
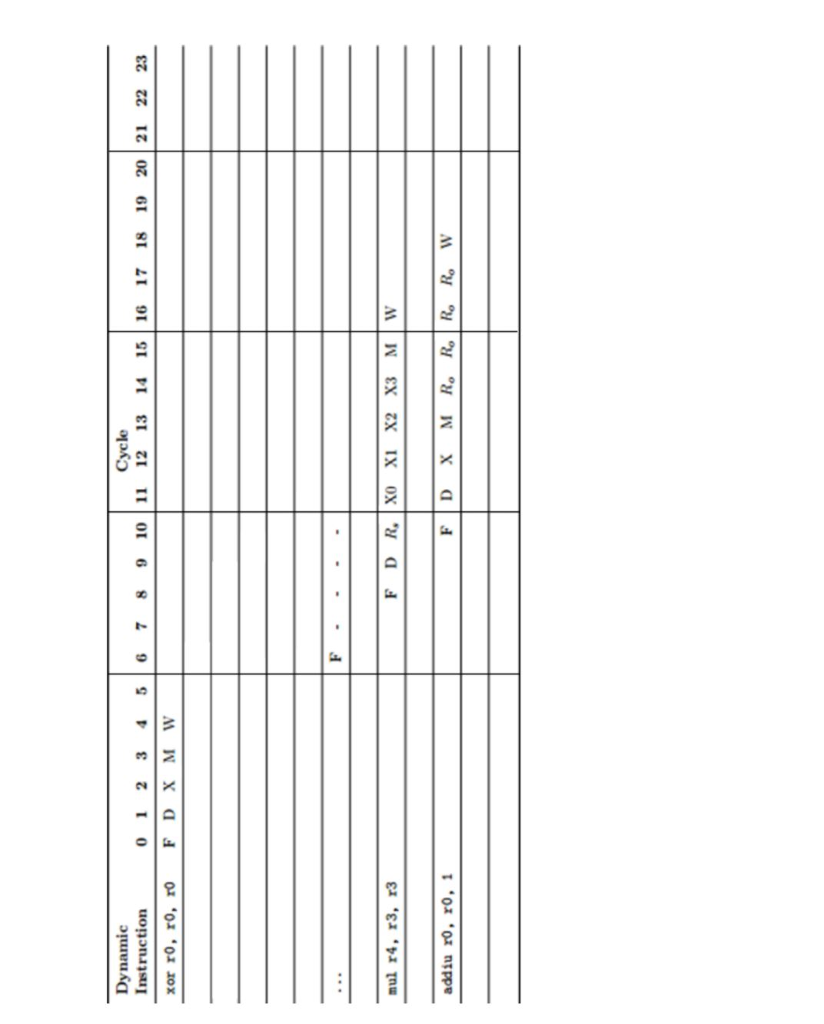
Question 4. Out-of-Order Execution (18 points) This question is based on the same pipeline and code as question 2 Consider the MIPS assembly code given below. We want to run this code on a 5-stage pipelined processor, with some modifications. The processor is a typical 5-stage pipeline (F-D-X-M-W), with the following exception . The multiplier block used to execute the mul instruction is pipelined into four stages: This means that a multiply instruction runs through the pipeline as follows: F-D-X0- X1-X2-X3-M-W and up to four multiply instructions maybe in-flight at a time. . This processor supports out-of-order execution of instructions xor r0, r0, rO addiu rl, r0, 10 j L1 loop: lw r3, 0(r2) mul r4, r3, r: mul r3, r3, r'1 addiu r0, r0, 1 sw r3, 0(r2) addiu r2, r2, 4 2 4 7 8 10 L1: bne r0, rl, -7 Assume the processor has data bypassing. This includes Execute-to-Execute and Memory-to-Execute forwarding, as well as the branch/jump target addresses bypassed from Execute-to-Fetch. Please complete the pipeline diagram (table) below showing the execution of the MIPS code, with bypassing, through the first iteration of the loop. Please show, with an arrow, any forwarding that is performed. What is the CPI of the entire program? Please use R, to denote an instruction is waiting execute and resides within the reservation station, use Ro to denote an instruction has completed execution, but is waiting to be written back and is residing within the reorder buffer Question 4. Out-of-Order Execution (18 points) This question is based on the same pipeline and code as question 2 Consider the MIPS assembly code given below. We want to run this code on a 5-stage pipelined processor, with some modifications. The processor is a typical 5-stage pipeline (F-D-X-M-W), with the following exception . The multiplier block used to execute the mul instruction is pipelined into four stages: This means that a multiply instruction runs through the pipeline as follows: F-D-X0- X1-X2-X3-M-W and up to four multiply instructions maybe in-flight at a time. . This processor supports out-of-order execution of instructions xor r0, r0, rO addiu rl, r0, 10 j L1 loop: lw r3, 0(r2) mul r4, r3, r: mul r3, r3, r'1 addiu r0, r0, 1 sw r3, 0(r2) addiu r2, r2, 4 2 4 7 8 10 L1: bne r0, rl, -7 Assume the processor has data bypassing. This includes Execute-to-Execute and Memory-to-Execute forwarding, as well as the branch/jump target addresses bypassed from Execute-to-Fetch. Please complete the pipeline diagram (table) below showing the execution of the MIPS code, with bypassing, through the first iteration of the loop. Please show, with an arrow, any forwarding that is performed. What is the CPI of the entire program? Please use R, to denote an instruction is waiting execute and resides within the reservation station, use Ro to denote an instruction has completed execution, but is waiting to be written back and is residing within the reorder buffer




