

Question
I have the code, Can you debugged it to meet the following requirements? You can use any sentence to test, I will then tested
I have the code, Can you debugged it to meet the following requirements?
You can use any sentence to test, I will then tested with the ones I created.
* Please do not change the structure of the function drastically. I need to learn how to work the Buggs on it, if you change or if you create your own better version, it it wont be the same.
If I run it as it its the first bug is about the object does not have attribute count.
I did divide using list() so not sure why is this happening.
- Once that is done, run it again and If there is another bug fix that one two. This lesson is about debugging the function.
I have already have my samples of the sentences to read, I just need a functioning code to test it against.
Can you please help me with the bugs and explain me how you resolved them for future references?
def count_letter_e(loc, count_accented = True, count_uppercase = True): # Open and read the file with open(loc+".txt", encoding = "utf-8") as test_file: text = test_file.read() test_file = test_file.list()#to change from objet # List of all e's to look for e_list = ['e', 'é', 'ê', 'è', 'E', 'É', 'Ê', 'È'] #dictionary with all e counts letter_counts = {} for e in e_list: letter_counts[e] = test_file.count('e') # Variable that will return the desired integer sum_counts = 0 if count_uppercase and count_accented: # When ignoring everything, we want to add up all the counts text = text.lower() sum_counts = sum(letter_counts) elif count_accented == True and count_uppercase == False: # When ignoring accents, we want to add up the relevant counts e_counts = [letter_counts[ell] for ell in e_list] sum_counts = sum(e_counts) elif count_uppercase == False and count_accented == True: # When ignoring case, we want to add up the relevant counts e_counts = [letter_counts[ell] for ell in e_list] sum_counts = sum(e_counts) elif count_uppercase == False and count_accented == False: # When not ignoring anything, we want to count the 'e's count = text.count('e') return(sum_counts)

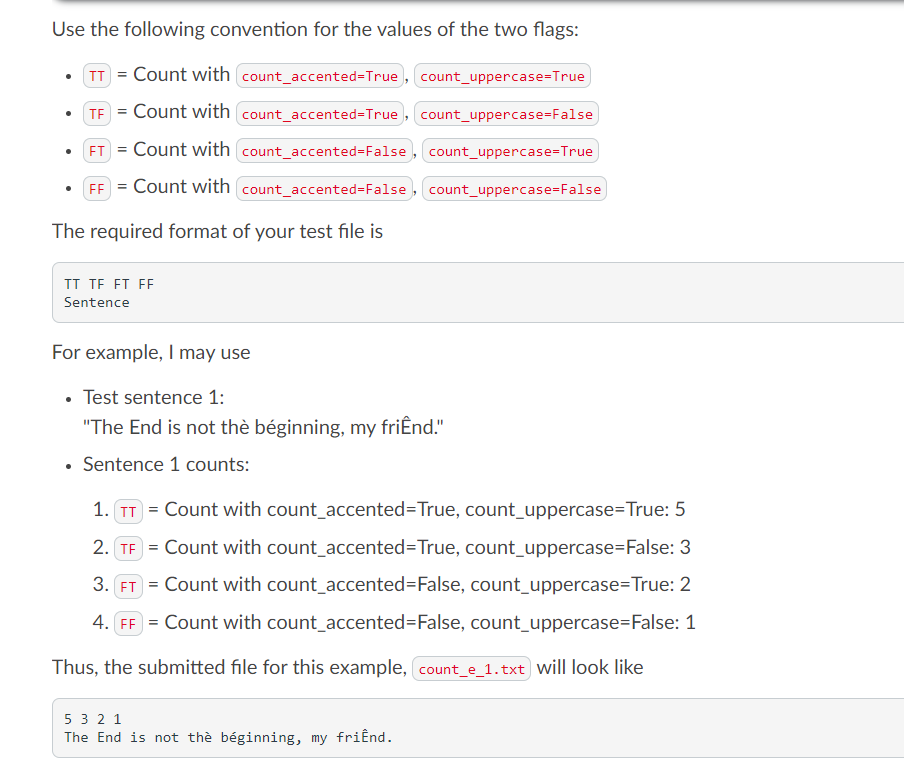

Input: o o O loc - a filename as a string with extension ".txt" count_accented) - a boolean value indicating if e is to be counted the same as e.g. (default: True) - all accented e's are counted as a regular unaccented e) count_uppercase - a boolean value indicating if capitalized E's are to be counted in addition to lowercase e's (default: True all uppercase e's are counted as well as lowercase) Output: The count of e's in the text following the rules of the accents and cases.
Step by Step Solution
There are 3 Steps involved in it
Step: 1
a Critically damped system The steadystate error for a critically damped system can be calculated us...
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Income Tax Fundamentals 2013
Authors: Gerald E. Whittenburg, Martha Altus Buller, Steven L Gill
31st Edition
1111972516, 978-1285586618, 1285586611, 978-1285613109, 978-1111972516