

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Problem 2: Spotify Linear Regression Are louder songs more energetic? Can you predict the energy of a song based on the song's loudness, is
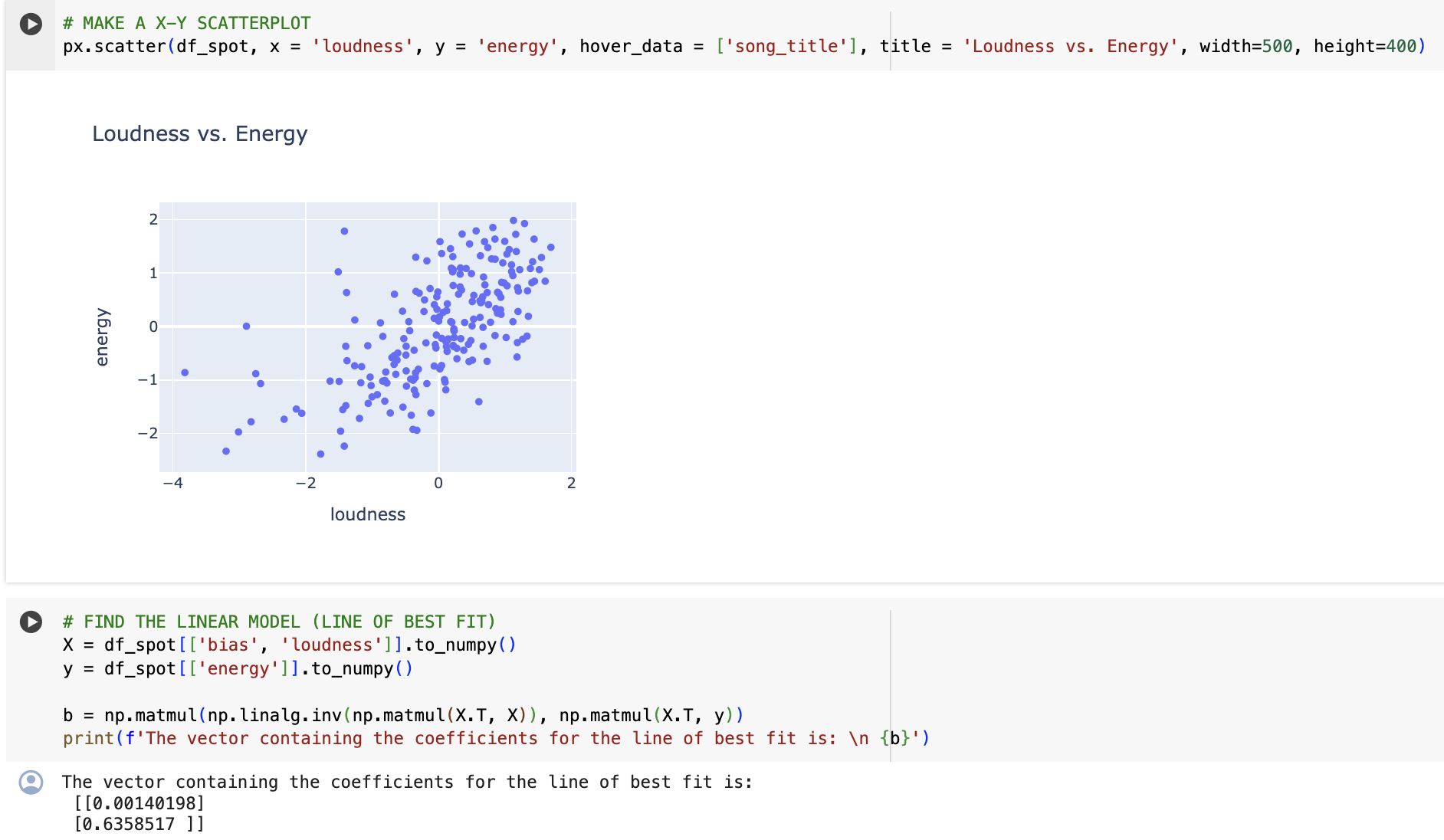
Problem 2: Spotify Linear Regression Are louder songs more energetic? Can you predict the energy of a song based on the song's loudness, is the relationship between them linear, and if so can you trust the model? Let's explore this by conducting a linear regression using X (loudness) and y (energy) from our Class Spotify. Playlist. # this code assumes you've run the code from 1.b) so that you have df_spot_raw to update: # subsets to only include features of interest and adds bias column df_spot = df_spot_raw [["loudness", "energy", "song_title", "artist_name"]] df_spot.insert(loc=0, column='bias', value=1) df_spot. head() bias loudness energy song_title artist_name 0 1 1.181381 -0.571429 moon and back JVKE 1 1 -0.339746 -1.275132 Slow Dancing in a Burning Room John Mayer 2 1 0.184129 0.089947 Minefield Nic D 3 1 0.228100 -0.375661 Wishes Hasan Raheem 4 1 -0.345586 -0.867725 Goodbye Yellow Brick Road Elton John Problem 2 (a: 20 points) Based on the output from the code cells below, answer these questions in the following markdown cell: Based on the x-y scatterplot, do you think a simple linear regression model will be appropriate for modeling the relationship between loudness and energy? Interpret the intercept and slope of the linear model practically (i.e. what does each mean in terms of the relationship between loudness and energy? recall that the data have been scaled, so a value of O means an average value and a value of 1 or -1 means one standard deviation above or below the average.) Use the linear model to predict (you can do this by hand and don't have to show work) the energy of Dr. Gerber's favourite song, Mr. Brightside, which has a loudness of x = 0.848849. The actual energy of Mr. Brightside is y = 1.634921; is it under- or over-predicted by the model? # MAKE A X-Y SCATTERPLOT px.scatter(df_spot, x = 'loudness', y = 'energy', hover_data = ['song_title'], title = 'Loudness vs. Energy', width=500, height=400) Loudness vs. Energy energy 2 1 0 -1 -2 -4 -2 0 2 loudness # FIND THE LINEAR MODEL (LINE OF BEST FIT) X = df_spot [ ['bias', 'loudness']].to_numpy ( ) y = df_spot [['energy']].to_numpy() b = np.matmul(np.linalg.inv(np.matmul(X.T, X)), np.matmul(X.T, y)) print (f'The vector containing the coefficients for the line of best fit is: {b}') The vector containing the coefficients for the line of best fit is: [[0.00140198] [0.6358517 ]]
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Elementary Statisitcs
Authors: Barry Monk
2nd edition
1259345297, 978-0077836351, 77836359, 978-1259295911, 1259295915, 978-1259292484, 1259292487, 978-1259345296