

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Startcode: # introducing some constants; can also use the enum type if Python 3.4 # is available INT, FLOAT, ID, SEMICOLON, ASSIGNMENTOP, EOI, INVALID =


Startcode:
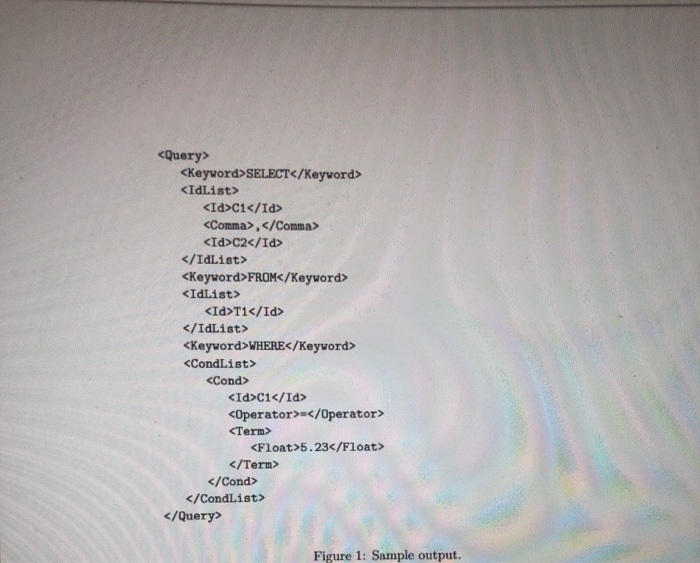
Your assignment is to use Python to write a recursive descent parser for a restricted form of SQL, the popular database query language. The lexical syntax is specified by regular expressions: Category Definition [0-9] [a-zA-Z int # introducing some constants; can also use the enum type if Python 3.4
# is available
INT, FLOAT, ID, SEMICOLON, ASSIGNMENTOP, EOI, INVALID = 1, 2, 3, 4, 5, 6, 7
def typeToString (tp):
if (tp == INT): return "Int"
elif (tp == FLOAT): return "Float"
elif (tp == ID): return "ID"
elif (tp == SEMICOLON): return "Semicolon"
elif (tp == ASSIGNMENTOP): return "AssignmentOp"
elif (tp == EOI): return "EOI"
return "Invalid"
class Token:
"A class for representing Tokens"
# a Token object has two fields: the token's type and its value
def __init__ (self, tokenType, tokenVal):
self.type = tokenType
self.val = tokenVal
def getTokenType(self):
return self.type
def getTokenValue(self):
return self.val
def __repr__(self):
if (self.type in [INT, FLOAT, ID]):
return self.val
elif (self.type == SEMICOLON):
return ";"
elif (self.type == ASSIGNMENTOP):
return ":="
elif (self.type == EOI):
return ""
else:
return "invalid"
LETTERS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
DIGITS = "0123456789"
class Lexer:
# stmt is the current statement to perform the lexing;
# index is the index of the next char in the statement
def __init__ (self, s):
self.stmt = s
self.index = 0
self.nextChar()
def nextToken(self):
while True:
if self.ch.isalpha(): # is a letter
id = self.consumeChars(LETTERS+DIGITS)
return Token(ID, id)
elif self.ch.isdigit():
num = self.consumeChars(DIGITS)
if self.ch != ".":
return Token(INT, num)
num += self.ch
self.nextChar()
if self.ch.isdigit():
num += self.consumeChars(DIGITS)
return Token(FLOAT, num)
else: return Token(INVALID, num)
elif self.ch==' ': self.nextChar()
elif self.ch==';':
self.nextChar()
return Token(SEMICOLON, "")
elif self.ch==':':
if self.checkChar("="):
return Token(ASSIGNMENTOP, "")
else: return Token(INVALID, "")
elif self.ch=='$':
return Token(EOI,"")
else:
self.nextChar()
return Token(INVALID, self.ch)
def nextChar(self):
self.ch = self.stmt[self.index]
self.index = self.index + 1
def consumeChars (self, charSet):
r = self.ch
self.nextChar()
while (self.ch in charSet):
r = r + self.ch
self.nextChar()
return r
def checkChar(self, c):
self.nextChar()
if (self.ch==c):
self.nextChar()
return True
else: return False
import sys
class Parser:
def __init__(self, s):
self.lexer = Lexer(s+"$")
self.token = self.lexer.nextToken()
def run(self):
self.statement()
def statement(self):
print ""
self.assignmentStmt()
while self.token.getTokenType() == SEMICOLON:
print "\t; "
self.token = self.lexer.nextToken()
self.assignmentStmt()
self.match(EOI)
print ""
def assignmentStmt(self):
print "\t"
val = self.match(ID)
print "\t\t" + val + " "
self.match(ASSIGNMENTOP)
print "\t\t:= "
self.expression()
print "\t"
def expression(self):
if self.token.getTokenType() == ID:
print "\t\t" + self.token.getTokenValue() \
+ ""
elif self.token.getTokenType() == INT:
print "\t\t" + self.token.getTokenValue() + " "
elif self.token.getTokenType() == FLOAT:
print "\t\t" + self.token.getTokenValue() + " "
else:
print "Syntax error: expecting an ID, an int, or a float" \
+ "; saw:" \
+ typeToString(self.token.getTokenType())
sys.exit(1)
self.token = self.lexer.nextToken()
def match (self, tp):
val = self.token.getTokenValue()
if (self.token.getTokenType() == tp):
self.token = self.lexer.nextToken()
else: self.error(tp)
return val
def error(self, tp):
print "Syntax error: expecting: " + typeToString(tp) \
+ "; saw: " + typeToString(self.token.getTokenType())
sys.exit(1)
print "Testing the lexer: test 1"
lex = Lexer ("x := 1 $")
tk = lex.nextToken()
while (tk.getTokenType() != EOI):
print tk
tk = lex.nextToken()
print
print "Testing the lexer: test 2"
lex = Lexer ("x := 1; y := 2.3; z := x $")
tk = lex.nextToken()
while (tk.getTokenType() != EOI):
print tk
tk = lex.nextToken()
print
print "Testing the lexer: test 3"
lex = Lexer ("x := 1; y : 2; z := x $")
tk = lex.nextToken()
while (tk.getTokenType() != EOI):
print tk
tk = lex.nextToken()
print
print "Testing the parser: test 1"
parser = Parser ("x := 1");
parser.run();
print "Testing the parser: test 2"
parser = Parser ("x := 1; y := 2.3; z := x");
parser.run();
print "Testing the parser: test 3"
parser = Parser ("x := 1; y ; 2; z := x");
parser.run();
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Intranet And Web Databases For Dummies
Authors: Paul Litwin
1st Edition
0764502212, 9780764502217