

Question
Java Program: There must be no error in the code. Show the full code with the output as well. Below are the lexer, token, and
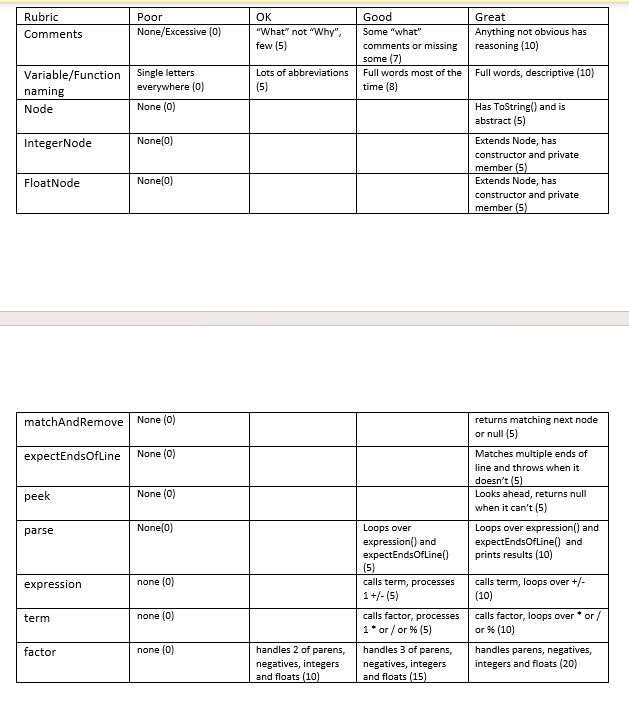
Java Program: There must be no error in the code. Show the full code with the output as well. Below are the lexer, token, and shank files. The shank file is the main method file. Attached is rubric.
Create a Parser class (does not derive from anything). It must have a constructor that accepts your collection of Tokens. We will be treating the collection of tokens as a queue taking off the front. It isnt necessary to use a Java Queue, but you may.
We will add three helper functions to parser. These should be private:
matchAndRemove accepts a token type. Looks at the next token in the collection:
If the passed in token type matches the next tokens type, remove that token and return it.
If the passed in token type DOES NOT match the next tokens type (or there are no more tokens) return null.
expectEndsOfLine uses matchAndRemove to match and discard one or more ENDOFLINE tokens. Throw a SyntaxErrorException if no ENDOFLINE was found.
peek accepts an integer and looks ahead that many tokens and returns that token. Returns null if there arent enough tokens to fulfill the request.
Parser parse
Create a public parse method. There are no parameters, and it returns Node. This will be called from main once lexing is complete. For now, we are going to only parse a subset of Shank V2 mathematical expressions. Parse should call expression() then expectEndOfLine() in a loop until either returns null. Dont worry about storing the return node but you should print it out (using ToString()) for testing.
The tricky part of mathematical expressions is order of operations. Fortunately, this is fairly easily solved in recursive descent by using a few functions. The intuition is this: accept tokens from the highest priority first. When you cant find any that fit the pattern, fall back to lower priority. The thing that makes this weird is that we will call the lowest level first. But it calls the next highest first thing. Lets take a look:
EXPRESSION = TERM { (plus or minus) TERM}
TERM = FACTOR { (times or divide or mod) FACTOR}
FACTOR = {-} number or lparen EXPRESSION rparen
Notice the curly braces these indicate 0 or more.
expression(), term() and factor() will all be methods of our recursive descent parser. All of them must use matchOrRemove(). The formulae above are very literal. Consider the first one:
EXPRESSION = TERM { (plus or minus) TERM}
expression() calls term(). Then it (in a loop) looks for a + or -. If it finds one, it calls term again and constructs a MathOpNode using the two term() returns as the left and right. That MathOpNode becomes the left if there are more +/- sign. So 1+2+3 becomes:
MathOpNode(+,IntegerNode(1),(MathOpNode(+,IntegerNode(2),IntegerNode(3)))
Lets look at a complete example: 3*-4+5: our tokens will look something like this:
NUMBER TIMES MINUS NUMBER PLUS NUMBER ENDOFLINE your token types might differ a little
We will call expression(). The first thing it does is look for a term by calling term(). term() calls factor() first thing. factor() will matchAndRemove MINUS and not find it. It then tries NUMBER succeeds.
NUMBER TIMES MINUS NUMBER PLUS NUMBER ENDOFLINE
It looks at the NUMBER node, sees no decimal point and makes an IntegerNode (3) and returns it. term() gets the IntegerNode from factor() and now should loop looking for TIMES or DIVIDE. It finds a TIMES.
NUMBER TIMES MINUS NUMBER PLUS NUMBER ENDOFLINE
It should then call factor(). factor() looks for the MINUS. It finds it. It internally notes that we are now in negative mode. It then finds the NUMBER. It sees no decimal point and makes an IntegerNode (-4) and returns it.
NUMBER TIMES MINUS NUMBER PLUS NUMBER ENDOFLINE
term() gets the IntegerNode. It constructs a MathOpNode of type multiply with a left and right side of the two IntegerNodes. It now looks for multiply and divide and doesnt find them. It returns the MathOpNode that it has.
Now expression() has a MathOpNode. It looks for plus or minus and finds plus.
NUMBER TIMES MINUS NUMBER PLUS NUMBER ENDOFLINE
Now expression() calls term() which calls factor() which looks for NUMBER, finds it and constructs an IntegerNode (5).
NUMBER TIMES MINUS NUMBER PLUS NUMBER ENDOFLINE
term() wont find a times or divide, so it returns the IntegerNode. expression() now has a + with a left and a right side, so it creates that MathOpNode. It looks for plus/minus, doesnt find it and returns the + MathOpNode. parse() should print the returned Node (the MathOpNode).
expectEndsOfLine() is called and finds an ENDOFLINE.
NUMBER TIMES MINUS NUMBER PLUS NUMBER ENDOFLINE
Assuming that was all that was in the input file, the next call to Expression() will return null and we will exit.
Your output can vary a lot. My only requirement is that it shows unambiguously that the tree was constructed correctly. One example:
MathOpNode(+, MathOpNode(*,IntegerNode(3),IntegerNode(-4)),IntegerNode(5))
Lexer.java
package mypack;
import java.util.HashMap; import java.util.List; import mypack.Token.TokenType;
public class Lexer {
private static final int INTEGER_STATE = 1; private static final int DECIMAL_STATE = 2; private static final int IDENTIFIER_STATE = 3; private static final int SYMBOL_STATE = 4; private static final int ERROR_STATE = 5; private static final int STRING_STATE = 6; private static final int CHAR_STATE = 7; private static final int COMMENT_STATE = 8;
private static final char EOF = (char) -1;
private static String input; private static int index; private static char currentChar; private static int lineNumber = 1; private static int indentLevel = 0; private static int lastIndentLevel = 0;
private static HashMap
private static HashMap
Shank.java
package mypack;
import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import java.util.List;
public class Shank { public static void main(String[] args) { if (args.length != 1) { System.out.println("Error: Exactly one argument is required."); System.exit(0); }
String filename = args[0];
try { List
for (String line : lines) { try { Lexer lexer = new Lexer(line); List
Token.java
package mypack;
public class Token { public enum TokenType { WORD, WHILE, IF, ELSE, NUMBER, SYMBOL, PLUS, MINUS, MULTIPLY, DIVIDE, EQUALS, COLON, SEMICOLON, LEFT_PAREN, RIGHT_PAREN, LEFT_BRACE, RIGHT_BRACE, LESS_THAN, GREATER_THAN, PRINT }
public TokenType tokenType; private String value; public Token(TokenType type, String val) { this.tokenType = type; this.value = val; } public TokenType getTokenType() { return this.tokenType; } public String toString() { return this.tokenType + ": " + this.value; } }
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
MongoDB Applied Design Patterns Practical Use Cases With The Leading NoSQL Database
Authors: Rick Copeland
1st Edition
1449340040, 978-1449340049