

Question: Need guidance writing these two functions * Stages the given file for commit * [TO BE WRITTEN] * @param[in] filename * File to be staged
Need guidance writing these two functions

![commit * [TO BE WRITTEN] * @param[in] filename * File to be](https://dsd5zvtm8ll6.cloudfront.net/si.experts.images/questions/2024/09/66f96c05c2a59_14966f96c0549e30.jpg)

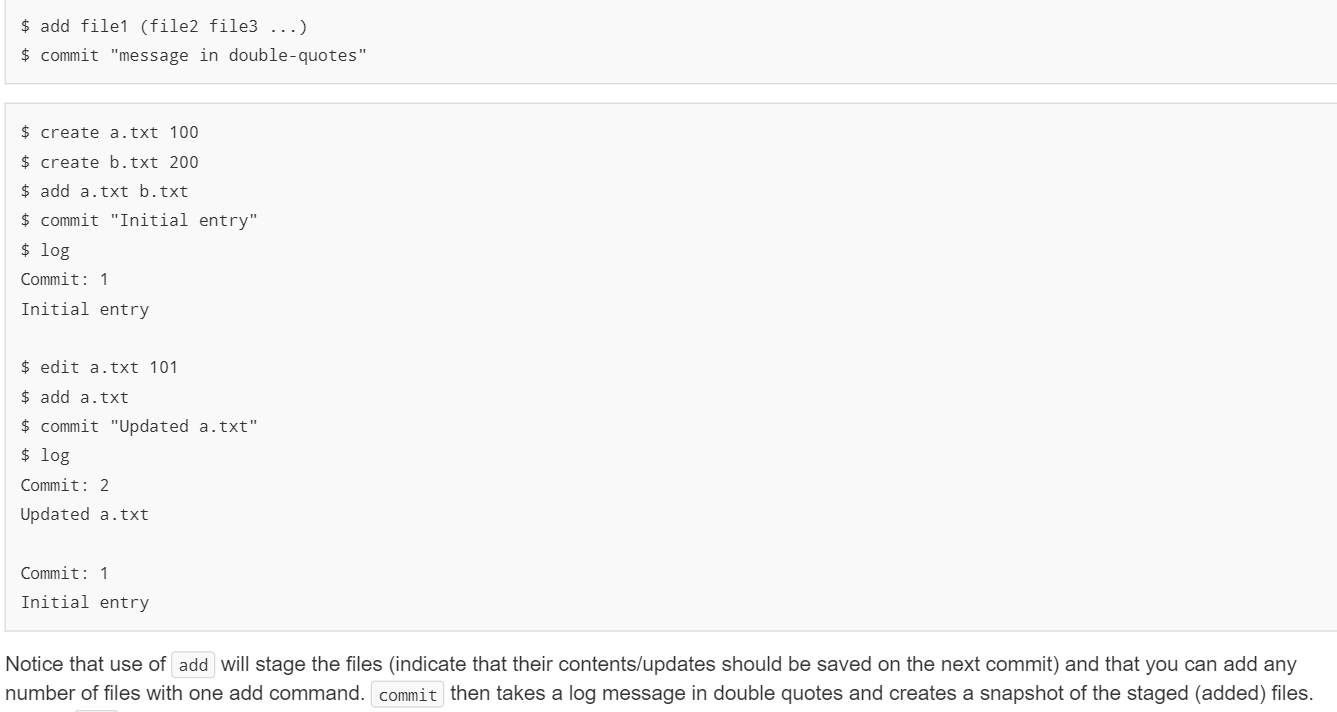
* Stages the given file for commit * [TO BE WRITTEN] * @param[in] filename * File to be staged and committed on the next commit command * @throws std::invalid_argument or std:: runtime_error - * See homework writeup for details on error cases void add(std::string filename); * Commits all files staged since the last commit * [TO BE WRITTEN] * @param[in] message Log message for this commit * @throws std::runtime_error - See homework writeup for details on error cases void commit(std::string message); /** * Associates a new tag name to the currently checked-out commit * [TO BE WRITTEN] * @param[in] tagname Name for this tag * @param[in] commit * Commit number/index to associate with the given tagname * @throws std::invalid_argument or std::runtime_error- * See homework writeup for details on error cases void create_tag(const std::string& tagname, CommitIdx commit); Approach First of all, note that the simple file format of a single integer allows simple associations of a filename ( string ) and an integer (int ). Thus, we will use maps to store this information. The actual Git tool does not store the entire file contents at each commit point. Often there are only a few text modifications to files between each commit. Thus, Git stores diffs (the additions or deletions between one version of a file and the next). While finding the diff between text strings/files is non-trivial, the diff of two integers is straigtforward through subtraction ( new-int-version - old-int-version ). Thus, we are going to require you to store the differences between each commit and not just the absolute file contents. Thus, if we commit a.txt first with 100 then commit it again with a value of 104 then perform a third commit with 110 for a.txt along with a newly created file b.txt with content 200 , then the first commit would store a.txt : 100 , the next would store a.txt : 4 , and the last commit would store a.txt : 6 and b.txt : 200. To aide you we have provided the following struct to store the difference between one commit and the next. ** * Integral type used to index Commits */ typedef int CommitIdx; ** * Container for data pertaining to each commit */ struct CommitObj { std::string msg_; std::map<:string int> diffs_; CommitIdx parent_; CommitObj const std::string& msg, std::map<:string int> diffs, CommitIdx parent); When we store the CommitObj s, it is required to store them in some form of list (you can choose an appropriate STL library implementation) where the index of the CommitObj will be used as the commit number. To clearly identify integers representing the index/id of a commit, we have made a typedef of int to CommitIdx. If you are unfamiliar with typedef s you can read more about them here. (Note: It might have been more appropriate to use an unsigned integer type like size_t as the CommitIdx type but we leave it as int to allow freedom in your implementation to use negative values to indicate INVALID or sentinel values. To avoid warnings about comparisons between unsigned and signed integral types, you may need to cast variables of type CommitIdx to size_t when you compare them to a vector's size. Feel free to do so.) Further, we require that the commits start their index numbering at 1 (not 0) and so location 0 can be filled with a "dummy" commit. Lastly, you must store the commits in TEMPORAL order (vs. any other potential ordering to try to reorder the commits to somehow group parent/child commits). Below is an illustration that roughly corresponds (other than log messages) to the example sequences given above. 1 parent: - msg : parent: 0 msg: "Msg1" diffs : { "a.txt": 100, "b.txt": 200} diffs : { } parent: 1 msg: "Msg2" diffs : { "a.txt":1} parent: 2 msg : "Msg3" diffs : { "b.txt":5} parent: 1 msg: "Msg4" diffs : { "b.txt": 50, "c.txt" : 300 } parent: 4 msg: "Msg5" diffs : { "a.txt" : 50} parent :3 msg: "Msg6" diffs : { "a.txt":1} Dummy Entry $ add filei (file2 file3 ...) $ commit "message in double-quotes" $ create a.txt 100 $ create b.txt 200 $ add a.txt b.txt $ commit "Initial entry" $ log Commit: 1 Initial entry $ edit a.txt 101 $ add a.txt $ commit "Updated a.txt" $ log Commit: 2 Updated a.txt Commit: 1 Initial entry Notice that use of add will stage the files indicate that their contents/updates should be saved on the next commit) and that you can add any number of files with one add command. commit then takes a log message in double quotes and creates a snapshot of the staged (added) files. * Stages the given file for commit * [TO BE WRITTEN] * @param[in] filename * File to be staged and committed on the next commit command * @throws std::invalid_argument or std:: runtime_error - * See homework writeup for details on error cases void add(std::string filename); * Commits all files staged since the last commit * [TO BE WRITTEN] * @param[in] message Log message for this commit * @throws std::runtime_error - See homework writeup for details on error cases void commit(std::string message); /** * Associates a new tag name to the currently checked-out commit * [TO BE WRITTEN] * @param[in] tagname Name for this tag * @param[in] commit * Commit number/index to associate with the given tagname * @throws std::invalid_argument or std::runtime_error- * See homework writeup for details on error cases void create_tag(const std::string& tagname, CommitIdx commit); Approach First of all, note that the simple file format of a single integer allows simple associations of a filename ( string ) and an integer (int ). Thus, we will use maps to store this information. The actual Git tool does not store the entire file contents at each commit point. Often there are only a few text modifications to files between each commit. Thus, Git stores diffs (the additions or deletions between one version of a file and the next). While finding the diff between text strings/files is non-trivial, the diff of two integers is straigtforward through subtraction ( new-int-version - old-int-version ). Thus, we are going to require you to store the differences between each commit and not just the absolute file contents. Thus, if we commit a.txt first with 100 then commit it again with a value of 104 then perform a third commit with 110 for a.txt along with a newly created file b.txt with content 200 , then the first commit would store a.txt : 100 , the next would store a.txt : 4 , and the last commit would store a.txt : 6 and b.txt : 200. To aide you we have provided the following struct to store the difference between one commit and the next. ** * Integral type used to index Commits */ typedef int CommitIdx; ** * Container for data pertaining to each commit */ struct CommitObj { std::string msg_; std::map<:string int> diffs_; CommitIdx parent_; CommitObj const std::string& msg, std::map<:string int> diffs, CommitIdx parent); When we store the CommitObj s, it is required to store them in some form of list (you can choose an appropriate STL library implementation) where the index of the CommitObj will be used as the commit number. To clearly identify integers representing the index/id of a commit, we have made a typedef of int to CommitIdx. If you are unfamiliar with typedef s you can read more about them here. (Note: It might have been more appropriate to use an unsigned integer type like size_t as the CommitIdx type but we leave it as int to allow freedom in your implementation to use negative values to indicate INVALID or sentinel values. To avoid warnings about comparisons between unsigned and signed integral types, you may need to cast variables of type CommitIdx to size_t when you compare them to a vector's size. Feel free to do so.) Further, we require that the commits start their index numbering at 1 (not 0) and so location 0 can be filled with a "dummy" commit. Lastly, you must store the commits in TEMPORAL order (vs. any other potential ordering to try to reorder the commits to somehow group parent/child commits). Below is an illustration that roughly corresponds (other than log messages) to the example sequences given above. 1 parent: - msg : parent: 0 msg: "Msg1" diffs : { "a.txt": 100, "b.txt": 200} diffs : { } parent: 1 msg: "Msg2" diffs : { "a.txt":1} parent: 2 msg : "Msg3" diffs : { "b.txt":5} parent: 1 msg: "Msg4" diffs : { "b.txt": 50, "c.txt" : 300 } parent: 4 msg: "Msg5" diffs : { "a.txt" : 50} parent :3 msg: "Msg6" diffs : { "a.txt":1} Dummy Entry $ add filei (file2 file3 ...) $ commit "message in double-quotes" $ create a.txt 100 $ create b.txt 200 $ add a.txt b.txt $ commit "Initial entry" $ log Commit: 1 Initial entry $ edit a.txt 101 $ add a.txt $ commit "Updated a.txt" $ log Commit: 2 Updated a.txt Commit: 1 Initial entry Notice that use of add will stage the files indicate that their contents/updates should be saved on the next commit) and that you can add any number of files with one add command. commit then takes a log message in double quotes and creates a snapshot of the staged (added) files
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts