
#ifndef GITINT_H #define GITINT_H #include diffs_; CommitIdx parent_; /** * Completed constructor * * @param[in] msg * Log message for this commit. * @param[in] diffs * Map containing the filename (key) and integer *difference* * of the file from the parent commit. * @param[in] parent * Index of the parent commit. */ CommitObj( const std::string& msg, std::map<:string int> diffs, CommitIdx parent) : msg_(msg), diffs_(diffs), parent_(parent) {} }; /** * @brief Class to model 'git' for files containing integers */ class GitInt { public: /** * Default constructor * [TO BE WRITTEN] */ GitInt(); /** * Prints the menu of command options. * [COMPLETED] */ void print_menu() const; /** * Processes/executes a line of input (i.e. one command with its options) * [TO BE WRITTEN] * * @param[in] cmd_line * String containing the entire command line to be processed * @returns 'true' if the "quit" command was entered, 'false' otherwise * @throws std::invalid_argument or std::runtime_error */ bool process_command(std::string cmd_line); /** * Creates a new file with the given value * [TO BE WRITTEN] * * @param[in] filename * Name of the file to be created * @param[in] value * Integer content of the file * @throws std::invalid_argument or std::runtime_error - * See homework writeup for details on error cases */ void create(const std::string& filename, int value); /** * Modifies the given file to a new value * [TO BE WRITTEN] * * @param[in] filename * Name of the file to be edited * @param[in] value * New integer content of the file * @throws std::invalid_argument or std::runtime_error - * See homework writeup for details on error cases */ void edit(const std::string& filename, int value); /** * Displays the current contents of the given file * [TO BE WRITTEN] * * @param[in] filename * Name of the file to be edited * @throws std::invalid_argument - * See homework writeup for details on error cases */ void display(const std::string& filename) const; /** * Displays the current content of all files * [TO BE WRITTEN] * */ void display_all() const; /** * Displays the contents of the given commit's diff map * [COMPLETED] * * @param[in] commit * Index of the commit to display * @throws std::invalid_argument - * See homework writeup for details on error cases */ void display_commit(CommitIdx commit) const; /** * Stages the given file for commit * [TO BE WRITTEN] * * @param[in] filename * File to be staged and committed on the next commit command * @throws std::invalid_argument or std::runtime_error - * See homework writeup for details on error cases */ void add(std::string filename); /** * Commits all files staged since the last commit * [TO BE WRITTEN] * * @param[in] message * Log message for this commit * @throws std::runtime_error - * See homework writeup for details on error cases */ void commit(std::string message); /** * Associates a new tag name to the currently checked-out commit * [TO BE WRITTEN] * * @param[in] tagname * Name for this tag * @param[in] commit * Commit number/index to associate with the given tagname * @throws std::invalid_argument or std::runtime_error - * See homework writeup for details on error cases */ void create_tag(const std::string& tagname, CommitIdx commit); /** * Displays all tag names in the order they were created from most * to least recent. * [TO BE WRITTEN] * */ void tags() const; /** * Updates the files and content to match the state of the given commit * [TO BE WRITTEN] * * @param[in] commit * Index of the commit to checkout * @throws std::invalid_argument or std::runtime_error - * See homework writeup for details on error cases */ bool checkout(CommitIdx commitIndex); /** * Updates the files and content to match the state of the given commit * [TO BE WRITTEN] * * @param[in] tag * Tag name associated with the commit to checkout * @throws std::invalid_argument or std::runtime_error - * See homework writeup for details on error cases */ bool checkout(std::string tag); /** * Displays the commit numbers and log message in order from the current * checked-out commit back through all parent/ancestor commits. * [TO BE WRITTEN] * * @throws std::invalid_argument or std::runtime_error - * See homework writeup for details on error cases */ void log() const; /** * Display the file content differences between the current state back * through all parent/ancestor commits until the `to` commit * [TO BE WRITTEN] * * @param[in] to * Index of the commit to end the diff process * @throws std::invalid_argument - * See homework writeup for details on error cases */ void diff(CommitIdx to) const; /** * Display the file content differences between commit `from` back * through all parent/ancestor commits until the `to` commit * [TO BE WRITTEN] * * @param[in] from * Index of the commit to start the diff process * @param[in] to * Index of the commit to end the diff process * @throws std::invalid_argument - * See homework writeup for details on error cases */ void diff(CommitIdx from, CommitIdx to) const; /** * Returns true if the given input is a valid commit number * [TO BE WRITTEN] * @param[in] commit */ bool valid_commit(CommitIdx commit) const; private: /** * Builds the file state between commit 'from' until 'to' (exclusive) * [OPTIONAL - TO BE WRITTEN] * * @param[in] from * Index of the commit to start the accrual of diffs * @param[in] to * Index of the commit to end the accrual of diffs * @throws may vary depending on implementation */ std::map<:string int> buildState(CommitIdx from, CommitIdx to = 0) const; /** * Displays a map containing filenames and contents in the desired format * [COMPLETED] * * @param[in] dat * Filename and values map to print */ void display_helper(const std::map<:string int>& dat) const; /** * Displays a single commit in the desired log format * [COMPLETED] * * @param[in] commit_num * Index of the commit to be printed * @param[in] msg * Log message of the commit to be printed */ void log_helper(CommitIdx commit_num, const std::string& log_message) const; // Add data members here }; #endif
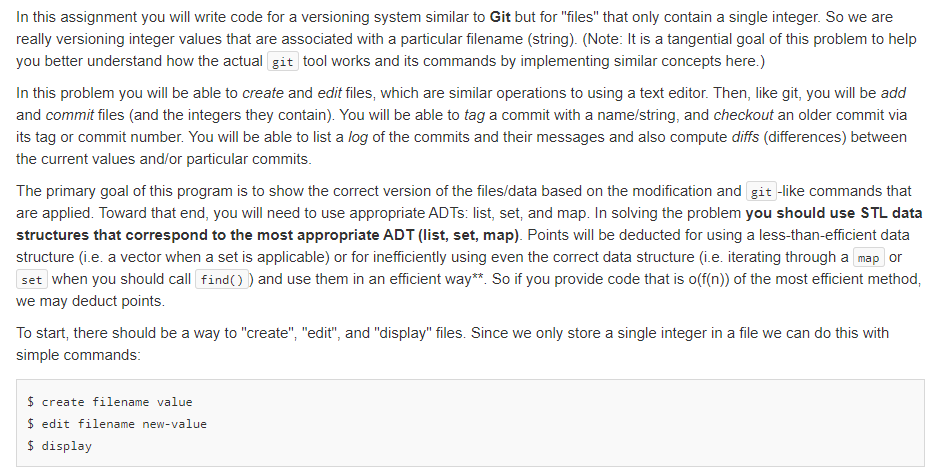
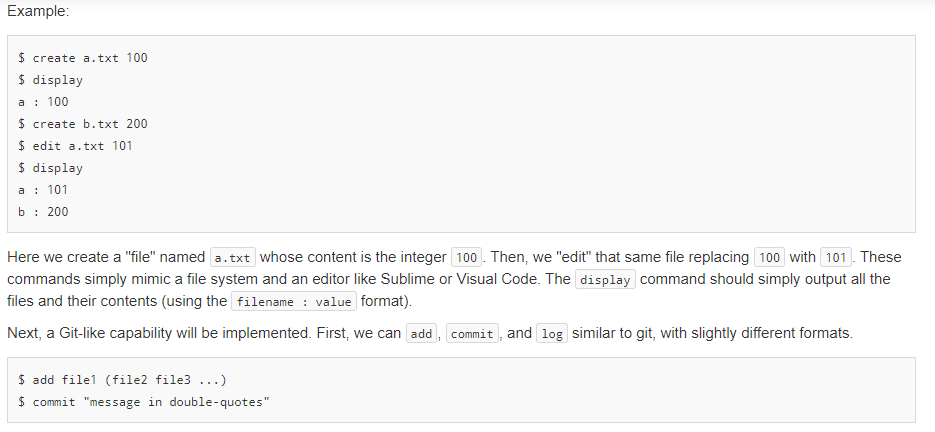
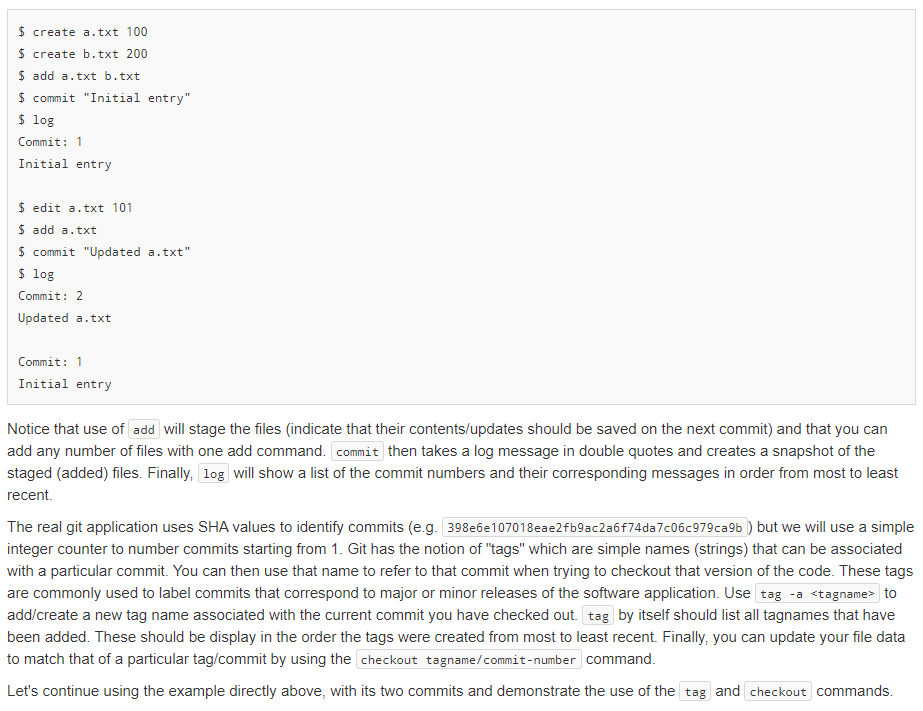
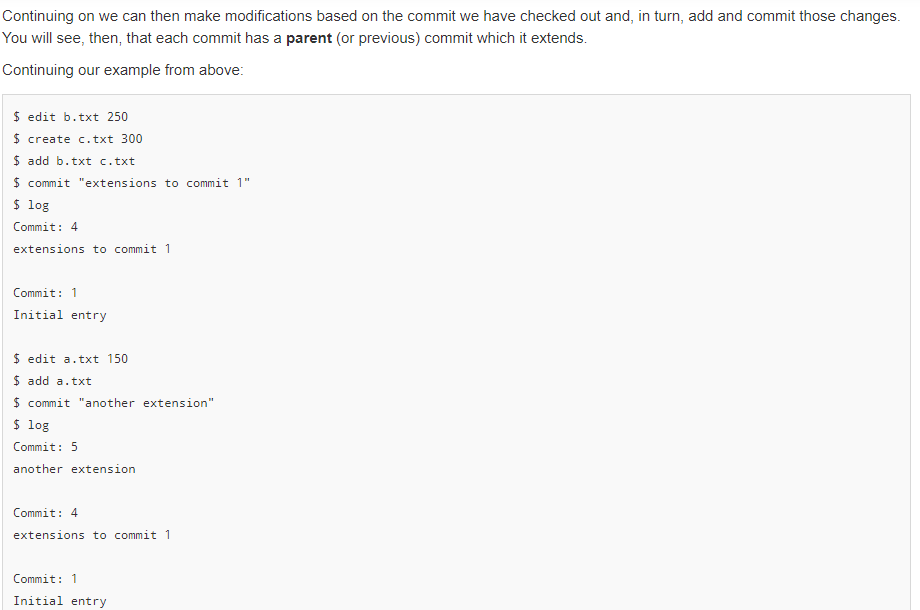
In this assignment you will write code for a versioning system similar to Git but for "files" that only contain a single integer. So we are really versioning integer values that are associated with a particular filename (string). (Note: It is a tangential goal of this problem to help you better understand how the actual git tool works and its commands by implementing similar concepts here.) In this problem you will be able to create and edit files, which are similar operations to using a text editor. Then, like git, you will be add and commit files and the integers they contain). You will be able to tag a commit with a name/string, and checkout an older commit via its tag or commit number. You will be able to list a log of the commits and their messages and also compute diffs (differences) between the current values and/or particular commits. The primary goal of this program is to show the correct version of the files/data based on the modification and git -like commands that are applied. Toward that end, you will need to use appropriate AD Ts: list, set, and map. In solving the problem you should use STL data structures that correspond to the most appropriate ADT (list, set, map). Points will be deducted for using a less-than-efficient data structure (i.e. a vector when a set is applicable) or for inefficiently using even the correct data structure (i.e. iterating through a map or set when you should call find ) and use them in an efficient way** So if you provide code that is o(f(n)) of the most efficient method, we may deduct points. To start, there should be a way to create", "edit", and "display" files. Since we only store a single integer in a file we can do this with simple commands: $ create filename value $ edit filename new-value $ display Example: $ create a.txt 100 $ display a : 100 $ create b.txt 200 $ edit a.txt 101 $ display a : 101 b: 200 Here we create a "file" named a.txt whose content is the integer 100. Then, we "edit" that same file replacing 100 with 101. These commands simply mimic a file system and an editor like Sublime or Visual Code. The display command should simply output all the files and their contents (using the filename : value format). Next, a Git-like capability will be implemented. First, we can add , commit, and log similar to git, with slightly different formats. $ add filei (file2 file3 ...) $ commit "message in double-quotes" $ create a.txt 100 $ create b.txt 200 $ add a.txt b.txt $ commit "Initial entry" $ log Commit: 1 Initial entry $ edit a.txt 101 $ add a.txt $ commit "Updated a.txt" $ log Commit: 2 Updated a.txt Commit: 1 Initial entry Notice that use of add will stage the files indicate that their contents/updates should be saved on the next commit) and that you can add any number of files with one add command. commit then takes a log message in double quotes and creates a snapshot of the staged (added) files. Finally, log will show a list of the commit numbers and their corresponding messages in order from most to least recent. The real git application uses SHA values to identify commits (e.g. 398e6e107018eae2fb9ac2a6f74da7c06c979ca9b ) but we will use a simple integer counter to number commits starting from 1. Git has the notion of "tags" which are simple names (strings) that can be associated with a particular commit. You can then use that name to refer to that commit when trying to checkout that version of the code. These tags are commonly used to label commits that correspond to major or minor releases of the software application. Use tag -a
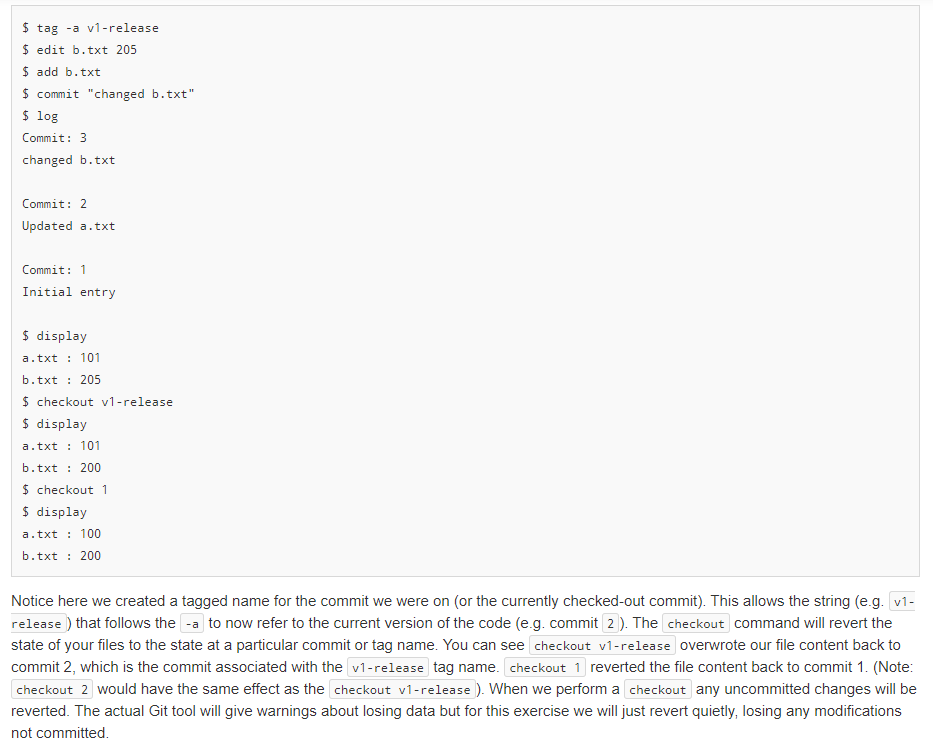
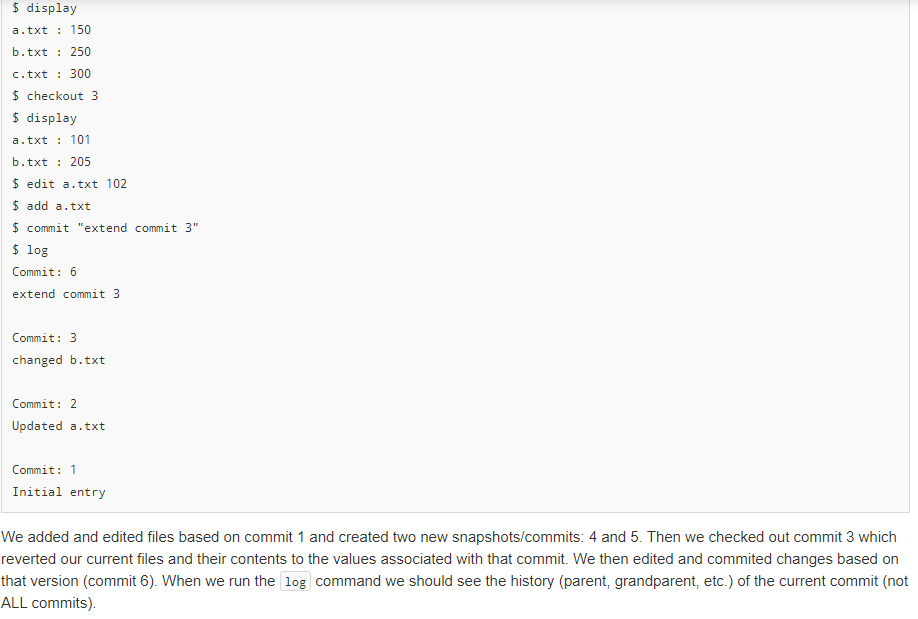
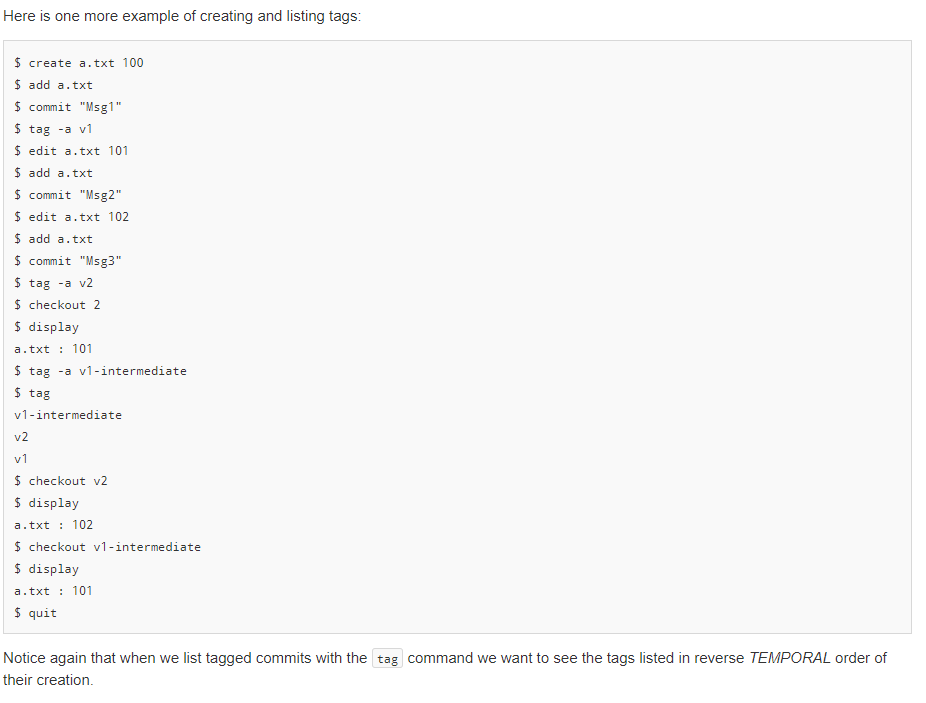
to add/create a new tag name associated with the current commit you have checked out. tag by itself should list all tagnames that have been added. These should be display in the order the tags were created from most to least recent. Finally, you can update your file data to match that of a particular tag/commit by using the checkout tagname/ commit-number command Let's continue using the example directly above, with its two commits and demonstrate the use of the tag and checkout commands. $ tag -a v1-release $ edit b.txt 205 $ add b.txt $ commit "changed b.txt" $ log Commit: 3 changed b.txt Commit: 2 Updated a.txt Commit: 1 Initial entry $ display a.txt : 101 b.txt : 205 $ checkout v1-release $ display a.txt : 101 b.txt : 200 $ checkout 1 $ display a.txt : 100 b.txt : 200 Notice here we created a tagged name for the commit we were on (or the currently checked-out commit). This allows the string (e.g. v1- release) that follows the -a to now refer to the current version of the code (e.g. commit 2 ). The checkout command will revert the state of your files to the state at a particular commit or tag name. You can see checkout v1-release overwrote our file content back to commit 2, which is the commit associated with the v1-release tag name. checkout 1 reverted the file content back to commit 1. (Note: checkout 2 would have the same effect as the checkout v1-release ). When we perform a checkout any uncommitted changes will be reverted. The actual Git tool will give warnings about losing data but for this exercise we will just revert quietly, losing any modifications not committed Continuing on we can then make modifications based on the commit we have checked out and, in turn, add and commit those changes. You will see, then, that each commit has a parent (or previous) commit which it extends. Continuing our example from above: $ edit b.txt 250 $ create c.txt 300 $ add b.txt c.txt $ commit "extensions to commit 1" $ log Commit: 4 extensions to commit 1 Commit: 1 Initial entry $ edit a.txt 150 $ add a.txt $ commit "another extension" $ log Commit: 5 another extension Commit: 4 extensions to commit 1 Commit: 1 Initial entry $ display a.txt : 150 b.txt : 250 c.txt : 300 $ checkout 3 $ display a.txt : 101 b.txt : 205 $ edit a.txt 102 $ add a.txt $ commit "extend commit 3" $ log Commit: 6 extend commit 3 Commit: 3 changed b.txt Commit: 2 Updated a.txt Commit: 1 Initial entry We added and edited files based on commit 1 and created two new snapshots/commits: 4 and 5. Then we checked out commit 3 which reverted our current files and their contents to the values associated with that commit. We then edited and commited changes based on that version (commit 6). When we run the log command we should see the history (parent, grandparent, etc.) of the current commit (not ALL commits). Finally, we can diff the file contents (see the differences between one version/commit of a file compared to another version/commit). There are several ways this can work. diff without arguments should display differences between the current file states (including any current modifications) and the current checked-out commit. diff commit-num should display differences between the current file states (including any current modifications) and some other commit given by commit-num diff commit-n commit-m should display differences between the file state of commit-n and the file state of commit-m. We should assume that commit-n> commit-m (.e. commit-n is a later commit and commit-m is an earlier (ancestor) commit). $ edit a.txt 110 $ edit b.txt 210 $ diff a.txt : 8 b.txt : 5 $ diff 6 a.txt : 8 b.txt : 5 $ diff 3 a.txt : 9 b.txt : 5 $ diff 6 2 a.txt : 1 b.txt : 5 In the above example, we started with commit 6 that had values ( a.txt : 102 and b.txt : 205 ). When we edit the files to update their values and execute a diff with no arguments we should see the difference between the current values and the last commit. This yeilds 8 for a.txt and 5 for b.txt. The same answer should be displayed if we explicitly perform diff 6 (ie. 6 is the latest commit). diff 3 should take the current values and find the differences with commit 3 (where a.txt : 101 and b.txt : 205 ). We can also give two commits (e.g. diff 6 2 ) to find the difference between two commits. Since commit 6 had ( a.txt : 102 and b.txt : 205 ) and commit 2 had ( a.txt : 101 and b.txt : 200 ), the differences are 1 and 5, respectively. Here is one more example of creating and listing tags: $ create a.txt 100 $ add a.txt $ commit "Msg1" $ tag -a v1 $ edit a.txt 101 $ add a.txt $ commit "Msg2" $ edit a.txt 102 $ add a.txt $ commit "Msg3" $ tag -a v2 $ checkout 2 $ display a.txt : 101 $ tag -a v1-intermediate $ tag v1-intermediate v2 v1 $ checkout v2 $ display a.txt : 102 $ checkout v1-intermediate $ display a.txt : 101 $ quit Notice again that when we list tagged commits with the tag command we want to see the tags listed in reverse TEMPORAL order of their creation. In this assignment you will write code for a versioning system similar to Git but for "files" that only contain a single integer. So we are really versioning integer values that are associated with a particular filename (string). (Note: It is a tangential goal of this problem to help you better understand how the actual git tool works and its commands by implementing similar concepts here.) In this problem you will be able to create and edit files, which are similar operations to using a text editor. Then, like git, you will be add and commit files and the integers they contain). You will be able to tag a commit with a name/string, and checkout an older commit via its tag or commit number. You will be able to list a log of the commits and their messages and also compute diffs (differences) between the current values and/or particular commits. The primary goal of this program is to show the correct version of the files/data based on the modification and git -like commands that are applied. Toward that end, you will need to use appropriate AD Ts: list, set, and map. In solving the problem you should use STL data structures that correspond to the most appropriate ADT (list, set, map). Points will be deducted for using a less-than-efficient data structure (i.e. a vector when a set is applicable) or for inefficiently using even the correct data structure (i.e. iterating through a map or set when you should call find ) and use them in an efficient way** So if you provide code that is o(f(n)) of the most efficient method, we may deduct points. To start, there should be a way to create", "edit", and "display" files. Since we only store a single integer in a file we can do this with simple commands: $ create filename value $ edit filename new-value $ display Example: $ create a.txt 100 $ display a : 100 $ create b.txt 200 $ edit a.txt 101 $ display a : 101 b: 200 Here we create a "file" named a.txt whose content is the integer 100. Then, we "edit" that same file replacing 100 with 101. These commands simply mimic a file system and an editor like Sublime or Visual Code. The display command should simply output all the files and their contents (using the filename : value format). Next, a Git-like capability will be implemented. First, we can add , commit, and log similar to git, with slightly different formats. $ add filei (file2 file3 ...) $ commit "message in double-quotes" $ create a.txt 100 $ create b.txt 200 $ add a.txt b.txt $ commit "Initial entry" $ log Commit: 1 Initial entry $ edit a.txt 101 $ add a.txt $ commit "Updated a.txt" $ log Commit: 2 Updated a.txt Commit: 1 Initial entry Notice that use of add will stage the files indicate that their contents/updates should be saved on the next commit) and that you can add any number of files with one add command. commit then takes a log message in double quotes and creates a snapshot of the staged (added) files. Finally, log will show a list of the commit numbers and their corresponding messages in order from most to least recent. The real git application uses SHA values to identify commits (e.g. 398e6e107018eae2fb9ac2a6f74da7c06c979ca9b ) but we will use a simple integer counter to number commits starting from 1. Git has the notion of "tags" which are simple names (strings) that can be associated with a particular commit. You can then use that name to refer to that commit when trying to checkout that version of the code. These tags are commonly used to label commits that correspond to major or minor releases of the software application. Use tag -a to add/create a new tag name associated with the current commit you have checked out. tag by itself should list all tagnames that have been added. These should be display in the order the tags were created from most to least recent. Finally, you can update your file data to match that of a particular tag/commit by using the checkout tagname/ commit-number command Let's continue using the example directly above, with its two commits and demonstrate the use of the tag and checkout commands. $ tag -a v1-release $ edit b.txt 205 $ add b.txt $ commit "changed b.txt" $ log Commit: 3 changed b.txt Commit: 2 Updated a.txt Commit: 1 Initial entry $ display a.txt : 101 b.txt : 205 $ checkout v1-release $ display a.txt : 101 b.txt : 200 $ checkout 1 $ display a.txt : 100 b.txt : 200 Notice here we created a tagged name for the commit we were on (or the currently checked-out commit). This allows the string (e.g. v1- release) that follows the -a to now refer to the current version of the code (e.g. commit 2 ). The checkout command will revert the state of your files to the state at a particular commit or tag name. You can see checkout v1-release overwrote our file content back to commit 2, which is the commit associated with the v1-release tag name. checkout 1 reverted the file content back to commit 1. (Note: checkout 2 would have the same effect as the checkout v1-release ). When we perform a checkout any uncommitted changes will be reverted. The actual Git tool will give warnings about losing data but for this exercise we will just revert quietly, losing any modifications not committed Continuing on we can then make modifications based on the commit we have checked out and, in turn, add and commit those changes. You will see, then, that each commit has a parent (or previous) commit which it extends. Continuing our example from above: $ edit b.txt 250 $ create c.txt 300 $ add b.txt c.txt $ commit "extensions to commit 1" $ log Commit: 4 extensions to commit 1 Commit: 1 Initial entry $ edit a.txt 150 $ add a.txt $ commit "another extension" $ log Commit: 5 another extension Commit: 4 extensions to commit 1 Commit: 1 Initial entry $ display a.txt : 150 b.txt : 250 c.txt : 300 $ checkout 3 $ display a.txt : 101 b.txt : 205 $ edit a.txt 102 $ add a.txt $ commit "extend commit 3" $ log Commit: 6 extend commit 3 Commit: 3 changed b.txt Commit: 2 Updated a.txt Commit: 1 Initial entry We added and edited files based on commit 1 and created two new snapshots/commits: 4 and 5. Then we checked out commit 3 which reverted our current files and their contents to the values associated with that commit. We then edited and commited changes based on that version (commit 6). When we run the log command we should see the history (parent, grandparent, etc.) of the current commit (not ALL commits). Finally, we can diff the file contents (see the differences between one version/commit of a file compared to another version/commit). There are several ways this can work. diff without arguments should display differences between the current file states (including any current modifications) and the current checked-out commit. diff commit-num should display differences between the current file states (including any current modifications) and some other commit given by commit-num diff commit-n commit-m should display differences between the file state of commit-n and the file state of commit-m. We should assume that commit-n> commit-m (.e. commit-n is a later commit and commit-m is an earlier (ancestor) commit). $ edit a.txt 110 $ edit b.txt 210 $ diff a.txt : 8 b.txt : 5 $ diff 6 a.txt : 8 b.txt : 5 $ diff 3 a.txt : 9 b.txt : 5 $ diff 6 2 a.txt : 1 b.txt : 5 In the above example, we started with commit 6 that had values ( a.txt : 102 and b.txt : 205 ). When we edit the files to update their values and execute a diff with no arguments we should see the difference between the current values and the last commit. This yeilds 8 for a.txt and 5 for b.txt. The same answer should be displayed if we explicitly perform diff 6 (ie. 6 is the latest commit). diff 3 should take the current values and find the differences with commit 3 (where a.txt : 101 and b.txt : 205 ). We can also give two commits (e.g. diff 6 2 ) to find the difference between two commits. Since commit 6 had ( a.txt : 102 and b.txt : 205 ) and commit 2 had ( a.txt : 101 and b.txt : 200 ), the differences are 1 and 5, respectively. Here is one more example of creating and listing tags: $ create a.txt 100 $ add a.txt $ commit "Msg1" $ tag -a v1 $ edit a.txt 101 $ add a.txt $ commit "Msg2" $ edit a.txt 102 $ add a.txt $ commit "Msg3" $ tag -a v2 $ checkout 2 $ display a.txt : 101 $ tag -a v1-intermediate $ tag v1-intermediate v2 v1 $ checkout v2 $ display a.txt : 102 $ checkout v1-intermediate $ display a.txt : 101 $ quit Notice again that when we list tagged commits with the tag command we want to see the tags listed in reverse TEMPORAL order of their creation




