

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
language = python the test cases are included in a downloaded zip html file. I will upload it if it is needed. 3. (18 points)
language = python
the test cases are included in a downloaded zip html file. I will upload it if it is needed.
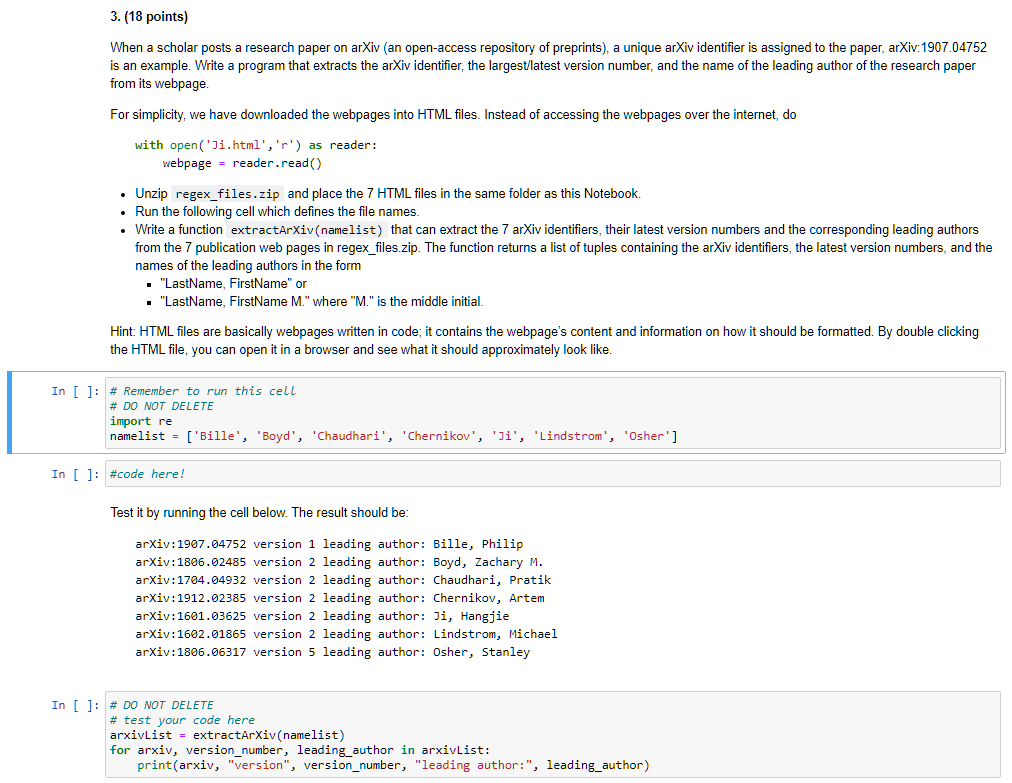
3. (18 points) When a scholar posts a research paper on arXiv (an open-access repository of preprints), a unique arXiv identifier is assigned to the paper, arXiv: 1907.04752 is an example. Write a program that extracts the arXiv identifier, the largest/latest version number, and the name of the leading author of the research paper from its webpage. For simplicity, we have downloaded the webpages into HTML files. Instead of accessing the webpages over the internet, do with open('Ji.html', 'r') as reader: webpage - reader.read() Unzip regex_files.zip and place the 7 HTML files in the same folder as this Notebook. Run the following cell which defines the file names. Write a function extractArXiv(namelist) that can extract the 7 arXiv identifiers, their latest version numbers and the corresponding leading authors from the 7 publication web pages in regex_files.zip. The function returns a list of tuples containing the arXiv identifiers, the latest version numbers, and the names of the leading authors in the form . "LastName, FirstName" or . "LastName, FirstName M." where "M." is the middle initial. Hint: HTML files are basically webpages written in code; it contains the webpage's content and information on how it should be formatted. By double clicking the HTML file, you can open it in a browser and see what it should approximately look like. In [ ]: # Remember to run this cell # DO NOT DELETE import re namelist = ['Bille', 'Boyd', 'Chaudhari', 'Chernikov', 'Ji', 'Lindstrom', 'Osher'] In [ ]: #code here! Test it by running the cell below. The result should be: arXiv:1907.94752 version 1 leading author: Bille, Philip arXiv:1806.02485 version 2 leading author: Boyd, Zachary M. arXiv:1704.84932 version 2 leading author: Chaudhari, Pratik arXiv:1912.02385 version 2 leading author: Chernikov, Artem arXiv:1601.03625 version 2 leading author: Ji, Hangjie arXiv:1602.01865 version 2 leading author: Lindstrom, Michael arXiv:1806.06317 version 5 leading author: Osher, Stanley In [ ]: # DO NOT DELETE # test your code here arxivlist = extractArXiv(namelist) for arxiv, version_number, leading_author in arxivlist: print(arxiv, "version", version_number, "leading author:", leading_author) 3. (18 points) When a scholar posts a research paper on arXiv (an open-access repository of preprints), a unique arXiv identifier is assigned to the paper, arXiv: 1907.04752 is an example. Write a program that extracts the arXiv identifier, the largest/latest version number, and the name of the leading author of the research paper from its webpage. For simplicity, we have downloaded the webpages into HTML files. Instead of accessing the webpages over the internet, do with open('Ji.html', 'r') as reader: webpage - reader.read() Unzip regex_files.zip and place the 7 HTML files in the same folder as this Notebook. Run the following cell which defines the file names. Write a function extractArXiv(namelist) that can extract the 7 arXiv identifiers, their latest version numbers and the corresponding leading authors from the 7 publication web pages in regex_files.zip. The function returns a list of tuples containing the arXiv identifiers, the latest version numbers, and the names of the leading authors in the form . "LastName, FirstName" or . "LastName, FirstName M." where "M." is the middle initial. Hint: HTML files are basically webpages written in code; it contains the webpage's content and information on how it should be formatted. By double clicking the HTML file, you can open it in a browser and see what it should approximately look like. In [ ]: # Remember to run this cell # DO NOT DELETE import re namelist = ['Bille', 'Boyd', 'Chaudhari', 'Chernikov', 'Ji', 'Lindstrom', 'Osher'] In [ ]: #code here! Test it by running the cell below. The result should be: arXiv:1907.94752 version 1 leading author: Bille, Philip arXiv:1806.02485 version 2 leading author: Boyd, Zachary M. arXiv:1704.84932 version 2 leading author: Chaudhari, Pratik arXiv:1912.02385 version 2 leading author: Chernikov, Artem arXiv:1601.03625 version 2 leading author: Ji, Hangjie arXiv:1602.01865 version 2 leading author: Lindstrom, Michael arXiv:1806.06317 version 5 leading author: Osher, Stanley In [ ]: # DO NOT DELETE # test your code here arxivlist = extractArXiv(namelist) for arxiv, version_number, leading_author in arxivlist: print(arxiv, "version", version_number, "leading author:", leading_author)Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Management For Business Leaders Building And Using Data Solutions That Work For You
Authors: Larry Ruddell
1st Edition
1973630249, 978-1973630241