Need answers to the MCQs.
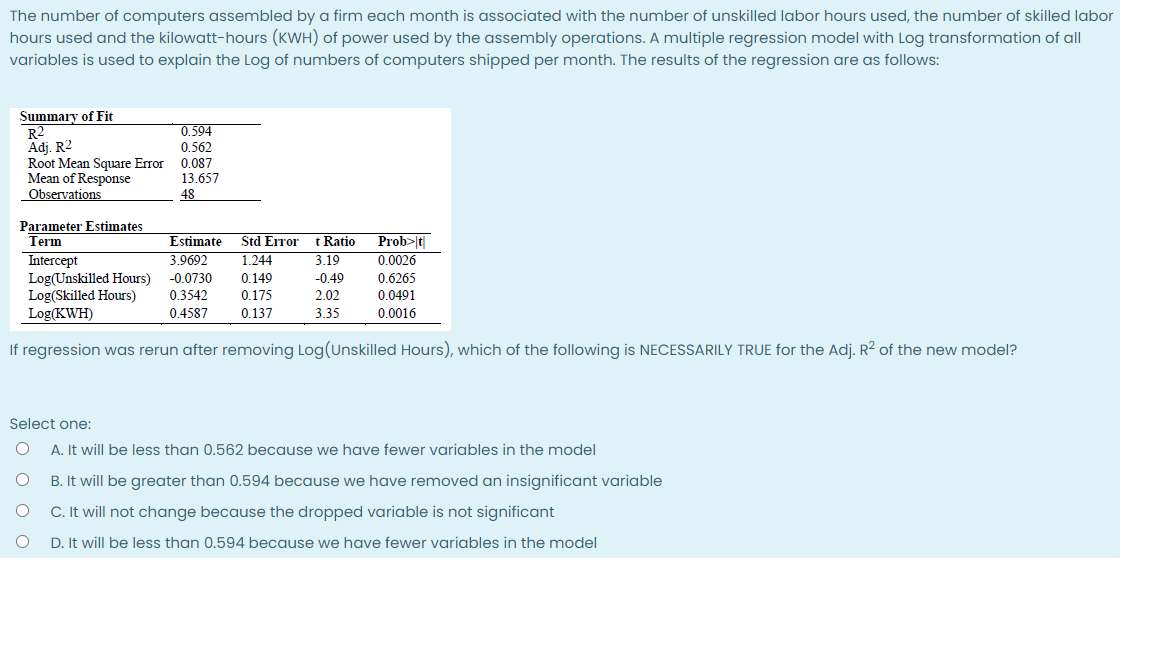
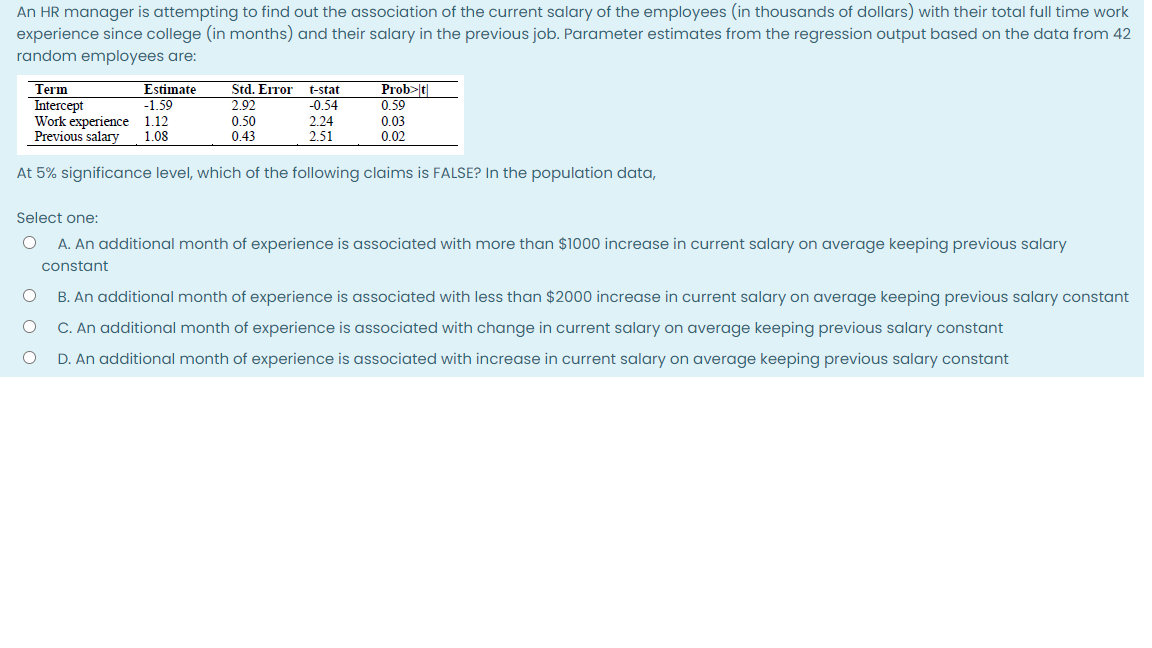
The COO of a retail pharmacy chain is concerned about inventory record inaccuracy and installs RFID technology in some retail outlets to correct the situation. To understand whether the new technology indeed reduced inaccuracies he asks an analyst to study the dataset of 43 retail stores collected at the end of a fiscal year when physical inventory was checked. The analyst runs the following regression model (at the store level) on the dataset: Response variable ( Y): %inaccu racy in inventory records Predictor variables (X) number of SKUs, onhand inventory for each SKU, total on hand inventory over all SKUs, RFID (a dummy variable, which equals I if the store has RFID technology and equals 0 if not), and number of employees. Which of the following statements is TRUE in this context of this model? Select one: O A. Multicollinearity is not a concern since we have categorical predictor variables O B. Multicollinearity is not a concern because there are no interaction variables among the predictor variables 0 C. Multicollinearity is a concern and it can be detected by running regressions of one predictor variable at a time against all other predictor variables O D. The coefficient of RFID, gives us a point estimate of the %inaccuracy of inventory records, on average, in stores with RFID technology The number of computers assembled by a firm each month is associated with the number of unskilled labor hours used, the number of skilled labor hours used and the kilowatt-hours (KWH) of power used by the assembly operations. A multiple regression model with Log transformation of all variables is used to explain the Log of numbers of computers shipped per month. The results of the regression are as follows: Summary of Fit R2 0.594 Adj. R2 0.562 Root Mean Square Error 0.087 Mean of Response 13.657 Observations 48 Parameter Estimates Term Estimate Std Error t Ratio Prob >t Intercept 3.9692 1.244 3.19 0.0026 Log(Unskilled Hours) -0.0730 0.149 -0.49 0.6265 Log(Skilled Hours) 0.3542 0.175 2.02 0.0491 Log (KWH) 0.4587 0.137 3.35 0.0016 If regression was rerun after removing Log (Unskilled Hours), which of the following is NECESSARILY TRUE for the Adj. R2 of the new model? Select one: O A. It will be less than 0.562 because we have fewer variables in the model O B. It will be greater than 0.594 because we have removed an insignificant variable O C. It will not change because the dropped variable is not significant O D. It will be less than 0.594 because we have fewer variables in the modelAn HR manager is attempting to find out the association of the current salary of the employees (in thousands of dollars) with their total full time work experience since college (in months} and their salary in the previousjob. Parameter estimates from the regression output based on the data from 42 random employees are: Term Estimate Std. Error tstat Prnb>|t| Intercept 1.59 2.92 -0.54 0.59 War]: We 1.12 0.50 2.24 0.03 Previous salary 1.08 0.43 2.51 0.02 At 5% significance level, which of the following claims is FALSE? In the population data, Select one: 0 A. An additional month of experience is associated with more than $1000 increase in current salary on average keeping previous salary constant 0 B. An additional month of experience is associated with less than $2000 increase in current salary on average keeping previous salary constant 0 C. An additional month of experience is associated with change in current salary on average keeping previous salary constant 0 D. An additional month of experience is associated with increase in current salary on average keeping previous salary constant An IT project manager wants to predict the average productivity of her software engineers, specifically the relationship between the number of lines of code written by engineers and the time taken to write them (hrs), Using past data on roughly 51 engineers, she establishes the following relationship: Estimated time {hrs} = 8 + 005 lines. The manager checks the residual plots and concludes that all assumptions, including that about the distribution of the error term, are satisfied. She also finds that 90% of the residuals lie between 1 5 hrs. What would be her APPROXIMATE 95% prediction interval for the time taken by one software engineer to write 1500 lines of code? Select one: 0 A. [77,89] 0 B. [81,87] 0 c. [74,81] 0 0. [74,80]