

RL simulation You are walking towards home when you see a troll sleeping under a bridge. You
Question:
RL simulation
You are walking towards home when you see a troll sleeping under a bridge. You know you have two choices: approach the bridge as planned, or wake up the troll and see what happens. If you approach the bridge, you can either run across it, or dance across it. You form the following initial estimates of the Q values for the various possible (state, action) pairs:
Q(start, approach bridge) = 0.1
Q(start, wake troll) = 0
Q(at bridge, run) = 0.1
Q(at bridge, dance) = 0
Unbeknownst to you at the time: Reaching the bridge will give you a reward of +4. Waking the troll will cause him to grant you a wish, giving +10 reward. If you are at the bridge and choose to run across it, you will become very sweaty, causing all your clothes to become soaked and emanate a foul smell, giving -10 reward. If you are at the bridge and choose to dance across it, a group of monkeys in the trees above will laugh at you and insult your embarrassing dance moves, giving -12 reward. This information is summarized in the following diagram:
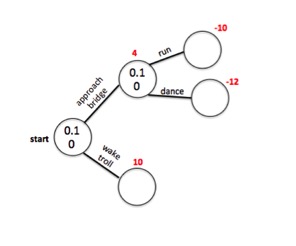
Note that Q values associated with terminal nodes are set at zero as there are no actions available from these states.
Suppose you:
1. perform action a in state s, which is the action with the highest Q value in state s
2. move to new state s' and observe reward R(s')
3. get ready to perform action a', which is the action with the highest Q value in state s'
Then you will update your Q value estimate for Q(s,a) with the following update equation:
prediction error = [R(s') + Q(s’,a’)] - Q(s,a)
Q(s,a) ? Q(s,a) + (? * prediction error)
Assume that ? = 1.0.
As an example, we will work through the first iteration, which has two steps:
Step 1
We start in the START state, and we have two action options: "approach bridge" and "wake troll." Because our initial estimate of Q(start, approach bridge) = 0.1 is greater than our initial estimate of Q(start, wake troll) = 0, we choose "approach bridge." This moves us to state "at bridge," and gives a reward of 4. We then look at our possible actions in state "at bridge," and see that the highest Q value is given by Q(at bridge, run) = 0.1. We thus update our Q value like so:
prediction error = 4 = [4 + 0.1] - 0.1
Q(start, approach bridge) = 4.1 = 0.1 + ( 1 * 4 )
Step 2
Now we are in the state "at bridge", and we have two action options: "run" and "dance." Because our current estimate of Q(at bridge, run) = 0.1 is greater than our current estimate of Q(at bridge, dance) = 0, we choose "run." This moves us to state "at other side of bridge," and gives a reward of -10. There are no actions for "at other side of bridge" and its Q value is thus 0. We thus update our Q value like so:
prediction error = -10.1 = [-10 + 0] - 0.1
Q(at bridge, run) = -10 = 0.1 + ( 1 * -10.1 )
We define an "iteration" as starting at the START node and reaching a terminal node. After each iteration, you go back to the START node. After this first iteration, here are the new Q values:
Q(start, approach bridge) = 4.1
Q(start, wake troll) = 0
Q(at bridge, run) = -10
Q(at bridge, dance) = 0
Notice that on this first iteration, the Q values changed only for the two states updated above. They did not change for Q(at bridge, dance) and Q(start, wake troll).
The following questions ask you to report the Q values after completing iteration#2, iteration#3, and iteration#4. Note: when reporting updated Q values in the following, never round your answers.
GIANT HINT: After you complete iteration#4, the Q values that you report are the true Q values for this problem.
Using the Q values from the FIRST iteration, record the updated Q values after the SECOND iteration below:
Q(start, approach bridge) =
Q(start, wake troll) =
Q(at bridge, run) =
Q(at bridge, dance) =
Hint: When you transition from (s,a) to (s',a'), you'll only update Q(s,a), i.e., the state from which you've moved. All the other Q values will not change.
Expert Answer:



