

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
In this project, we will begin our lexer. Our lexer will start by reading the strings of the AWK file that the user wants


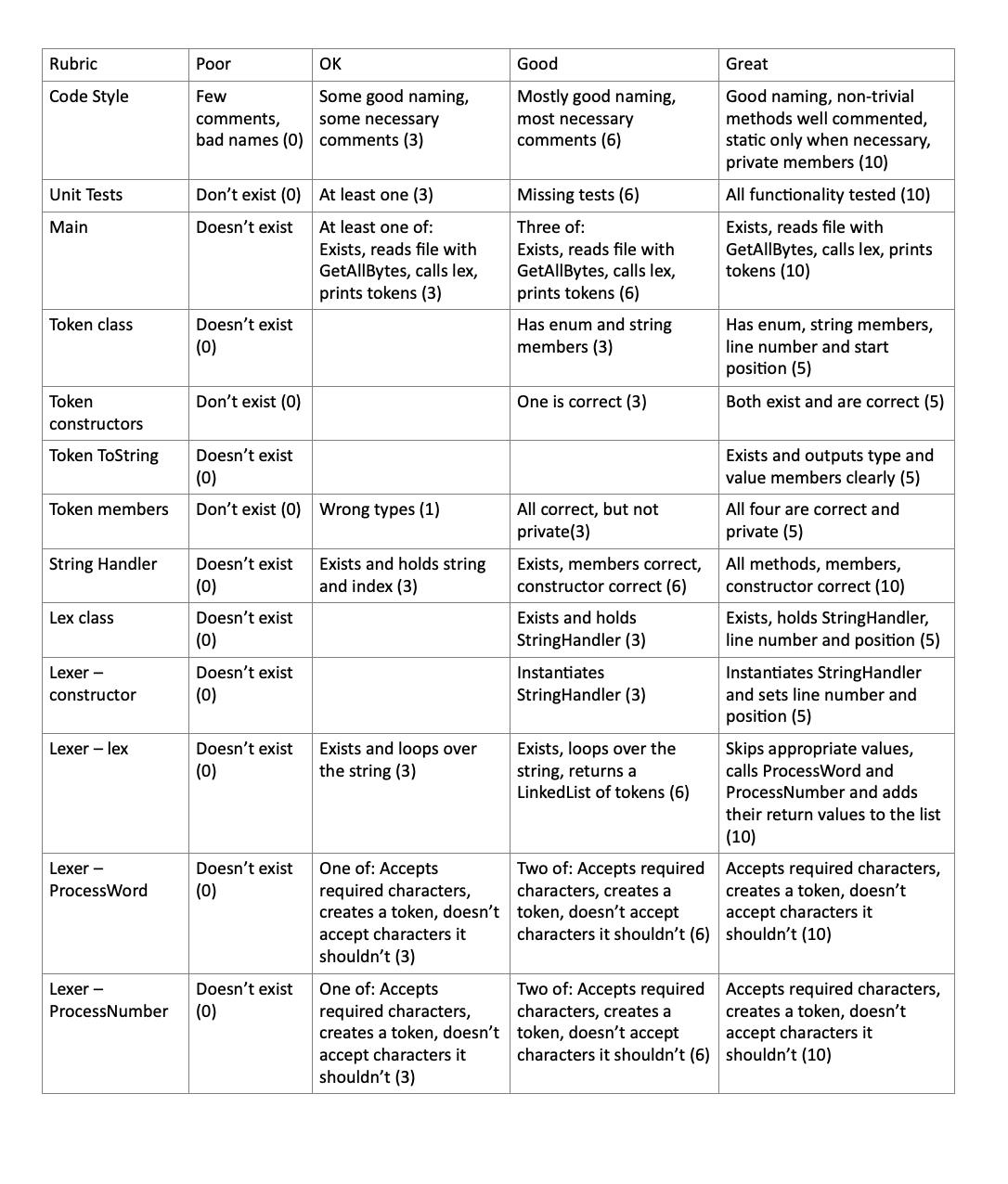
In this project, we will begin our lexer. Our lexer will start by reading the strings of the AWK file that the user wants to run. It will break the AWK code up into "words" or tokens and build a collection of these tokens. We can consider the lexer complete when it can take any AWK file and output a list of the tokens being generated. We will not be using the Scanner class that you may be familiar with for reading from a file; we are, instead, using Files.readAllBytes. This is a much simpler way of dealing with files. Example of readAllLines: Path myPath = Paths.get("someFile.awk"); String content = new String(Files.readAllBytes (myPath); A second concept you may not be familiar with is "enum". Enum, short for enumeration. This is a Java language construct that lets us create a variable that may be any one of a list of things. We will use this to define the types of tokens - a tokenType. enum colorType { RED, GREEN, BLUE } colorType myFavorite colorType.BLUE; System.out.println (myFavorite); // prints BLUE = The general way to think about a lexer is the same way that you learned to read. Remember following the line of letters with your finger? We will do the same thing - we will create a class (I called mine "StringHandler"). This class will "manage" the incoming stream of letters, allowing the lexer to "peek" ahead in the stream, get a character (move the finger one forward), and tell us if we are at the end of the document. With the StringHandler written, we will move on to the lexer itself. For now, we will only deal with a few types of tokens - words, numbers and new line. Of course, just "reading" through the document doesn't do anything - we will make tokens - objects that hold the type (using an enum) and a string of the value. For example: WORD(hello) Details Start by creating the "StringHandler" class (you can name it something else if you like). It should have a private string to hold the document (AWK file) and a private integer index (the finger position). It should have methods: char Peek(i) -looks "i" characters ahead and returns that character; doesn't move the index String PeekString(i) - returns a string of the next "i" characters but doesn't move the index char GetChar() - returns the next character and moves the index void Swallow(i) - moves the index ahead "i" positions boolean IsDone() - returns true if we are at the end of the document String Remainder() - returns the rest of the document as a string Some of these are used in next assignment. Note that there is no accessor for the string array. You must use the methods. Create the Token class. It needs an enum of TokenType (values: WORD, NUMBER, SEPERATOR) and a string to hold the value of the token (for example, "hello" and "goodbye" are both WORD, but with different values. The token will also hold the line number and character position of the start of the token. Create two constructors - one for Token Type, line number and position and one that also has a value; some tokens don't have a value because it is doesn't matter (new line). Make sure to add a ToString method. Your exact format isn't critical; I output the token type and the value in parentheses if it is set. Next, we will create the Lexer class. It should take a string as a parameter to the constructor. The constructor should create a StringHandler. All access to the document will be done through the StringHandler's methods. The Lexer will also keep track of what line of the document we are on and what character position we are on within the line. This is different from the index in the StringHandler. The Lexer needs a "Lex" method - this is the "main" that will break the data from StringHandler into a linked list of tokens. While there is still data in StringHandler, we want to peek at the next character to get an idea what to do with it. If the character is a space or tab, we will just move past it (increment position). If the character is a linefeed ( ), we will create a new SEPERATOR token with no "value" and add it to token list. We should also increment the line number and set line position to 0. If the character is a carriage return ( ), we will ignore it. If the character is a letter, we need to call ProcessWord (see below) and add the result to our list of tokens. If the character is a digit, we need to call Process Digit (see below) and add the result to our list of tokens. Throw an exception if you encounter a character you don't recognize. ProcessWord is a method that returns a Token. It accepts letters, digits and underscores (_) and make a String of them. When it encounters a character that is NOT one of those, it stops and makes a "WORD" token, setting the value to be the String it has accumulated. Make sure that you are using "peek" so that whatever character does NOT belong to the WORD stays in the StringHandler class. Also remember to increment the position value. Process Number is similar to Process Word, but accepts 0-9 and one ".". It does not accept plus or minus - we will handle those next time. Create Junit tests for your lexer. Test with single and multi-line strings. Test with words then numbers and numbers and then words. Finally, create a "main" class. It should take a command line parameter of a filename. It should call GetAllBytes (as mentioned above) and pass the result to the lexer. It should print out the resultant tokens. NOTE For the "on anything else", don't consume the character, go back to state 1 so that the machine can figure out which way to go. - 1 Input an empty line 5 goodbye 5.23 8.5 3 on anything else, make a token for the accumulated word a-zA-Z space -0-9- a-zA-Z0-9 on anything else, make a token for the accumulated number 2 (period) (period) 0-9- 3 0-9 on anything else, make a token for the accumulated number Some examples of valid input and the result output are: Output SEPERATOR NUMBER (5) WORD(goodbye) SEPERATOR NUMBER(5.23) NUMBER(8.5) NUMBER(3) SEPERATOR Rubric Code Style Unit Tests Main Token class Token constructors Token ToString Token members String Handler Lex class Lexer - constructor Lexer - lex Lexer - ProcessWord Lexer - ProcessNumber Poor Few comments, bad names (0) Don't exist (0) Doesn't exist Doesn't exist (0) Don't exist (0) Doesn't exist (0) Doesn't exist (0) Don't exist (0) Wrong types (1) Doesn't exist (0) Doesn't exist (0) Doesn't exist (0) Doesn't exist (0) OK Some good naming, some necessary comments (3) Doesn't exist (0) At least one (3) At least one of: Exists, reads file with GetAllBytes, calls lex, prints tokens (3) Exists and holds string and index (3) Exists and loops over the string (3) One of: Accepts required characters, creates a token, doesn't accept characters it shouldn't (3) One of: Accepts required characters, creates a token, doesn't accept characters it shouldn't (3) Good Mostly good naming, most necessary comments (6) Missing tests (6) Three of: Exists, reads file with GetAllBytes, calls lex, prints tokens (6) Has enum and string members (3) One is correct (3) All correct, but not private (3) Exists, members correct, constructor correct (6) Exists and holds StringHandler (3) Instantiates StringHandler (3) Exists, loops over the string, returns a Linked List of tokens (6) Great Good naming, non-trivial methods well commented, static only when necessary, private members (10) All functionality tested (10) Exists, reads file with GetAllBytes, calls lex, prints tokens (10) Has enum, string members, line number and start position (5) Both exist and are correct (5) Exists and outputs type and value members clearly (5) All four are correct and private (5) All methods, members, constructor correct (10) Exists, holds StringHandler, line number and position (5) Instantiates StringHandler and sets line number and position (5) Skips appropriate values, calls ProcessWord and ProcessNumber and adds their return values to the list (10) Two of: Accepts required characters, creates a token, doesn't accept characters it shouldn't (6) shouldn't (10) Accepts required characters, creates a token, doesn't accept characters it Two of: Accepts required Accepts required characters, characters, creates a creates a token, doesn't token, doesn't accept accept characters it characters it shouldn't (6) shouldn't (10)
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Step 1 Implement the StringHandler Class Heres the Java code for the StringHandler class public class StringHandler private String input private int index public StringHandlerString input thisinput in...
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Organic Chemistry
Authors: Francis A. Carey
4th edition
0072905018, 978-0072905014