

Question
please do this progrem in python, provide the flowcharts as well. If it is correct I will upvote! you can find a screenshot of the
please do this progrem in python, provide the flowcharts as well. If it is correct I will upvote!
you can find a screenshot of the structure you should follow in the end



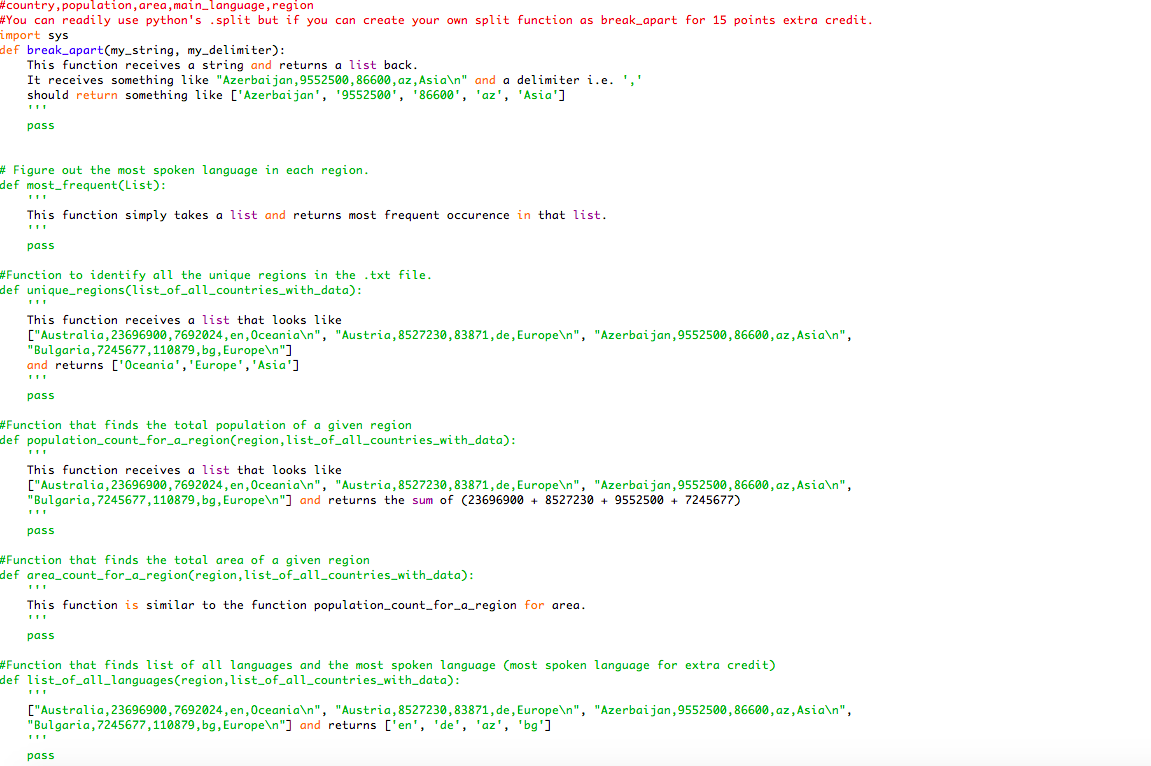

#country,population,area,main_language,region #You can readily use python's .split but if you can create your own split function as break_apart for 15 points extra credit. import sys def break_apart(my_string, my_delimiter): ''' This is for 10 points extra credit. This function receives a string and returns a list back. It receives something like "Azerbaijan,9552500,86600,az,Asia " and a delimiter i.e. ',' should return something like ['Azerbaijan', '9552500', '86600', 'az', 'Asia'] ''' pass
# Program to find most frequent # element in a list # Figure out the most spoken language in each region. def most_frequent(List): ''' This function simply takes a list and returns most frequent occurence in that list. ''' pass
#Function to identify all the unique regions in the .txt file. def unique_regions(list_of_all_countries_with_data): ''' This function receives a list that looks like ["Australia,23696900,7692024,en,Oceania ", "Austria,8527230,83871,de,Europe ", "Azerbaijan,9552500,86600,az,Asia ", "Bulgaria,7245677,110879,bg,Europe "] and returns ['Oceania','Europe','Asia'] ''' pass
#Function that finds the total population of a given region def population_count_for_a_region(region,list_of_all_countries_with_data): ''' This function receives a list that looks like ["Australia,23696900,7692024,en,Oceania ", "Austria,8527230,83871,de,Europe ", "Azerbaijan,9552500,86600,az,Asia ", "Bulgaria,7245677,110879,bg,Europe "] and returns the sum of (23696900 + 8527230 + 9552500 + 7245677) ''' pass
#Function that finds the total area of a given region def area_count_for_a_region(region,list_of_all_countries_with_data): ''' This function is similar to the function population_count_for_a_region for area. ''' pass
#Function that finds list of all languages and the most spoken language (most spoken language for extra credit) def list_of_all_languages(region,list_of_all_countries_with_data): ''' ["Australia,23696900,7692024,en,Oceania ", "Austria,8527230,83871,de,Europe ", "Azerbaijan,9552500,86600,az,Asia ", "Bulgaria,7245677,110879,bg,Europe "] and returns ['en', 'de', 'az', 'bg'] ''' pass
if __name__ == "__main__": file_name = input('What file do you want to parse?: ')
try: with open(file_name) as my_file: list_of_all_lines = my_file.readlines() except: print('File not found.') sys.exit(1)
#Your code here. Here you call all the necessary function and print everything as needed.
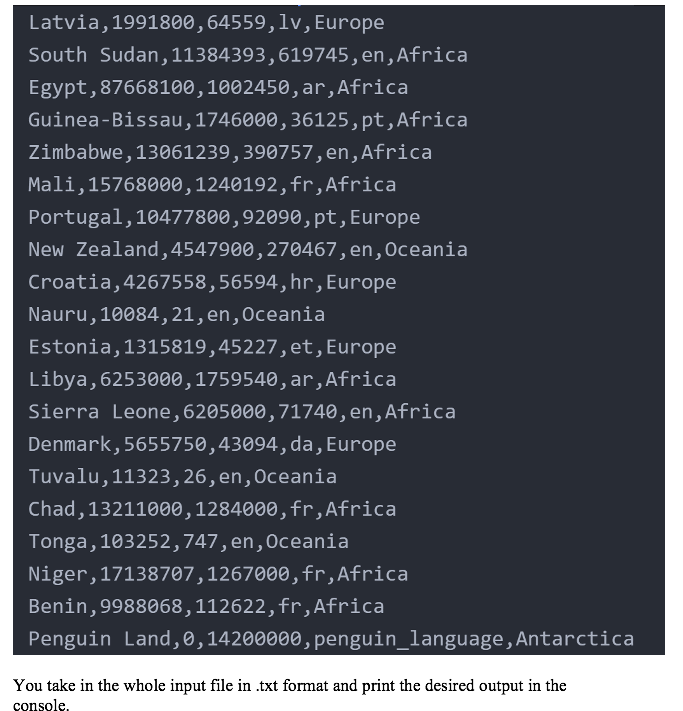
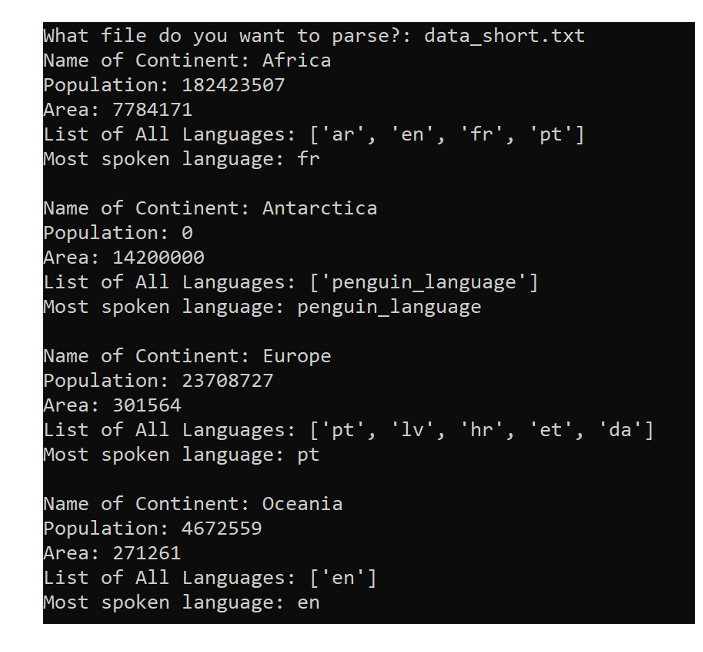
Problem Specification Your program is to calculate the continent information based on an input file. Each input file contains the meta-information in the following order. 1) Name of country 2) Population of country 3) Area of country 4) Main language 5) Continent For example, the data_short.txt as input looks like: 3 Latvia, 1991800, 64559, lv, Europe South Sudan, 11384393,619745, en, Africa Egypt, 87668100,1002450, ar, Africa Guinea-Bissau, 1746000, 36125, pt, Africa Zimbabwe, 13061239,390757, en, Africa Mali,15768000, 1240192, fr, Africa Portugal, 10477800,92090, pt, Europe New Zealand, 4547900, 270467, en, Oceania Croatia, 4267558,56594, hr, Europe Nauru, 10084,21, en, Oceania Estonia, 1315819,45227, et, Europe Libya, 6253000, 1759540, ar, Africa Sierra Leone, 6205000,71740, en, Africa Denmark, 5655750,43094, da, Europe Tuvalu, 11323, 26, en, Oceania Chad, 13211000, 1284000, fr, Africa Tonga, 103252,747, en, Oceania Niger, 17138707,1267000, fr, Africa Benin, 9988068, 112622, fr, Africa Penguin Land, 0,14200000, penguin_language, Antarctica You take in the whole input file in .txt format and print the desired output in the console. You take in the whole input file in .txt format and print the desired output in the console. You need to parse each line for the given txt file and find out the total population, total area, languages spoken for each continent that must be sorted. The output should contain the metainformation in the following order: 1. Name of Continent: String 2. Population: int 3. Area: int 4. List of All Languages: list of String 5. Most Spoken Language: String . The output for data_short.txt is as follows: What file do you want to parse?: data_short.txt Name of Continent: Africa Population: 182423507 Area: 7784171 List of All Languages: ['ar', 'en', 'fr', 'pt'] Most spoken language: fr Name of Continent: Antarctica Population: 0 Area: 14200000 List of all Languages: ['penguin_language'] Most spoken language: penguin_language Name of Continent: Europe Population: 23708727 Area: 301564 List of All Languages: ['pt', 'lv', 'hr', 'et', 'da'] Most spoken language: pt Name of Continent: Oceania Population: 4672559 Area: 271261 List of All Languages: ['en'] Most spoken language: en Name of Continent is the name for each continent. In the console, the name shall be sorted Population is the total population of each continent. Area is the total area of each continent. List of all languages is the collection of all languages spoken in that continent. Most spoken language is the language spoken by most countries in the continent. . Flowchart You must design a flowchart for each function to illustrate how function is designed. Also, you need to design a flowchart to show how the drive code is designed in terms of how inputs are received, and the functions are called. * The output should match exactly. #country, population, area,main_language, region #You can readily use python's .split but if you can create your own split function as break_apart for 15 points extra credit. import sys def break_apart(my_string, my_delimiter): This function receives a string and returns a list back. It receives something like "Azerbaijan, 9552500, 86600, az, Asia " and a delimiter i.e. ',' should return something like ['Azerbaijan', '9552500', '86600', 'az', 'Asia'] pass # Figure out the most spoken language in each region. def most frequent(List): This function simply takes a list and returns most frequent occurence in that list. pass #Function to identify all the unique regions in the .txt file. def unique_regions(list_of_all_countries_with_data): This function receives a list that looks like ["Australia, 23696900,7692024, en, Oceania ", "Austria, 8527230,83871, de, Europe ", "Azerbaijan, 9552500, 86600, az, Asia ", "Bulgaria, 7245677, 110879, bg, Europe "] and returns ['Oceania', 'Europe', 'Asia'] II pass #Function that finds the total population of a given region def population_count_for_a_region(region, list_of_all_countries_with_data): This function receives a list that looks like ["Australia, 23696900, 7692024, en, Oceania ", "Austria, 8527230,83871, de, Europe ", "Azerbaijan, 9552500, 86600, az, Asia ", "Bulgaria, 7245677,110879, bg, Europe "] and returns the sum of (23696900 + 8527230 + 9552500 + 7245677) pass #Function that finds the total area of a given region def area_count_for_a_region(region, list_of_all_countries_with_data): This function is similar to the function population_count_for_a_region for area. pass #Function that finds list of all languages and the most spoken language (most spoken language for extra credit) def list_of_all_languages(region, list_of_all_countries_with_data): ["Australia, 23696900,7692024, en, Oceania ", "Austria, 8527230,83871, de, Europe ", "Azerbaijan, 9552500, 86600,az, Asia ", "Bulgaria, 7245677,110879, bg, Europe "] and returns ['en', 'de', 'az', 'b'] pass pass 1 if __name_- -- file_name "__main__": input('What file do you want to parse?:') try: with open(file_name) as my_file: list_of_all_lines my_file.readlines) except: print('File not found.') sys.exit(1) #Your code here. Here you call all the necessary function and print everything as neededStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Postgresql 16 Administration Cookbook Solve Real World Database Administration Challenges With 180+ Practical Recipes And Best Practices
Authors: Gianni Ciolli ,Boriss Mejias ,Jimmy Angelakos ,Vibhor Kumar ,Simon Riggs
1st Edition
1835460585, 978-1835460580