

Question
SPARK, SPARK SQL... Chegg does not let me post the whole csv files (applicant.csv and record.csv) but i hope someone can still help. Below is
SPARK, SPARK SQL...
Chegg does not let me post the whole csv files (applicant.csv and record.csv) but i hope someone can still help. Below is a snippet of each csv files as an example:
- applicant.csv
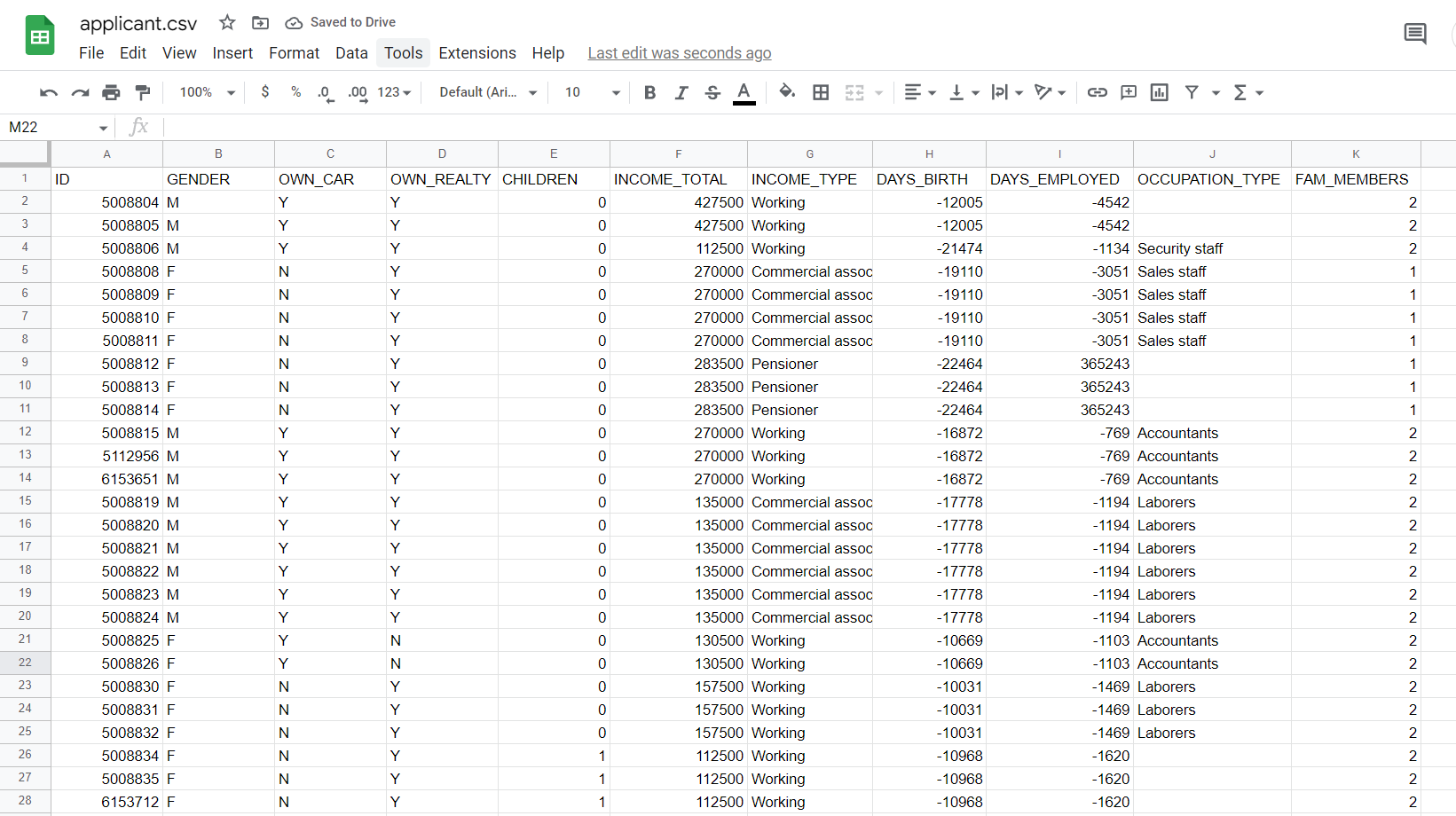
- record.csv
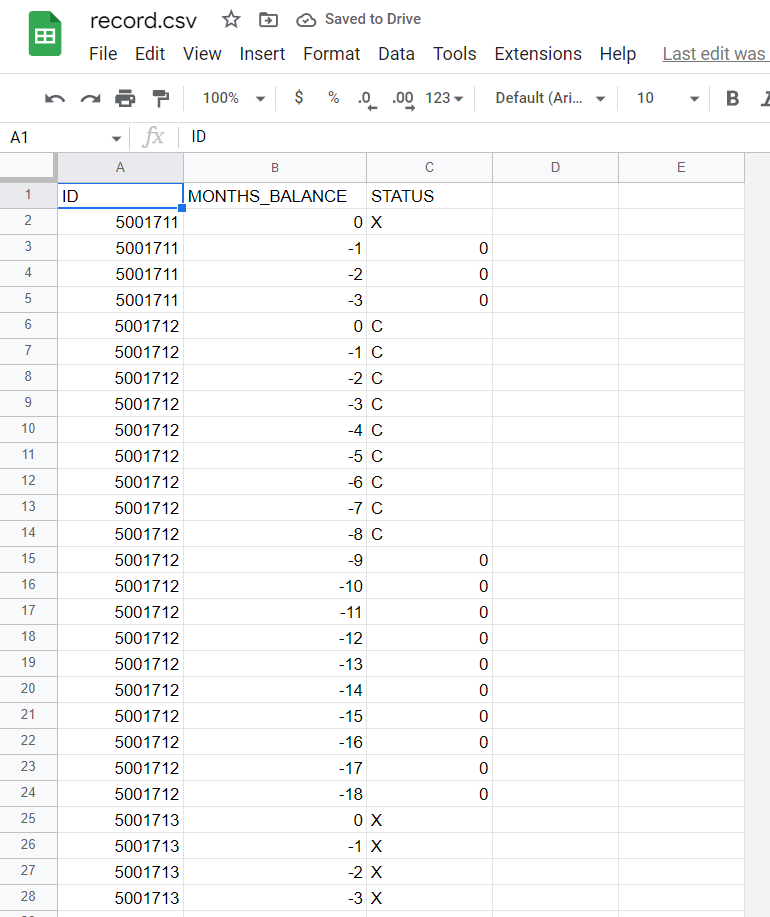
QUESTION:



Please help with this part (Q1-Q5). I need it as soon as possible! steps and descriptions with pictures needed.
If any programming language is needed, it must be Python. Everything else is Spark and "pyspark" console. Thank you!
applicant.csv Saved to Drive File Edit View Insert Format Data Tools Extensions Help Lasteditwas secondsago record.csv ( Saved to Drive File Edit View Insert Format Data Tools Extensions Help Last edit was Submit a single doc/pdf file that has Spark codes and an English description of what your code is doing. Also, include screenshots of your code and the output in the file. Perform the commands on "pyspark" console. Part I (60pts) Find applicant.csv and record.csv files from the course shell and answer the following questions: - The applicant.csv has information about the personal information of the credit card applicant. - ID: Client number; - GENDER: Gender; - OWN_CAR: Is there a car; - OWN_REALTY: Is there a property; - CHILDREN: Number of children; - INCOME_TOTAL: Annual income; - INCOME_TYPE: Income category; - DAYS_BIRTH: Birthday (Count backward from current day (0), -1 means yesterday); DAYS_EMPLOYED: Start date of employment (Count backward from current day (0). If positive, it means the person is currently unemployed.) - OCCUPATION_TYPE: Occupation; - FAM_MEMBERS: Family size; - The record.csv has the credit record of the applicant and consisted of three features. - ID: Client number; - MONTHS_BALANCE: Record month (The month of the extracted data is the starting point, backward, 0 is the current month, 1 is the previous month, and so on). - STATUS: Status (0: 1-29 days past due 1: 30-59 days past due 2: 60-89 days overdue 3: 90-119 days overdue 4: 120-149 days overdue 5: Overdue or bad debts, write-offs for more than 150 days C: paid off that month X : No loan for the month) Q1. How many male and female applicants applied for the credit card? (10 pts) Q2. Calculate the average annual income amount of the applicants for each of the income types (10 pts) Q3. Count the number of credit card applicants based on age group (10 pts) Q4. Merge the two data frames using inner join so that all variables (columns) in the applicant frame are added to the record data frame. Name the merged frame master_frame. How many observations (rows) are present in master_frame? Hint: Find an attribute from both data frames that can serve as a unique key (10 pts) Q5. Considering the clients whose credit record is more than 90 days due, as bad debt, find their occupations whose are not in bad dept and not unemployed ( 20 pts) applicant.csv Saved to Drive File Edit View Insert Format Data Tools Extensions Help Lasteditwas secondsago record.csv ( Saved to Drive File Edit View Insert Format Data Tools Extensions Help Last edit was Submit a single doc/pdf file that has Spark codes and an English description of what your code is doing. Also, include screenshots of your code and the output in the file. Perform the commands on "pyspark" console. Part I (60pts) Find applicant.csv and record.csv files from the course shell and answer the following questions: - The applicant.csv has information about the personal information of the credit card applicant. - ID: Client number; - GENDER: Gender; - OWN_CAR: Is there a car; - OWN_REALTY: Is there a property; - CHILDREN: Number of children; - INCOME_TOTAL: Annual income; - INCOME_TYPE: Income category; - DAYS_BIRTH: Birthday (Count backward from current day (0), -1 means yesterday); DAYS_EMPLOYED: Start date of employment (Count backward from current day (0). If positive, it means the person is currently unemployed.) - OCCUPATION_TYPE: Occupation; - FAM_MEMBERS: Family size; - The record.csv has the credit record of the applicant and consisted of three features. - ID: Client number; - MONTHS_BALANCE: Record month (The month of the extracted data is the starting point, backward, 0 is the current month, 1 is the previous month, and so on). - STATUS: Status (0: 1-29 days past due 1: 30-59 days past due 2: 60-89 days overdue 3: 90-119 days overdue 4: 120-149 days overdue 5: Overdue or bad debts, write-offs for more than 150 days C: paid off that month X : No loan for the month) Q1. How many male and female applicants applied for the credit card? (10 pts) Q2. Calculate the average annual income amount of the applicants for each of the income types (10 pts) Q3. Count the number of credit card applicants based on age group (10 pts) Q4. Merge the two data frames using inner join so that all variables (columns) in the applicant frame are added to the record data frame. Name the merged frame master_frame. How many observations (rows) are present in master_frame? Hint: Find an attribute from both data frames that can serve as a unique key (10 pts) Q5. Considering the clients whose credit record is more than 90 days due, as bad debt, find their occupations whose are not in bad dept and not unemployed ( 20 pts)
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Dare To Be Different An Auditors Personal Guide To Excellence
Authors: Daniel Clark
1st Edition
1490772405, 978-1490772400