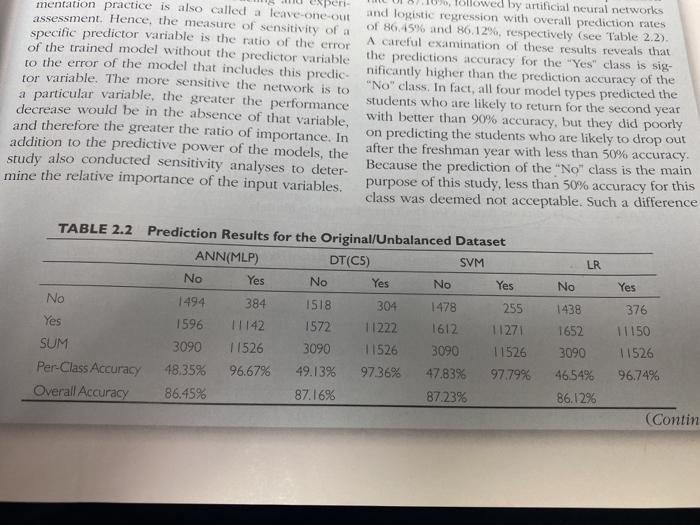
Question 8 0 / 1 point By looking at Tables 2.2 and 2.4, you can see that the overall accuracy is higher for all models when using the original/unbalanced dataset. Why does the case conclude that using the balanced dataset produces better prediction models? a) because we are interested in better per-class accuracy for the "No" outcome b) because lower overall accuracy indicates better predictive performance c) because we are interested in better per-class accuracy for the "Yes" outcome d) because the balanced dataset has fewer observations peri Ollowed by artificial neural networks mentation practice is also called a leave-one-out and logistic regression with overall prediction rates assessment. Hence, the measure of sensitivity of a of 86.45% and 86,12%, respectively (see Table 2.2) specific predictor variable is the ratio of the error A careful examination of these results reveals that of the trained model without the predictor variable the predictions accuracy for the "Yes" class is sig. to the error of the model that includes this predicnificantly higher than the prediction accuracy of the tor variable. The more sensitive the network is to "No" class. In fact, all four model types predicted the a particular variable, the greater the performance students who are likely to return for the second year decrease would be in the absence of that variable, with better than 90% accuracy, but they did poorly and therefore the greater the ratio of importance. In on predicting the students who are likely to drop out addition to the predictive power of the models, the after the freshman year with less than 50% accuracy. study also conducted sensitivity analyses to deter- Because the prediction of the "No" class is the main mine the relative importance of the input variables. purpose of this study, less than 50% accuracy for this class was deemed not acceptable. Such a difference LR No Yes TABLE 2.2 Prediction Results for the Original/Unbalanced Dataset ANN(MLP) DTCCS) SVM No Yes No Yes No Yes No 1494 384 1518 304 1478 255 Yes 1596 11142 1572 11222 1612 11271 SUM 3090 11526 3090 11526 3090 11526 Per-Class Accuracy 18.35% 96.67% 49.13% 97.36% 47.83% 97.79% Overall Accuracy 86.45% 87.16% 87.23% 1438 1652 3090 46,54% 86.12% 376 11150 11526 96.74% (Contin slightly les 80.21%, respect beren r systems 1111111111 analyse duce more robust prediction warmel types th are shown in Med on the back simple results, sup- found in Chapter 0. we one in generated the best h 81.1846, followed by for each model type, a of the M the prediction results are the eyed and individual models, ensembles single-best prediction model (more on In addition to assessing the prediction sensitivity da neural networks, and logis conducted using the developed prediction ent variables (.e., the predictors). In te with an overall prediction accuracy of to identify the relative importance and As can be seen in the TABLE 24 Prediction Results for the Three Ensemble Models Bagging Boosting (Boosted Trees) (Random Forest) No Yes Yes No No NO 2242 375 2327 362 2335 es 848 2715 763 2728 755 SUM 3090 3090 3090 3090 3090 72.56% 87.86% 75.31% 88.28% 75.57% 80.21% 81.80% 82.10% Information Fusion (Weighted Average) Yes 351 2739 3090 88.64% Per Class Accuracy Overall Accuracy