

Question
JAVA Programming Question Background: HTML HTML, the HyperText Markup Language, is used to describe the content of webpages. This is done by annotating the content
JAVA Programming Question
Background: HTML
HTML, the HyperText Markup Language, is used to describe the content of webpages. This is done by annotating the content with tags. HTML has two types of tags: Element tags and Void. HTML elements consist of a start tag, some content, and an end tag. For example,
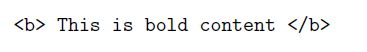
illustrates a bold element, which is how content can be bolded in HTML. Observe that both the start and the end tag of an element have the same name, except that the end tag starts with a /. Elements can be nested. An HTML document comprises many nested elements, such as the example below:

There are also void or empty tags, which are singleton tags that do not bracket content and hence do not need to be closed. For example, "hr" in Figure 1 is a void tag. Special void tags, whose names begin with a !, are used to include comments and metadata in the HTML. Tags beginning with ! can be ignored.
Problem: Analyzing the Structure of HTML
The nesting of tags creates a natural structure in an HTML document, which is useful to visualize. For example, the structure of the previous example can be visualized as an outline: In this example, the "html" element contains one element: "body". The "body" element

contains four elements: "h1", "p", "hr", and "p". All the elements but the last one contain no elements, and the last element, "p" contains a "b" element. Observe that the deeper an element is nested, the further it is indented. Furthermore, every element is followed by an integer, indicating how many elements and void tags it contains. Your task is to create a program that generates an outline representation of an HTML document based on the requirements below.
Write a program called HTMLSummarizer.java that reads in an HTML file and outputs the corresponding outline representation. Your HTMLSummarizer class must implement the provided Tester interface and also contain the main() method where your program starts running. This is because your program will be tested via this interface. The interface contains a single method:
public interface Tester { public ArrayList compute( Scanner input ); }
This method must perform the required computation.
Input
The method takes a Scanner object, which contains a valid HTML file. You may assume that every start tag is properly matched with an end tag, and that there are no errors in the input. Hint: Use the provided HTMLScanner object to easily parse the input by using its two methods: hasNextTag() and nextTag().
public class HTMLScanner { public static final String [] voidTags = { "area", "base", "br", "col", "command", "embed", "hr", "img", "input", "keygen", "link", "meta", "param", "source", "track", "wbr"};
private Scanner stream; private String tagBody;
public HTMLScanner( Scanner s ) { stream = s; stream.useDelimiter( "[]" ); }
public boolean hasNextTag() { return stream.hasNext(); }
public String nextTag() { Scanner tag = new Scanner( stream.next() ); String tagName = tag.next(); if( tag.hasNext() ) { tagBody = tag.nextLine(); } else { tagBody = ""; }
if( stream.hasNext() ) { stream.next(); } tag.close(); return tagName.toLowerCase(); } public String getTagBody() { return tagBody; } }
Output
The method compute( Scanner input ) should return an ArrayList of Strings denoting the outline representation of the HTML input. Each element or void tag should be a separate String. The order of the elements and void tags should be the same as in the HTML input and should be indented the same number of spaces as their depth. Lastly, each element in the outline is followed by a single space and an integer, denoting the number of children the element has.

Hints and Suggestions
Java has both stacks (java.utils.Stack) and lists (java.utils.ArrayList) built in. As well as binary search (java.utils.Arrays).
Background: HTML
HTML, the HyperText Markup Language, is used to describe the content of webpages. This is done by annotating the content with tags. HTML has two types of tags: Element tags and Void. HTML elements consist of a start tag, some content, and an end tag. For example,
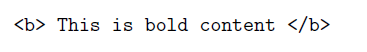
illustrates a bold element, which is how content can be bolded in HTML. Observe that both the start and the end tag of an element have the same name, except that the end tag starts with a /. Elements can be nested. An HTML document comprises many nested elements, such as the example below:

There are also void or empty tags, which are singleton tags that do not bracket content and hence do not need to be closed. For example, "hr" in Figure 1 is a void tag. Special void tags, whose names begin with a !, are used to include comments and metadata in the HTML. Tags beginning with ! can be ignored.
Problem: Analyzing the Structure of HTML
The nesting of tags creates a natural structure in an HTML document, which is useful to visualize. For example, the structure of the previous example can be visualized as an outline: In this example, the "html" element contains one element: "body". The "body" element

contains four elements: "h1", "p", "hr", and "p". All the elements but the last one contain no elements, and the last element, "p" contains a "b" element. Observe that the deeper an element is nested, the further it is indented. Furthermore, every element is followed by an integer, indicating how many elements and void tags it contains. Your task is to create a program that generates an outline representation of an HTML document based on the requirements below.
Write a program called HTMLSummarizer.java that reads in an HTML file and outputs the corresponding outline representation. Your HTMLSummarizer class must implement the provided Tester interface and also contain the main() method where your program starts running. This is because your program will be tested via this interface. The interface contains a single method:
public interface Tester { public ArrayList compute( Scanner input ); }
This method must perform the required computation.
Input
The method takes a Scanner object, which contains a valid HTML file. You may assume that every start tag is properly matched with an end tag, and that there are no errors in the input. Hint: Use the provided HTMLScanner object to easily parse the input by using its two methods: hasNextTag() and nextTag().
public class HTMLScanner { public static final String [] voidTags = { "area", "base", "br", "col", "command", "embed", "hr", "img", "input", "keygen", "link", "meta", "param", "source", "track", "wbr"};
private Scanner stream; private String tagBody;
public HTMLScanner( Scanner s ) { stream = s; stream.useDelimiter( "[]" ); }
public boolean hasNextTag() { return stream.hasNext(); }
public String nextTag() { Scanner tag = new Scanner( stream.next() ); String tagName = tag.next(); if( tag.hasNext() ) { tagBody = tag.nextLine(); } else { tagBody = ""; }
if( stream.hasNext() ) { stream.next(); } tag.close(); return tagName.toLowerCase(); } public String getTagBody() { return tagBody; } }
Output
The method compute( Scanner input ) should return an ArrayList of Strings denoting the outline representation of the HTML input. Each element or void tag should be a separate String. The order of the elements and void tags should be the same as in the HTML input and should be indented the same number of spaces as their depth. Lastly, each element in the outline is followed by a single space and an integer, denoting the number of children the element has.

Hints and Suggestions
Java has both stacks (java.utils.Stack) and lists (java.utils.ArrayList) built in. As well as binary search (java.utils.Arrays).
This is bold content This is bold contentStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Professional Microsoft SQL Server 2014 Integration Services
Authors: Brian Knight, Devin Knight
1st Edition
1118850904, 9781118850909