

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Q 1 : The following sentence is partially tagged with POS Tags, where bear can be either a VB ( verb ) or a NN
Q: The following sentence is partially tagged with POS Tags, where "bear" can be either a VB verb or a NN noun:
YourPPR$ effortsNN willMD bear fruitNN
Which formulas can calculate the most probable tag sequence for "bear"?
PbearNN PNNVBPVBNN
PbearVBPVBMDPNNVB
PwillMDPbearVB PfruitNN
PNNNN PNNMDPbearNN
PbearVBPVBNNPVBMD
A
B
C
D
E
Q: The following sentence is partially tagged with POS Tags, where "race" can be either a VB verb or a NN noun:
SecretariatNNP isVBZ expectedVBN toTO race tomorrowNR
Which formulas can calculate the most probable tag sequence for "race"?
Q: What is cosine similarity? How to calculate it
Q: TFIDF helps to establish how important a particular word is in the context of the document corpus. TFIDF takes into account the number of times the word appears in the document and is offset by the number of documents that appear in the corpus.
TF is the frequency of terms divided by the total number of terms in the document.
IDF is obtained by dividing the total number of documents by the number of documents containing the term and then taking the logarithm of that quotient.
TFIDF is then the multiplication of two values TF and IDF.
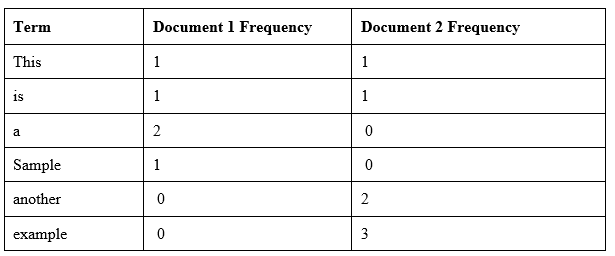
Suppose that we have term count tables of a corpus consisting of only two documents, as in the picture table:
Calcuate TFIDFs for the term example for Document and Document respectively.
Q: Describe Yarowsky's technique for word sense disambiguation and illustrate how it would disambiguate the following two senses of "sake":
Sense : sake, interest a reason for wanting something done: "for your sake", "died for the sake of his country"
Sense : sake, saki, rice beer Japanese alcoholic beverage made from fermented rice, usually served hot
Q: Suppose you want to develop a new approach to summarization that extracts phrases rather than full sentences and puts together the phrases to form a sentence for the summary. Many summarization systems use language models. Please clearly explain your algorithm. You can draw a diagram of the summarization system architecture to help you answer this question.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
OpenStack Trove
Authors: Amrith Kumar, Douglas Shelley
1st Edition
1484212215, 9781484212219