

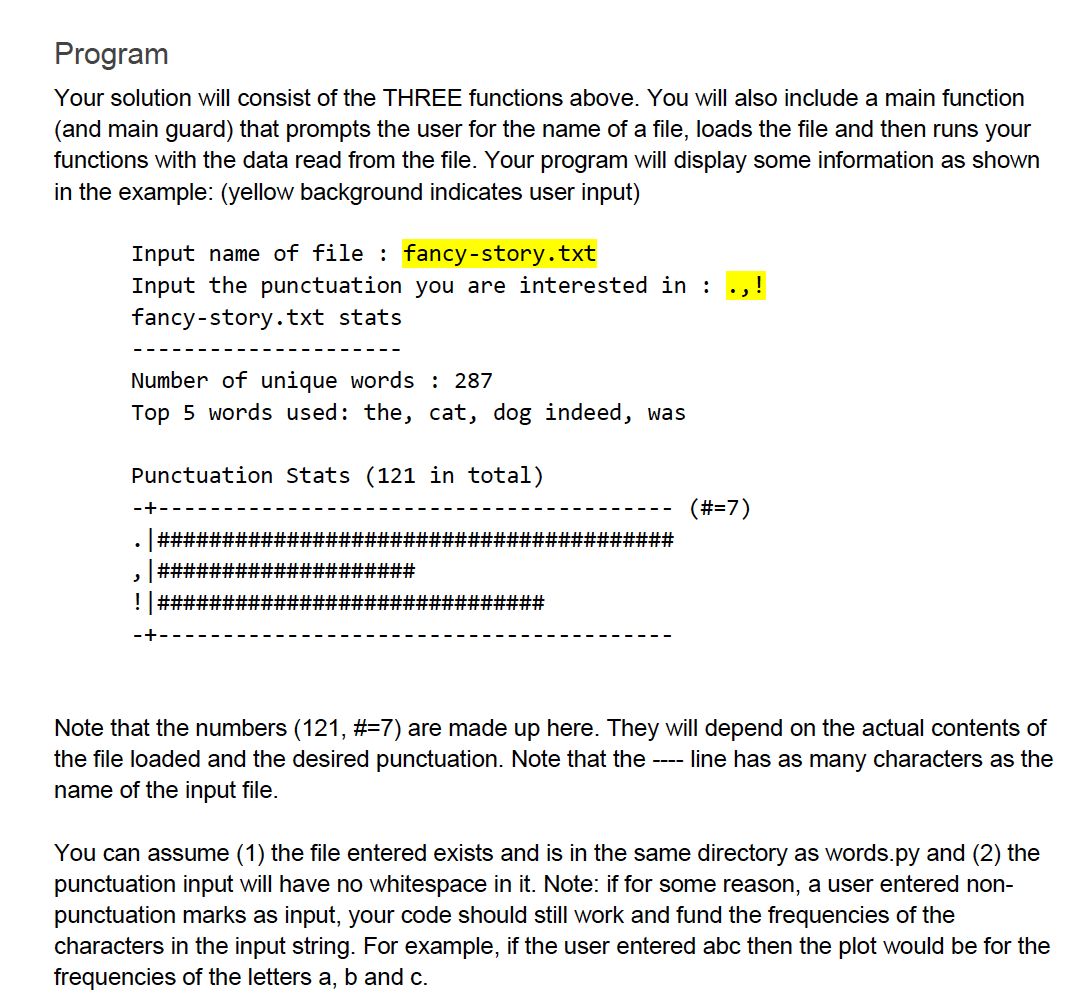
Q1: Word Stats [40 marks] In this problem you will generate some statistics for a body of text (English text). You are NOT allowed to import any modules to help with this. You will write the following functions (in a file called words.py): unique_words( text : str ) -> list: The function takes a body of text (string) and outputs (returns) a list of all unique words in the text. The output list will contain strings. For example, calling unique_words( "The,. cat. Live's in the! the road.") will return the list [ "the", "cat", "live's", "road", "in" ] Notice that punctuation is removed from the words. Notice that all words in the output are lower- case. Notice the word 'the only appears once in the output list. The order of the words in the output list does NOT matter. top_words ( text : str, number : int) -> list The function body of text (string) and an integer. The function returns a list of tuples. Each tuple will look like (word, frequency) where word is a string and frequency is the number of times that word appears in the input text. The returned list will have number" tuples in it that correspond to the "number most frequently used words in the input text. For example, calling top_words ("cat dog cat. Dog cat cat kitten.", 2) will return the list (of tuples) [("cat", 4), ("dog", 2)] Notice that the most frequently used word appears first. Your list must return the tuples in decreasing order (based on frequency of the word appearing). Again, we don't care about the case of words. All outputs should be in lower-case. What if "number" is larger than the actual number of unique words in the text? Only make your output list as big as needed to include all unique words. What if there are multiple words with the same frequency? Your output list can have more than "number" tuples in it. When you creating your output list, if you reach "number" words and there are more words with the same frequency then you should include the rest of the words with that frequency. For example, suppose you wanted the top 2 words, but the data was as follows: 'cat' appears 10 times 'dog' appears 7 times feel' appears 7 times 'cow' appears 4 times The output list would be [('cat', 10), ('dog', 7), ('eel', 7)]. The order of the dog and eel do not matter. display_punctuation_stats ( text : str, punctuation : str ) -> str The function takes body of text (string) and a string consisting of punctuation characters. The function outputs (returns) a string that when printed will be a visual display (frequency plot) of the frequency that each punctuation character appears in the text. Note that the function returns a string. When that string is later printed, it is a plot of the frequencies of the punctuation marks. Example, if text "the, c!a!t. Sits.. on, the! Bed's edge." Then calling print ( display_punctuation_stats (text, ".2,!'")) will display the following on the screen (output is shown in yellow background with blue font; no spaces at the end of any line; newline at the end of each line EXCEPT the last) Punctuation Stats (10 in total) (#=10) # ####################################### ? | ###### # ### ##### The order of the punctuation marks follows the same order as the input string. The punctuation with the maximal count will display 40 hash-tags. All others are scaled using the same scale (to make the max 40 #'s). The second line indicates how the scaling factor. You can round to the nearest integer when doing your scaling. Program Your solution will consist of the THREE functions above. You will also include a main function (and main guard) that prompts the user for the name of a file, loads the file and then runs your functions with the data read from the file. Your program will display some information as shown in the example: (yellow background indicates user input) Input name of file : fancy-story.txt Input the punctuation you are interested in: .,! fancy-story.txt stats Number of unique words : 287 Top 5 words used: the, cat, dog indeed, was Punctuation Stats (121 in total) (#57) ############## |######################### ### ! ## Note that the numbers (121, #=7) are made up here. They will depend on the actual contents of the file loaded and the desired punctuation. Note that the ---- line has as many characters as the name of the input file. You can assume (1) the file entered exists and is in the same directory as words.py and (2) the punctuation input will have no whitespace in it. Note: if for some reason, a user entered non- punctuation marks as input, your code should still work and fund the frequencies of the characters in the input string. For example, if the user entered abc then the plot would be for the frequencies of the letters a, b and c




