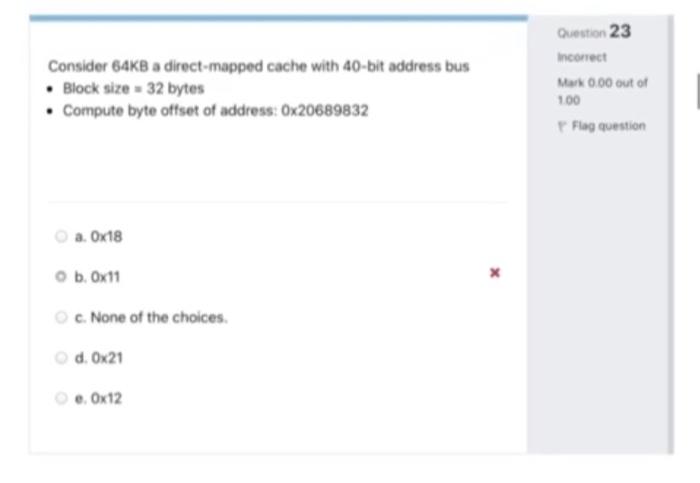
Reorder buffer (ROB) is a buffer for holding the status and the results of the instructions Question 9 Incorrect Mark 0.00 out of 0.25 Flag question Select one: True Falsex Dynamic (out-of-order) superscalar processors do not guarantee that instructions are written back in strict program order. Question 15 incorrect Mark 0.00 out of 0.25 Flag question Select one: True x False A fully-associative cache will always be filled (after initial startup) and will only evict an entry when space for a new entry is required. Question 16 Incorrect Mark 0.00 out of 0.25 Pag question Select one: True Falsex 8KB 2-way set-associative cache with a Least Recently Used (LRU) replacement policy will always have better or equal cache performance when compared to a 4KB direct-mapped cache, Question 21 Incorrect Mark 0.00 out of 100 Flag question Select one: True Falsex Consider 64KB a direct-mapped cache with 40-bit address bus Block size - 32 bytes Compute byte offset of address: Ox20689832 Question 23 incorrect Mark 0.00 out of 100 Flag question a. Ox18 b. Ox11 c. None of the choices. d. Ox21 e. Ox12 Adding a memory cache never hurts performance. Oestion 25 incorrect Mark 0.00 out of 0.25 Flag question Select one: True * False Which program will benefit most from a cache? Question 30 Incorrect Mark 0.00 out of 0.25 Flag question a. None of the choices. b. A program that never uses the same data twice. c. A program that randomly processes its data d. A program that repeatedly processes a small chunk of data before moving on e. A program that repeatedly processes a huge chunk of data all at once In set associative replacing policy LRU, the counter of the new block is set to 'O and all the others are incremented by one when occurs. Question 38 incorrect Mark 0.00 out of 100 Pag question a. None of the choices b. Stall c. Delay d. Miss e. Hit x Question 40 Incorrect Mark 000 out of 1.00 Flag question Consider the following floating-point loop for computing the sum of arrays XI and YO (X) = 0 . Y using a micro-architecture with a fully pipelined FP Unit and internal forwarding: Loop: LD F1, 0(R1) LDF2, (R2) ADD.D F2, F2, F1 SD F2, (R1) SUBIRI, R1, #-8 SUBI R2, R2, #-8 BNE RI, R3, Loop The latency of data dependent instructions is as follows: (1) 2 clocks for Load-FP, (2) 3 clocks for FP-Store, and (3) 1 clock following each Condition Branching. Unroll the above loop for the least number of times so that to eliminate all the stalls. Evaluate the CPI of the unrolled loop and its speedup S over the original loop. a. CP-1 and S-1377 b. CPI-8/7 and S=185 C. CPIw15/7 and S-13/7 d. CPl: 13/7 and S-1 e. CPI-1217 and S-2 Temporal locality is addressed by bringing in blocks of data instead of just the one word that is needed for a particular reference, Question 45 incorrect Mark 0.00 out of 0.25 Flag question Select one: True x False The policy for memory hierarchies: L1 data are never found in an L2 cache, refers to Question 47 incorrect Mark 0.00 out of 100 Flag question a. Write-through b. No Write Allocate oc. Write Allocate d. Write buffer e. Write-back Question 48 Incorrect Mark 0.00 out of 100 Flag question To apply write allocate technique between two cache levels L1 and L2 in a multi-level cache hierarchy, which of the following is/are necessary? A. L1 must be a write-through cache B. L2 must be a write-through cache C. The associativity of L2 must be greater than that of L1 D. The L2 cache must be at least as large as the L1 cache a. A and Donly b. A, C and Donly c. Donly d. A only e. All of them. The algorithm which replaces the block which has been referenced for a while is called Question 56 Incorrect Mark 0.00 out of 1.00 Flag question a. Random b. FIFO (First In First Out) c. LIFO (Last In First Out) d. LRU (Least Recently Used) e. None of the choices . MRU (Most Recently Used)