

Question
INSTRUCTIONS: Write a seven page paper in Microsoft Word about search engines, include the following: - Cover page including a picture or a graphics and
INSTRUCTIONS:
Write a seven page paper in Microsoft Word about search engines, include the following:
- Cover page including a picture or a graphics and your name and date
- Headers including your name and date but not on the cover page
- Footers including page numbers but not on the cover page
- Automatically generated table of contents on page 1
- Logos of main companies you are writing about
Use the following outline:
Overview (level 1)
Types of Search Engines (level 1)
Crawlers (level 2)
Specialty (level 2)
Databases (level 2)
Search Strategy (level 1)
Search in other countries (level 1)
Summary (level 1)
THIS IS WHAT I HAVE SO FAR :: I AM MISSING A COVER PAGE IN PAGE 1, AND TABLE ON CONTEXT IN PAGE 2, ILL DO THE HEADER, AND WRITE ABOUT SEARCH STRATEGY, SEARCH IN OTHER COUNTRIES AND SUMMARIZE
MY NAME
Professor C
SUBJECT
15 August 2018
Overview (level 1)
Types of Search Engines (level 1)
Crawlers (level 2)
Databases (level 2)
Please have a look and in case of any doubt please leave a comment. Hope its helpful.
Overview: With the development of the internet so much information is available on the web. But all the information is not available at one place. It is impossible for the common user to remember where the information is stored. So, with the advancement of web and so much data available a new challenge was waiting for the scientists and that was the information retrieval. To make the life of a common user very easy Search Engines were developed. Current search engines are so user friendly that even a small child can use it without adult help. User can search for any information by passing query in form of keywords. It then searches for relevant information in its database and return to the results to the user. According to Dictionary: Search Engine is a program that searches for and identifies items in a database that correspond to keywords or characters specified by the user, used especially for finding particular sites on the World Wide Web. The search Engines have changed with time dramatically. They can produce much better results than initial years of 2000. The first search engine was created in year 199. It was called Archie which was for FTP sites only and could search files. The first web search engine was developed in 1994. It was called World Wide Web Worm. While the performance of old engines was not that great. User had to enter exact terms but with the advancement in Machine learning and AI there is so hey use machine learning to help process and rank information, and can understand natural human speech. Now a days, on internet there are thousands of different search engines available, all having different features and functionalities. A search engine often uses an indexing to look for files after the user has entered search term.The most popular search engine is Google. Google not only provides text search, it has come up with image search also (still not that accurate).Types of Search Engines: There are different types of search engines:Crawler based engines: These type of search engines uses crawlers to find and display the relevant results to the user. Crawlers are explained in the following paragraph.
Directories: Its a manual way of storing the information. Whenever a new website is created the owner sends a URL with the site description(meta-data) with it to the directory. Then manually the contents are verified and added to sub categories. The main problem with this is ofcourse the manual work involved also if the web-site is updated and meta-data is not then the website will not appear in search result
Hybrid search engine: Hybrid as the name suggest is the mix of Crawler based and Directory based. So, primarily Crawler are used for finding data but directory based as a secondary option.With so much advancement in search engines strategies only Crawler based search engines are the mostly used.
There are three basic components of a search engine that make it work are:
Crawlers: To find relevant web page from millions of the pages on the internet Crawler (also called Spider) are used. Crawlers are the programs that visits all Web sites and reads all searchable pages or other information (this process is called web crawling) and creates entry in the search engine index. Their main purpose is Web Indexing. These entries are being updated all the times. If the keyword is not present in the index the new keyword is added. Web Crawler looks for the web pages and if it finds the relevant page then it is displayed to the user. Web Crawlers make a list of words from a web page and also add where it found the word. This information is further stored in the database for the future use. This is shown in the diagram below:
"Picture included in the screenshot"
In this way, the spidering system quickly begins to travel, moving across the other pages on the Web. It got its name, as it goes from one place to another and creates link from word to the page. The spider start searches by going to popular site and following every link found within the site. They are smart enough to go from one page to another by following the links on the first page. The crawlers dont rank the pages rather it is the responsibility of the search engine to do that. Based on these words and with different strategies the search engine creates the rank of the page and displays the result in the relevant order. So, while developing spiders developers have to careful. Modern search engines like Google are using crawlers to properly index downloaded pages. It makes the search engine very fast and efficient. But the they can consume lot of resources on visited systems and often visit sites without approval. So, to avoid this a server (or visiting site) need to maintain a file called robots.txt at the root of your web server. This file is used by the crawlers when they visit a site. With the help of this file a server can tell crawler what is he allowed to do, means what resources (files, directories) its not allowed to visit. This file can help control the crawl traffic and ensure that it doesnt overwhelm your serve. The information about web crawler is present in the HTTP request message in the field User-Agent. Example robot.txt is this:
User-agent: *
Disallow: /
It means that all the user-agents are not allowed to go any indexing on any of the contents. Eg. Of popular search engines that are using crawlers are Google, Yahoo.
Specialty :
Databases: Like explained in the Crawler section all the keywords and the url where the information was found are stored in the backend database. So, when a user enters a query his query is not directly starts searching on web, actually search engine starts searching through the index that the search engine has created. These indices are giant databases of information that is collected and stored and subsequently searched. Different companies are using different database for storing all these indices and the URLs. Like Google also uses Oracle and MySQL databases for some of their applications.
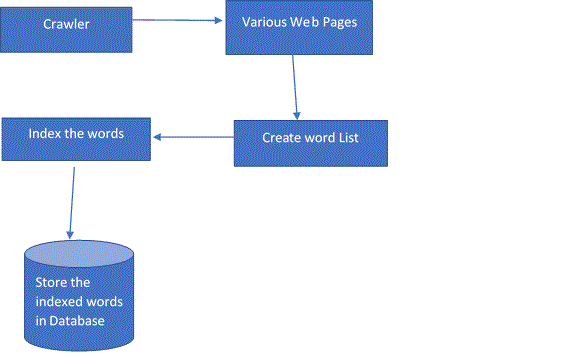
Crawler Various Web Pages Index the words Create word List Store the indexed words in Database
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Mastering Real Time Analytics In Big Data A Comprehensive Guide For Everyone
Authors: Lennox Mark
1st Edition
B0CPTC9LY9, 979-8869045706