

Question
I am looking for my python script to be interpreted, therefore, please address the following items: Define the null and alternative hypothesis in mathematical terms
I am looking for my python script to be interpreted, therefore, please address the following items:
- Define the null and alternative hypothesis in mathematical terms and in words.
- Report the level of significance.
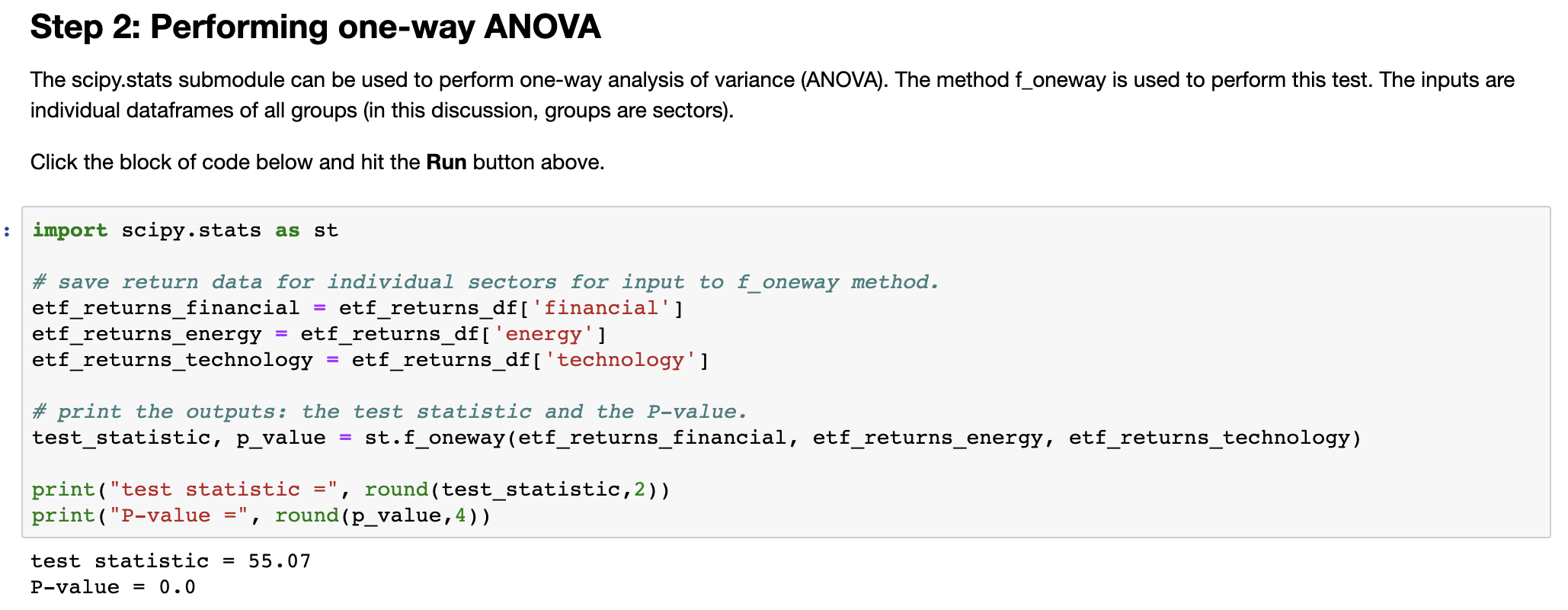
- Include the test statistic and the P-value. See Step 2 in the Python script.
- Provide your conclusion and interpretation of the test. Should the null hypothesis be rejected? Why or why not?
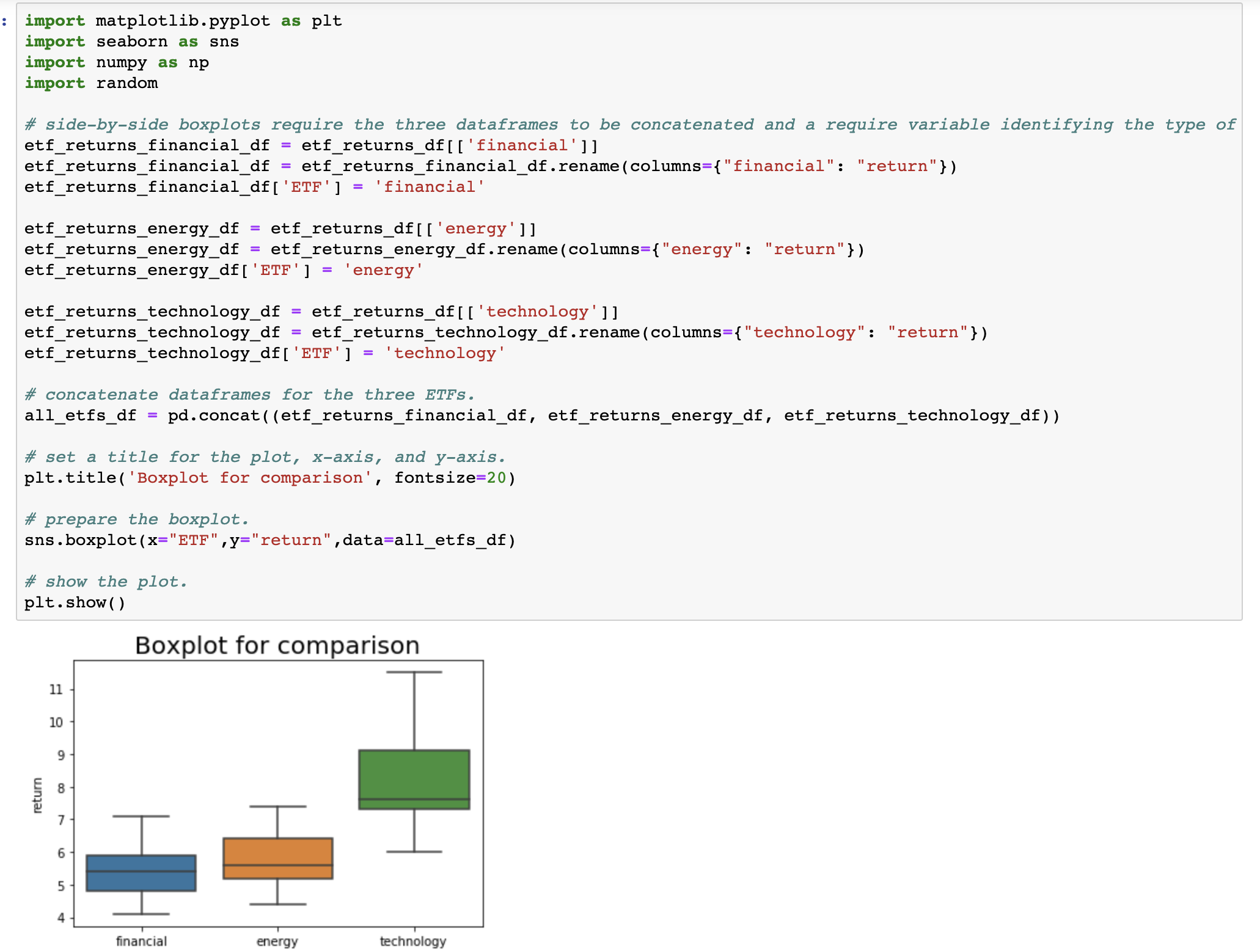
- Does a side-by-side boxplot of the 10-year returns of ETFs from the three sectors confirm your conclusion of the hypothesis test? Why or why not? See Step 3 in the Python script.
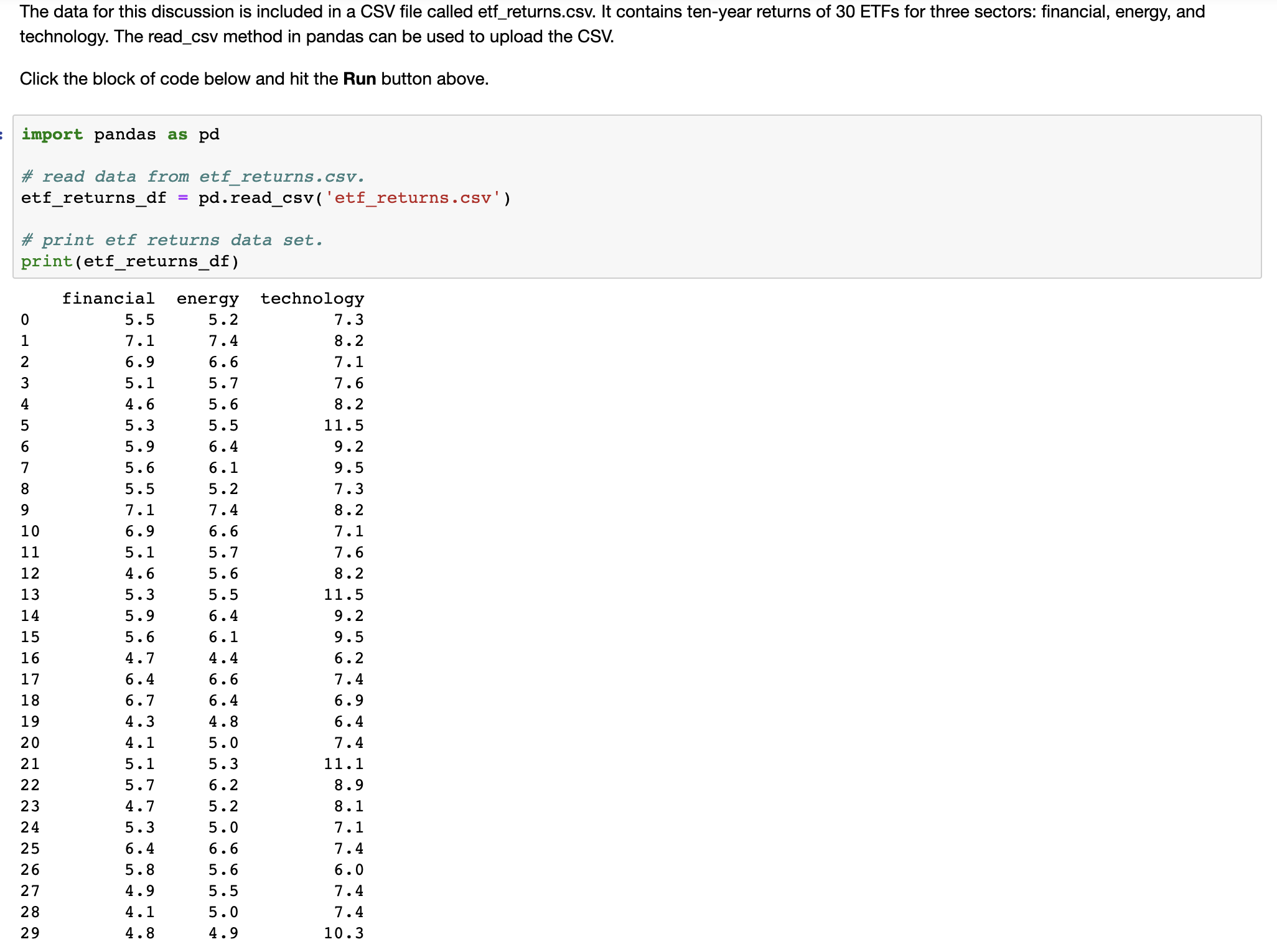
Step 1: Uploading the dataset
The data for this discussion is included in a CSV file called etf_returns.csv. It contains ten-year returns of 30 ETFs for three sectors: financial, energy, and technology. The read_csv method in pandas can be used to upload the CSV.
import pandas as pd
?
# read data from etf_returns.csv.
etf_returns_df = pd.read_csv('etf_returns.csv')
?
# print etf returns data set.
print(etf_returns_df)
financialenergytechnology
05.55.27.3
17.17.48.2
26.96.67.1
35.15.77.6
44.65.68.2
55.35.511.5
65.96.49.2
75.66.19.5
85.55.27.3
97.17.48.2
106.96.67.1
115.15.77.6
124.65.68.2
135.35.511.5
145.96.49.2
155.66.19.5
164.74.46.2
176.46.67.4
186.76.46.9
194.34.86.4
204.15.07.4
215.15.311.1
225.76.28.9
234.75.28.1
245.35.07.1
256.46.67.4
265.85.66.0
274.95.57.4
284.15.07.4
294.84.910.3
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
The Structure Of Groups With A Quasiconvex Hierarchy (AMS-209)
Authors: Daniel T Wise
1st Edition
069121350X, 9780691213507