitive Approach with Calculus
Authors: Thomas Nechyba
1st edition
538453257, 978-0538453257