

Question
Must be done in Python i am looking for answer for the second part (Gathering Results: Frequency Distributions) Must be done in Python i am
Must be done in Python i am looking for answer for the second part (Gathering Results: Frequency Distributions)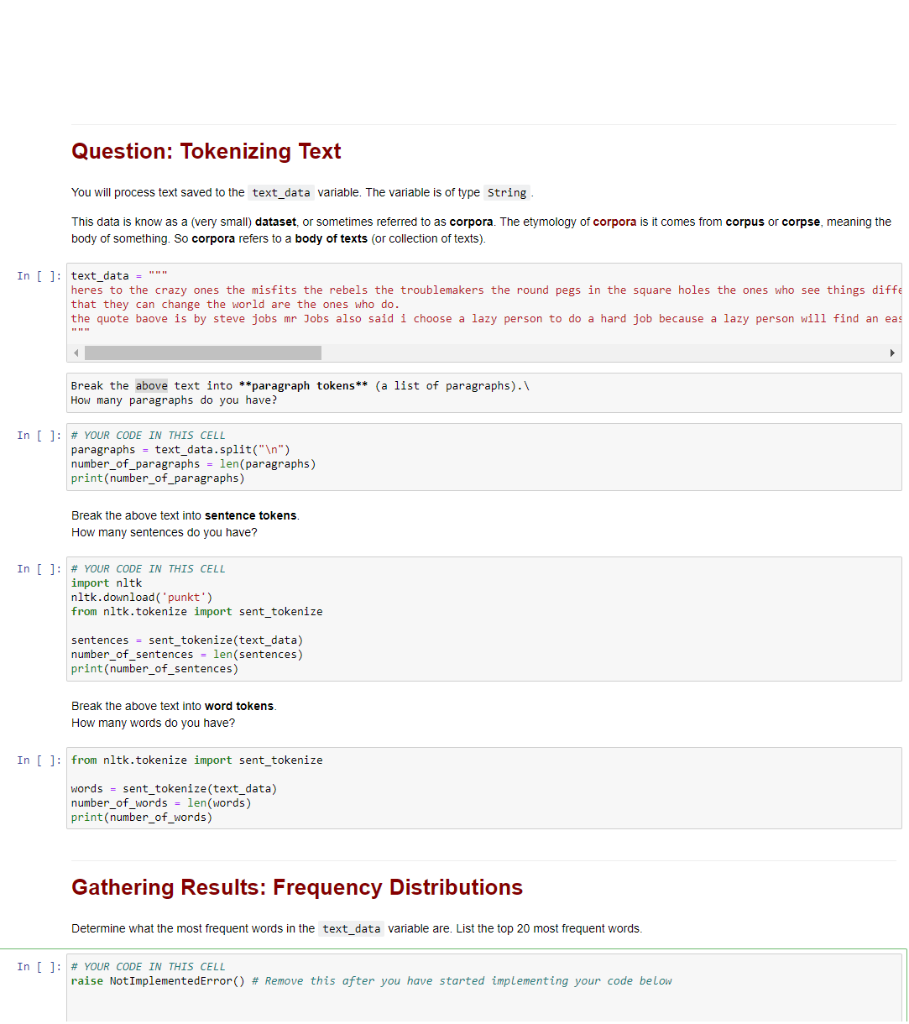
Must be done in Python i am looking for answer for the second part (Gathering Results: Frequency Distributions)
Question: Tokenizing Text You will process text saved to the text_data variable. The variable is of type string . This data is know as a (very small) dataset, or sometimes referred to as corpora. The etymology of corpora is it comes from corpus or corpse, meaning the body of something. So corpora refers to a body of texts (or collection of texts). text_data ="n heres to the crazy ones the misfits the rebels the troublemakers the round pegs in the square holes the ones who see things diff that they can change the world are the ones who do. the quote baove is by steve jobs mr Jobs also said 1 choose a lazy person to do a hard job because a lazy person will find an eas wner Break the above text into **paragraph tokens** (a list of paragraphs). I How many paragraphs do you have? Break the above text into sentence tokens. How many sentences do you have? Break the above text into word tokens. How many words do you have? sentences - sent_tokenize(text_data) number_of_sentences =-len(sentences) print(number_of_sentences) from nltk.tokenize import sent_tokenize words = sent_tokenize(text_data) number_of_words = len(words) print(number_of_words) Gathering Results: Frequency DistributionsStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Spatial Database Systems Design Implementation And Project Management
Authors: Albert K.W. Yeung, G. Brent Hall
1st Edition
1402053932, 978-1402053931