

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
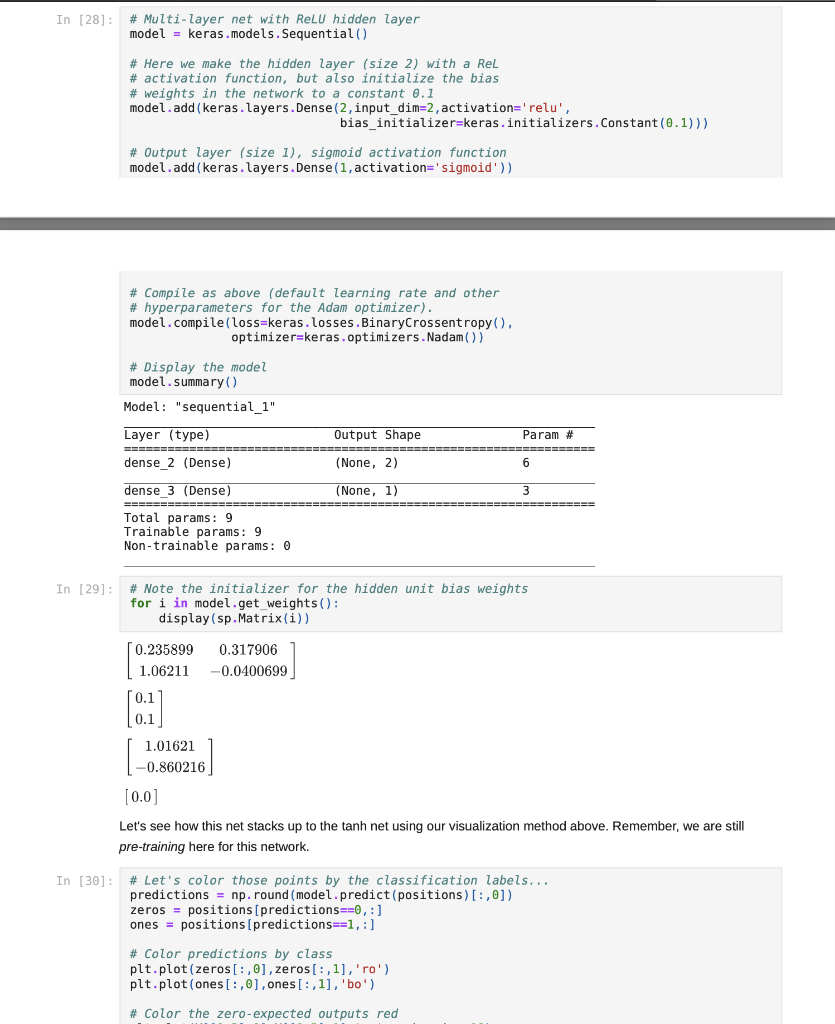
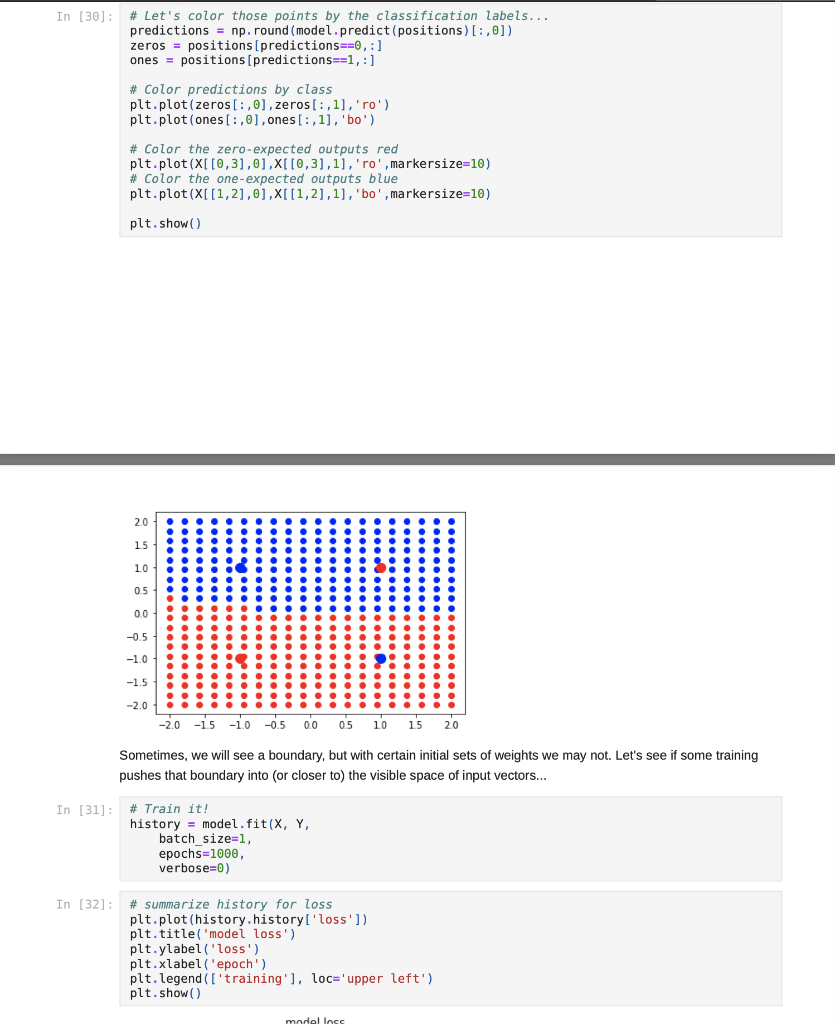
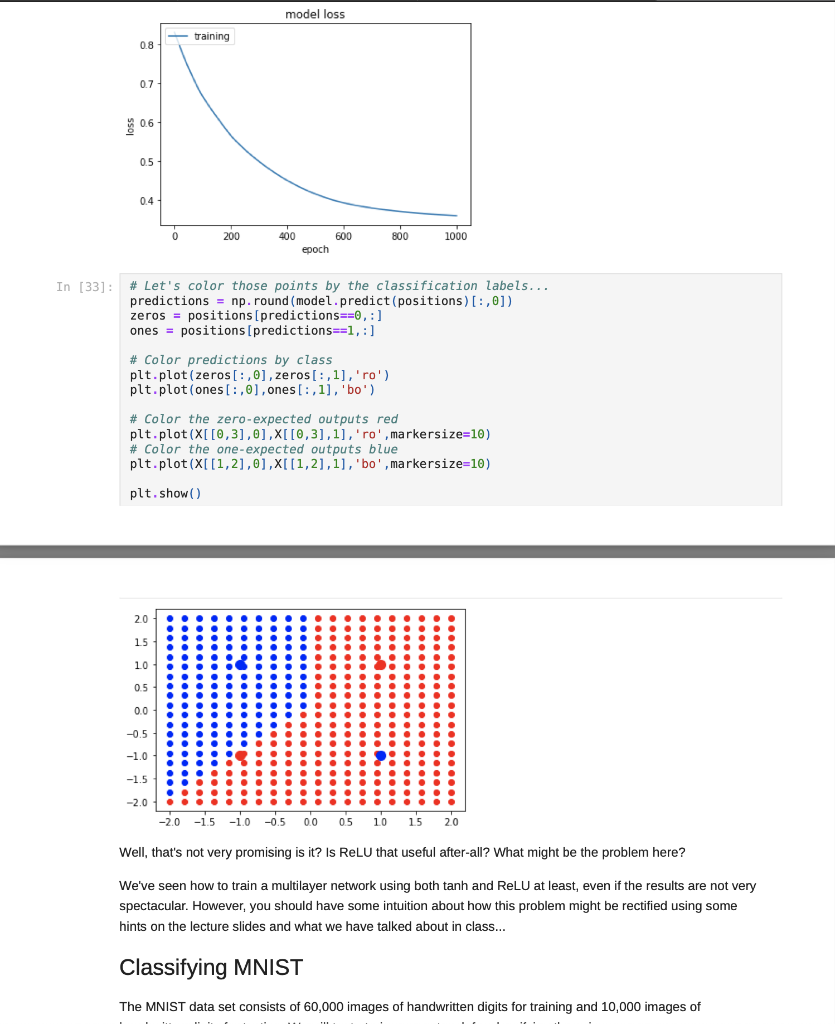
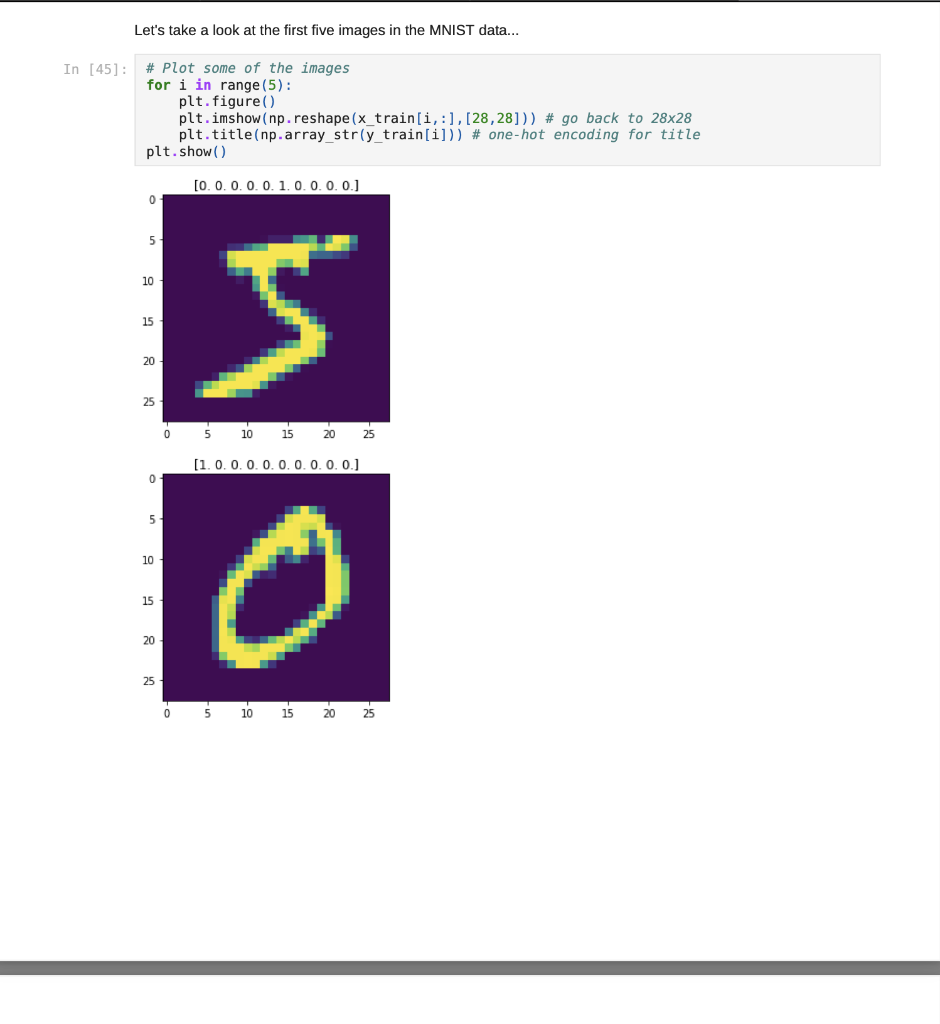
Jupyter Notebook Now that we have tried our hand at some single-layer nets, let's see how they stack up compared to multi-layer nets. :) We
Jupyter Notebook




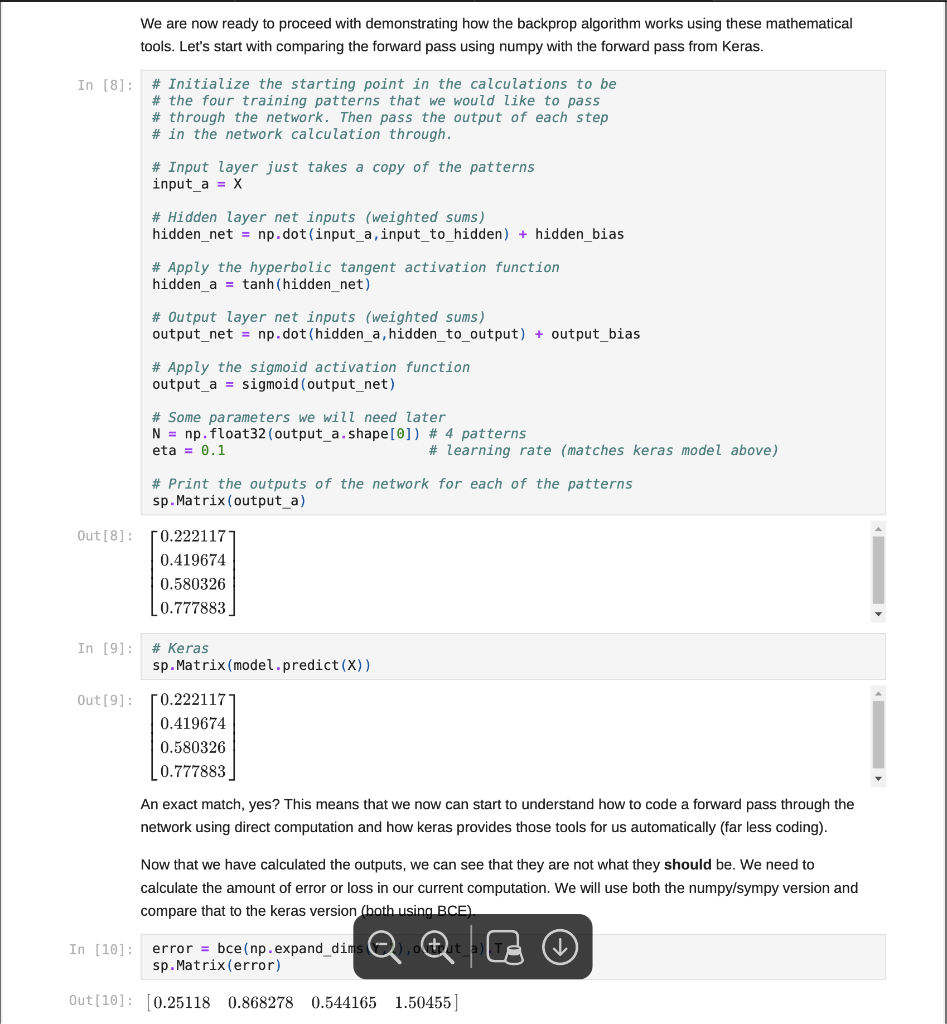




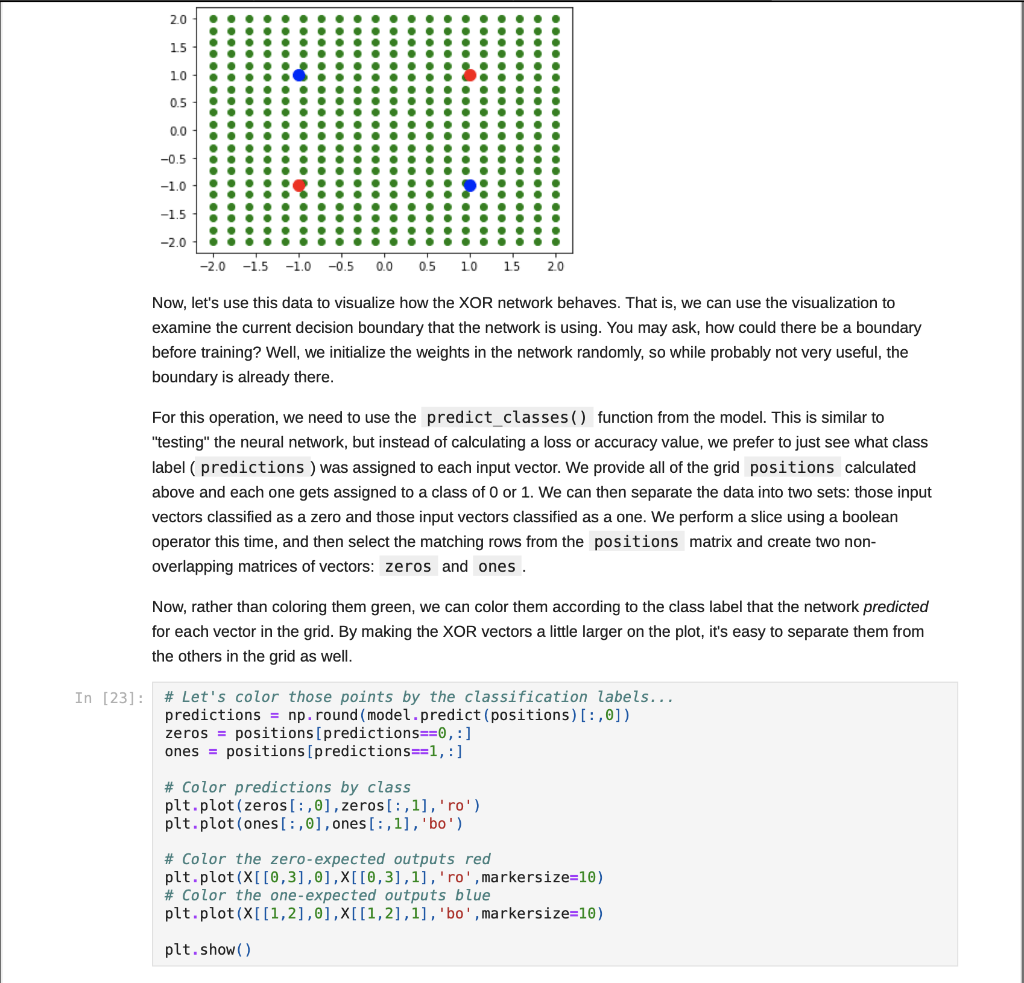
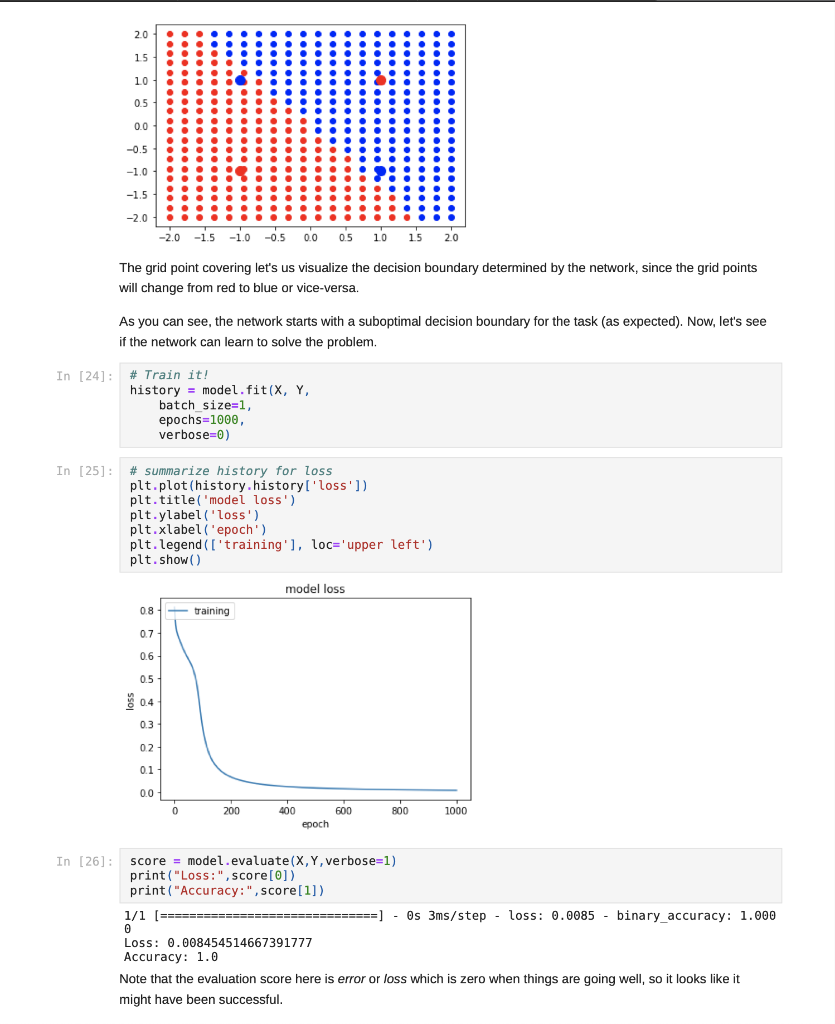
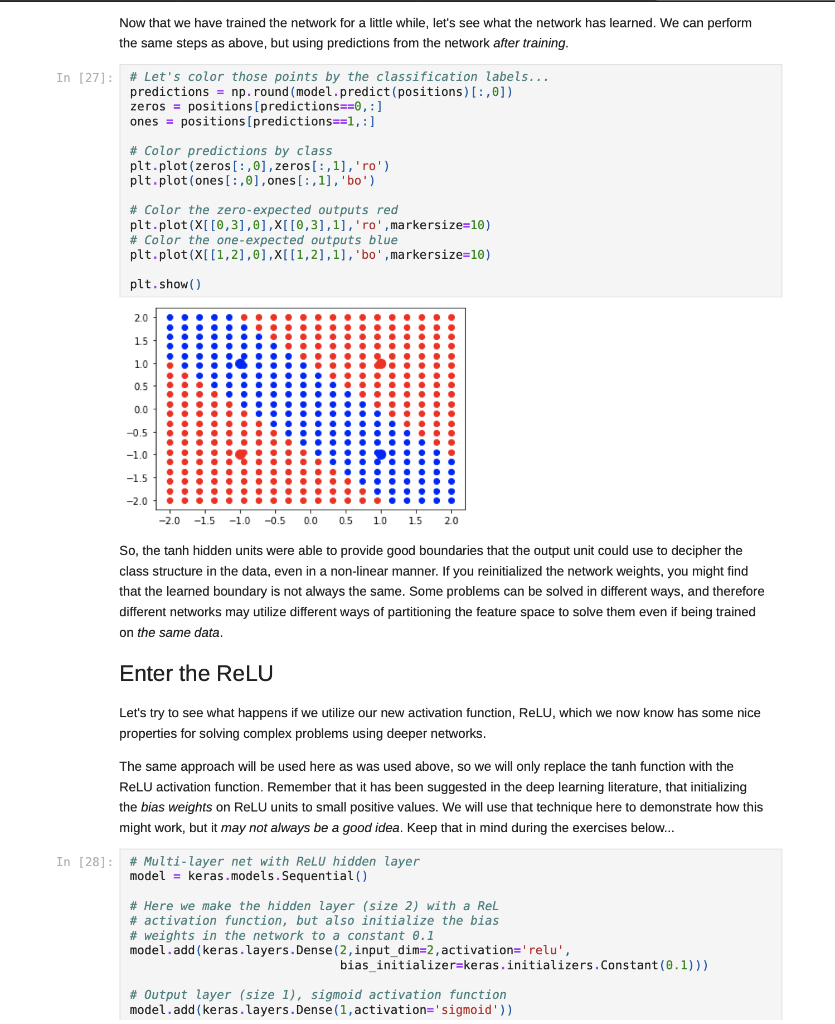





Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Big Data In Just 7 Chapters
Authors: Prof Marcus Vinicius Pinto
1st Edition
B09NZ7ZX72, 979-8787954036