

Question
my code below changed actual file path to file path. you can use a paragraph of your own to test a text file need help

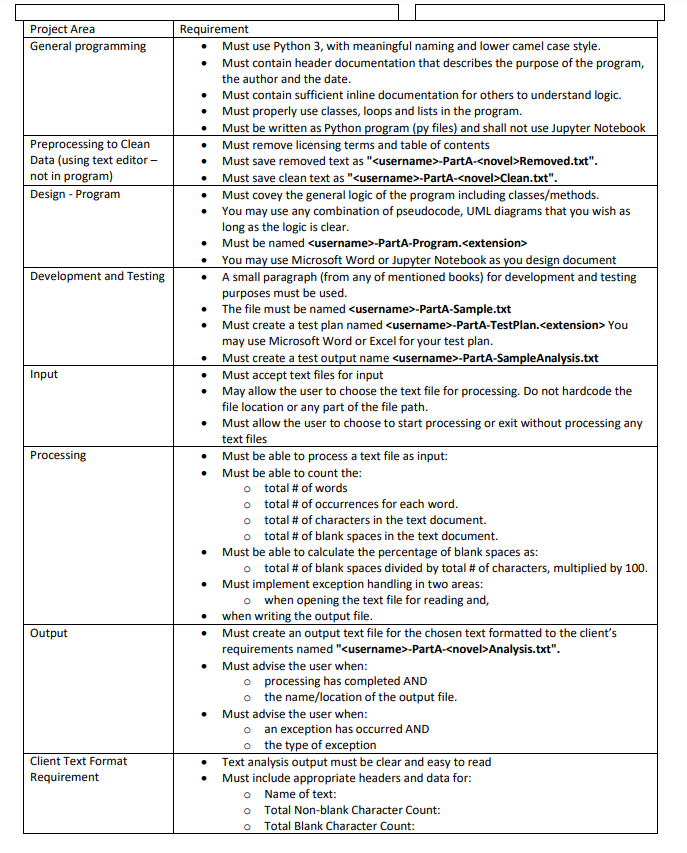

my code below changed actual file path to "file path".
you can use a paragraph of your own to test a text file
need help with input and output
total # of words
myfile = open ("C:file path", "r")
#print(myfile.read()) data = myfile.read()
words = data.split()
print ("Number of words is:", len(words))
********************************************************************************************
total # of occurrences for each word.
# Open the file in read mode myfile = open ("C:file path", "r")
# Create an empty dictionary dic= dict()
# Loop through each line of the file for line in myfile: # Remove the leading spaces and newline character line = line.strip() # Convert the characters in line to # lowercase to avoid case mismatch line = line.lower()
# Split the line into words words = line.split(" ")
# Iterate over each word in line for word in words:
# Check if the word is already in dictionary if word in dic:
# Increment count of word by 1 dic[word] = dic[word] + 1 else:
# Add the word to dictionary with count 1 dic[word] = 1
# Print the contents of dictionary for key in list(dic.keys()): print(key, ":", dic[key])
***************************************************************************************************
total # of characters in the text document.
num_char = 0
with open("C:file path", "r") as f: for line in f: words = line.split() num_char += len(line)
print ('Number of characters are:') print (num_char)
***************************************************************************************************
total # of blank spaces in the text document
myfile = open ("C:file path", "r")
count = 0
while True:
#this will read each character #then store in a char
char = myfile.read(1)
if char.isspace(): count += 1 if not char: break print ('Number of spaces is') print(count)
***************************************************************************************************
total # of blank spaces divided by total # of characters, multiplied by 100.
myfile = open ("C:file path", "r")
count = 0
while True:
#this will read each character #then store in a char
char = myfile.read(1)
if char.isspace(): count += 1 if not char: break #print ('Number of spaces is') #print(count)
#myfile = open ("C:file path", "r")
num_char = 0
with open("C:file path", "r") as f: for line in f: words = line.split() num_char += len(line)
#print ('Number of characters are:') #print (num_char)
#% of number of spaces per_space =(count / num_char * 100 )
two_decimal = "{:.2f}%".format(per_space) print ('The % of spaces equals', two_decimal)
Text analysis and the statistical distribution of words can tell us a lot about who wrote it and such an analysis of corporate emails was a key factor in the prosecution of corporation executives for insider trading. Specifically, the increasingly frequent use of pronouns in email was cited as a metric for detecting deceptive communication in that case. You will submit the following files compressed into a zip archive. 1. All python files for your program implementation. 2. Preprocessing files (6). 3. Design and Test documents (4) 4. The output text files (3) The client would eventually like to work along these lines, but for now wants you to expose some concepts about processing text so that they can determine how they to better analyze corporate documents as a first step. Submit your file on the Brightspace under the Project 1 Text Analysis. Since their internal documents are sensitive, they have asked you to analyze text copy of three novels: Charles Dickens' A Tale of Two Cities, Leo Tolstoy's War and Peace, and Victor Hugo's Les Miserables. The zip archive name must be formatted as follows: Each of these files is sourced from the Gutenberg Project (www.gutenberg.org). E.g. A Tale of Two Cities text file The files can be download along with these instructions from Project 1 on Brightspace.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Big Data Integration Theory Theory And Methods Of Database Mappings Programming Languages And Semantics
Authors: Zoran Majkic
1st Edition
3319355392, 978-3319355399