

Question
Repeat policy when there is a Grid World as shown below.There are [up, down, left, right] actions that can be taken at all points, and
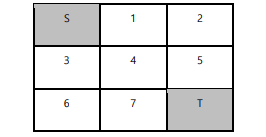
Repeat policy when there is a Grid World as shown below.There are [up, down, left, right] actions that can be taken at all points, and each action The reward (R) for this is -1. The initial policy has uniform probabilities in all directions. just 11,When moving to Terminal (T) in the 15 state, the reward is 10.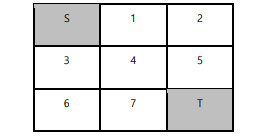
A. Perform policy evaluation 3 times and display the value function when k=1, 2, 3 in tabular form. The initial value (k=0) value for all states is set to 0, and the value functions of the start (S) and end (T) parts are not calculated. B. Find a greedy policy by performing a policy improvement based on the value function for K=3. In the state s, the greedy policy takes only the action with the largest action-value q among the actions that can be taken in s (the probability of performing another action is 0). And the probability of transitioning to another state when each action is taken is assumed to be zero. That is, when an action goes down from 9, the probability of going to 8, 10, or 5 other than 13 is 0. C. Based on the greed policy obtained from B, perform A to evaluate the policy and repeat B.
d.In problem b, derive the optimal policy through value iteration.
\begin{tabular}{|c|c|c|} \hline S & 1 & 2 \\ \hline 3 & 4 & 5 \\ \hline 6 & 7 & T \\ \hline \end{tabular} \begin{tabular}{|c|c|c|} \hline S & 1 & 2 \\ \hline 3 & 4 & 5 \\ \hline 6 & 7 & T \\ \hline \end{tabular}Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Corporate Financial Accounting
Authors: Carl S. Warren, James M. Reeve, Jonathan Duchac
13th edition
1285868781, 978-1285868783