

Question
Im using scrapy with python to crawl course information out of university website. I have the code but its not crawling information out and not
Im using scrapy with python to crawl course information out of university website. I have the code but its not crawling information out and not giving me any output. I would appreciate if someone can look at it and tell me what im doing wrong.
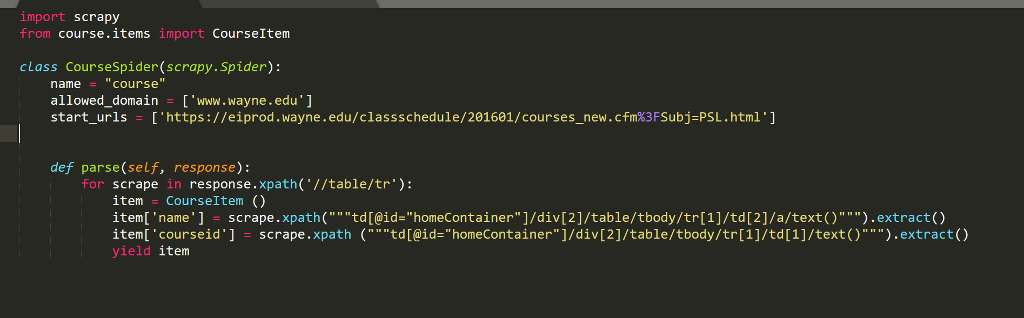 spider.py
spider.py

items.py
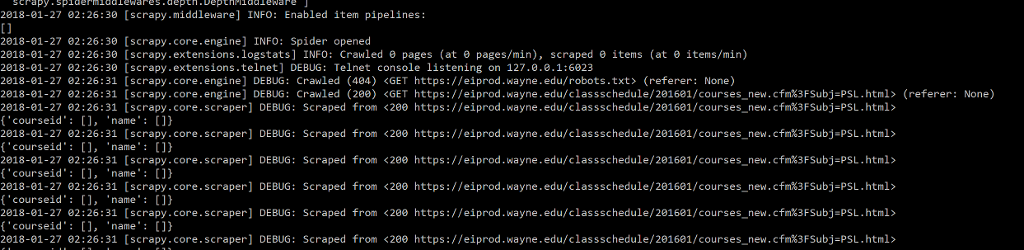 output
output
Thank you
import scrapy from course.items import CourseItem cLass CourseSpider(scrapy.Spider): nameCourse allowed-domain = ['www . wayne . edu'] start-urls ['https://eiprod .wayne.edu/classschedule/201601/courses_new.cfm%3FSubj-PSL.htm1'] def parse(self, response) for scrape in response.xpath( //table/tr): item -CourseItem() item[ 'name'] scrape . xpath('' " "td [@id="homeContainer"]/div[2]/table/tbody/tr[1]/td [2]/a/text () " " " ) . extract () item['courseid'] scrape . xpath (.. " "tdl@id="honeContainer"]/div[2]/table/tbody/tr[1]/td [1]/text ( )""").extract() yield item import scrapy from course.items import CourseItem cLass CourseSpider(scrapy.Spider): nameCourse allowed-domain = ['www . wayne . edu'] start-urls ['https://eiprod .wayne.edu/classschedule/201601/courses_new.cfm%3FSubj-PSL.htm1'] def parse(self, response) for scrape in response.xpath( //table/tr): item -CourseItem() item[ 'name'] scrape . xpath('' " "td [@id="homeContainer"]/div[2]/table/tbody/tr[1]/td [2]/a/text () " " " ) . extract () item['courseid'] scrape . xpath (.. " "tdl@id="honeContainer"]/div[2]/table/tbody/tr[1]/td [1]/text ( )""").extract() yield itemStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Dbms Design Implementation And Management Sql Guide Managing Analyzing And Manipulating Data
Authors: Msa Khan
1st Edition
B0CPB4KMTV, 979-8870384429