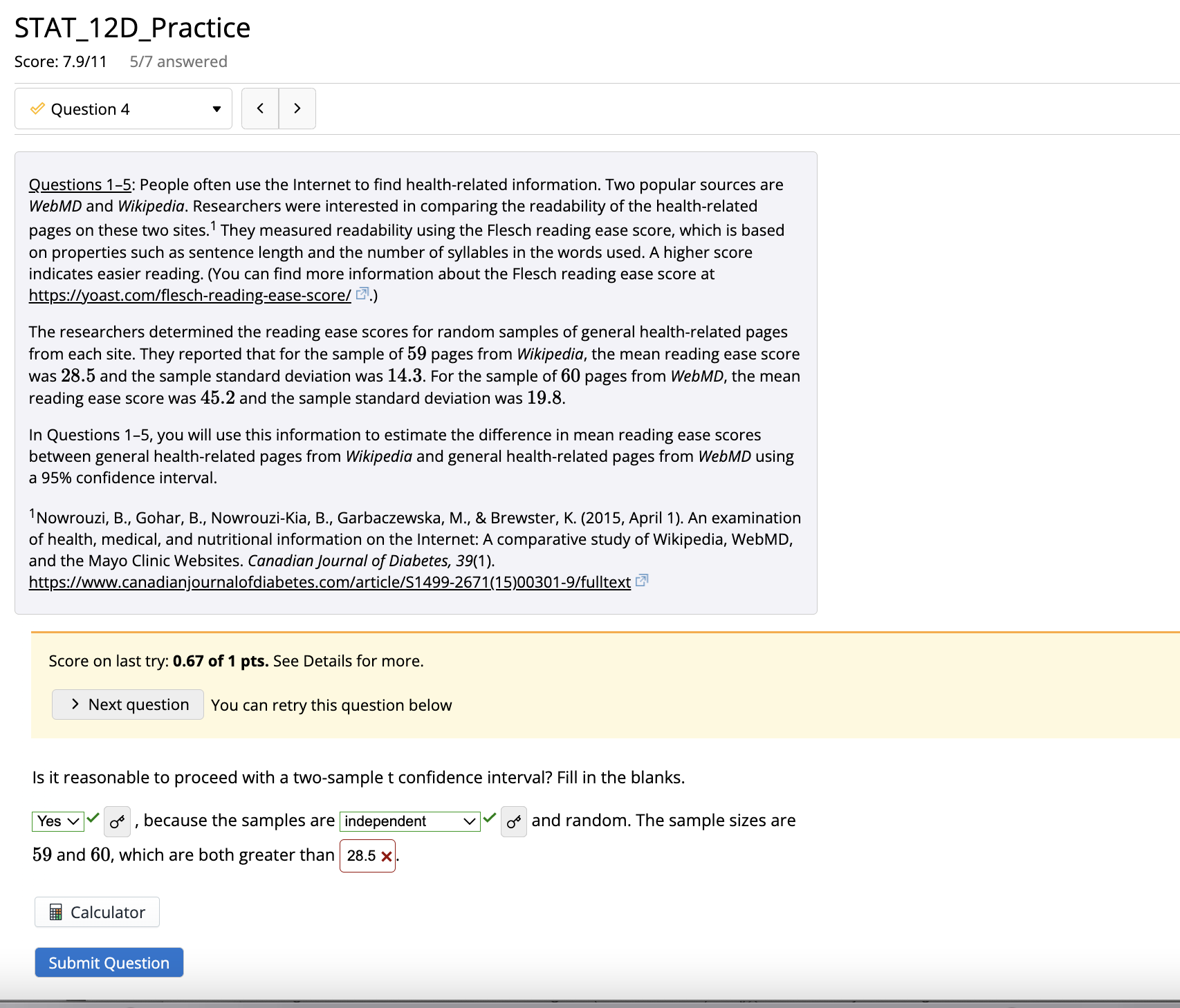
STAT_12D_Practice Score: 7.9/11 5/7 answered Question 4 Questions 1-5: People often use the Internet to find health-related information. Two popular sources are WebMD and Wikipedia.
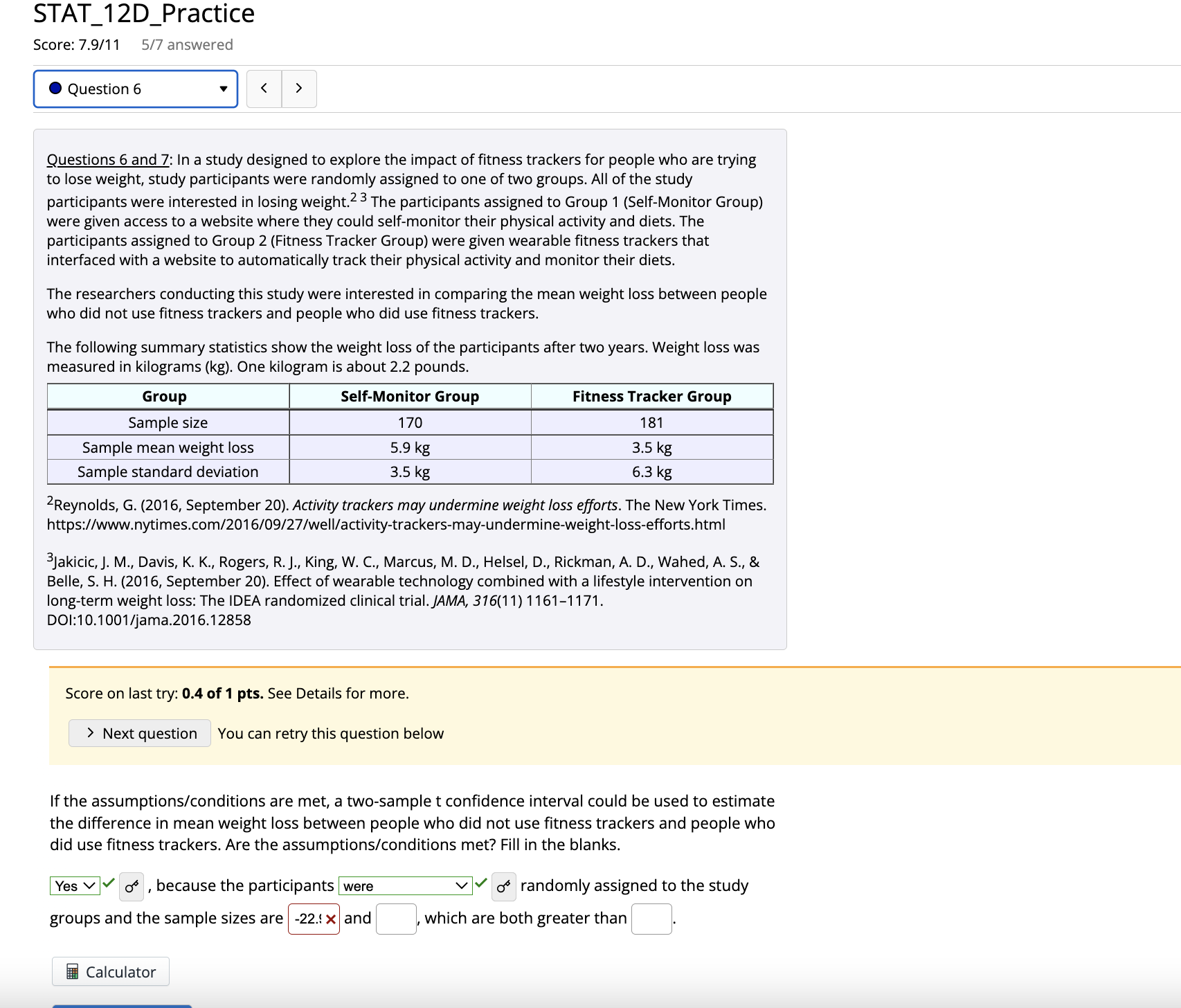
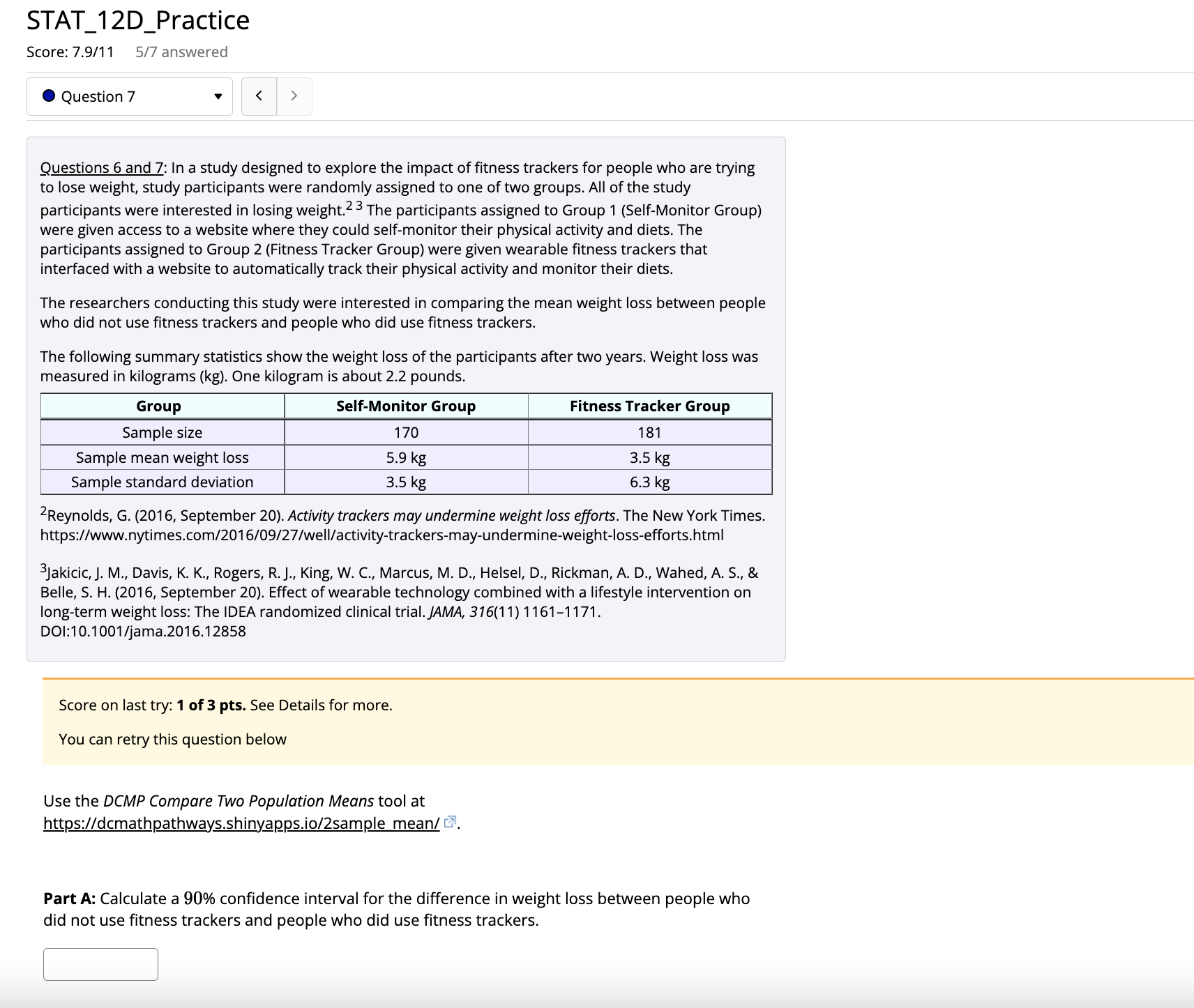
STAT_12D_Practice Score: 7.9/11 5/7 answered Question 4 Questions 1-5: People often use the Internet to find health-related information. Two popular sources are WebMD and Wikipedia. Researchers were interested in comparing the readability of the health-related pages on these two sites. ' They measured readability using the Flesch reading ease score, which is based on properties such as sentence length and the number of syllables in the words used. A higher score indicates easier reading. (You can find more information about the Flesch reading ease score at https://yoast.com/flesch-reading-ease-score/ [!) The researchers determined the reading ease scores for random samples of general health-related pages from each site. They reported that for the sample of 59 pages from Wikipedia, the mean reading ease score was 28.5 and the sample standard deviation was 14.3. For the sample of 60 pages from WebMD, the mean reading ease score was 45.2 and the sample standard deviation was 19.8. In Questions 1-5, you will use this information to estimate the difference in mean reading ease scores between general health-related pages from Wikipedia and general health-related pages from WebMD using a 95% confidence interval. "Nowrouzi, B., Gohar, B., Nowrouzi-Kia, B., Garbaczewska, M., & Brewster, K. (2015, April 1). An examination of health, medical, and nutritional information on the Internet: A comparative study of Wikipedia, WebMD, and the Mayo Clinic Websites. Canadian Journal of Diabetes, 39(1). https://www.canadianjournalofdiabetes.com/article/S1499-2671(15)00301-9/fulltext [ Score on last try: 0.67 of 1 pts. See Details for more. > Next question You can retry this question below Is it reasonable to proceed with a two-sample t confidence interval? Fill in the blanks. Yes , because the samples are independent vy and random. The sample sizes are 59 and 60, which are both greater than 28.5 x. Calculator Submit QuestionSTAT_12D_Practice Score: 7.9/11 5/7 answered .Question 6 Questions 6 and 7: In a study designed to explore the impact of fitness trackers for people who are trying to lose weight, study participants were randomly assigned to one of two groups. All of the study participants were interested in losing weight. The participants assigned to Group 1 (Self-Monitor Group) were given access to a website where they could self-monitor their physical activity and diets. The participants assigned to Group 2 (Fitness Tracker Group) were given wearable fitness trackers that interfaced with a website to automatically track their physical activity and monitor their diets. The researchers conducting this study were interested in comparing the mean weight loss between people who did not use fitness trackers and people who did use fitness track The following summary statistics show the weight loss of the participants after two years. Weight loss was measured in kilograms (kg). One kilogram is about 2.2 pounds Group Self-Monitor Group Fitness Tracker Group Sample size 170 18 Sample mean weight loss 5.9 kg 3.5 kg Sample standard deviation 3.5 kg 6.3 kg Reynolds, G. (2016, September 20). Activity trackers may undermine weight loss efforts. The New York Times. https://www.nytimes.com/2016/09/27/well/activity-trackers-may-undermine-weight-loss-efforts.html jakicic, J. M., Davis, K. K., Rogers, R. J., King, W. C., Marcus, M. D., Helsel, D., Rickman, A. D., Wahed, A. S., & Belle, S. H. (2016, September 20). Effect of wearable technology combined with a lifestyle intervention on long-term weight loss: The IDEA randomized clinical trial. JAMA, 316(11) 1161-1171. DOI:10.1001/jama.2016.12858 Score on last try: 0.4 of 1 pts. See Details for more. > Next question You can retry this question below If the assumptions/conditions are met, a two-sample t confidence interval could be used to estimate the difference in mean weight loss between people who did not use fitness trackers and people who did use fitness trackers. Are the assumptions/conditions met? Fill in the blanks. Yes V , because the participants were of randomly assigned to the study groups and the sample sizes are -22. x and , which are both greater than CalculatorSTAT_1 2D_Practice Score: 7.9/11 5/7 answered 0 Question 7 v Questions 6 and 7: In a study designed to explore the impact of tness trackers for people who are trying to lose weight, study participants were randomly assigned to one oftwo groups. All of the study participants were interested in losing weight.2 3 The participants assigned to Group 1 (Self-Monitor Group) were given access to a website where they could self-monitor their physical activity and diets. The participants assigned to Group 2 (Fitness Tracker Group} were given wearable fitness trackers that interfaced with a website to automatically track their physical activity and monitor their diets. The researchers conducting this study were interested in comparing the mean weight loss between people who did not use tness trackers and people who did use tness trackers. The following summary statistics show the weight loss of the participants after two years. Weight loss was measured in kilograms (kg). One kilogram is about 2.2 pounds. Group Self-Monitor Group Fitness Tracker Group Sample size 170 181 Sample mean weight loss 59 kg 3.5 kg Sample standard deviation 3.5 kg 6.3 kg ZReynolds, G. (2016, September 20). Activity trackers may undermine weight loss e'orts. The New York Times. https:/lwww.nytimes.com1'2016/09i27/welIlactivity-trackers-may-undermine-weight-Ioss-effortshtm| 3Jakicic,]. M., Davis, K. K., Rogers, R.J., King, W. C., Marcus, M. D., Helsel, D., Rickman,A. D., Wahed, A. 5., & Belle, S. H. (2016, September 20). Effect of wearable technology combined with a lifestyle intervention on long-term weight loss: The IDEA randomized clinical trial.jAMA, 316(11)11611171. DOI:10.1001/jama.2016.12858 Score on last try: 1 of3 pts. See Details for more. You can retry this question below Use the DCMP Compare Two Population Means tool at mpszildcmathpathwaysshinygppsioiZsample mean] :. Part A: Calculate a 90% condence interval for the difference in weight loss between people who did not use tness trackers and people who did use fitness trackers. Part A: Calculate a 90% condence interval for the difference in weight loss between people who did not use tness trackers and people who did use fitness trackers. Part B: Interpret the confidence interval in the context of this question. Fill in the blanks. I am % confident that the actual difference in mean weight loss between people who self- monitor and people who use fitness trackers is between and kilograms. Part C: An article in The New York Times describing this study has the title "Activity Trackers May Undermine Weight Loss Efforts." Is your confidence interval consistent with this headline? Yes; based on the confidence interval, it looks like the mean weight loss for people who use tness trackers to monitor activity and diet is less than the mean weight loss for people who just self-monitor. O No; based on the condence interval, it does not look like the mean weight loss for people who use fitness trackers to monitor activity and diet is less than the mean weight loss for people who just self-monitor. 0 Yes; based on the confidence interval, it looks like the mean weight loss for people who use tness trackers only is more than the mean weight loss for people who just self-monitor. O No; based on the condence interval, it does not look like the mean weight loss for people who use fitness trackers only is more than the mean weight loss for people who just self- monitor. d5\\/ E Calculator STAT_1 2C_Pra ctice Score: 71'10 51'6 answered 0 Question 5 v Questions 5 and 6: During flu season, many people end up at a hospital emergency room in a crowded waiting room, where they may expose other people to the u. Researchers at Stanford University2 wondered if it would be feasible to set up a drive-through clinic where patients could be diagnosed and treated without leaving their cars. To test this model, they set up a drive-th rough clinic in the parking structure of the Stanford University Medical School. Healthy volunteers were each given a scenario with a medical history and a list of symptoms that would allow them to respond to questions from an emergency room physician. These scenarios were thought to be representative of flu patients often seen in emergency rooms. One of the variables measured in the study was the amount of time to process a patient from admission to discharge. Z Weiss, E. A., Ngo,J., Gilbert, G. H., & Quinn,J.V. (2010,]anuary 18). Drive-through medicine: A novel proposal for rapid evaluation of patients during an influenza pandemic. Annals ofEmergency Medicine, An lnternoti'onaljournof, 55(3), 268273. https:li'doi.org/10.1016!].annemergmed.2009.11.025 Score on last try: 1 of3 pts. See Details for more. > Next question You can retry this question below A total of 38 people were seen in the drivethrough clinic. For this sample of 38 patients, the mean time from admission to discharge was 26 minutes and the standard deviation was 1.57 minutes. Since the scenarios given to the 38 volunteers were thought to be representative of u patients, the researchers thought it was reasonable to think of this sample as a random sample ofu patients. Because the sample size was greater than 30, it is reasonable to use a one-sample t interval to estimate the true mean time to process, diagnose, and treat a flu patient using the drivethrough model. Go to the DCMP inference for a Population Mean tool at mpswdcmathpathwaysshinyapszo/lnference mean/ . Under the Condence and Significance Tests ta b: 0 Select "Summary Statistics" from the drop-down menu under Enter Data. . Type in "Processing Time" for the name ofthe variable, and then enter the sample size and the sample mean and standard deviation for this example. 0 For Type of Inference, select "Confidence Interval." - Use the slider for the condence level to select a 95% condence level. Part A: Use the tool to calculate a 95% confidence interval for the mean time to process, diagnose, and treat a flu patient using the drive-through model. Part B: Interpret the confidence interval in the context of this question. Fill in the blanks. I am -% condent that the mean processing time for flu patients seen in the drive- through model is between 12.37 x and Be sure that your interpretation includes a clear reference to the population of interest. Part C: The researchers in this study indicated that the mean processing time for u patients seen 'n the emergency room was about 90 minutes. Based on your confidence interval, does it appear :hat the drive-th rough model has benefits in addition to keeping u patients isolated? Fill in the alanks. Yes v V d\" ; based on the confidence interval, it looks like the mean time from admission to discharge is much less v V 0' for the drivethrough model than for when patients are processed in the emergency room. The drive-through model seems to be more v V 0\" efficient in terms of the time required. E Calculator STAT_5A_Practice Score: 5.75/9 2/2 answered Question 1 To complete this practice assignment, go to the Relationship Between Two Quantitative Variables tool at https://dcmathpathways.shinyapps.io/Association Quantitative/ Score on last try: 2.34 of 4 pts. See Details for more. > Next question Using the broadband and Gross Domestic Product (GDP) dataset, create a scatterplot that describes the relationship between GDP in billions of U.S. dollars (USD) and the number of broadband subscribers. Answer the following: Part A: What is the mean GDP in billions of USD? Answer: 67788 * 0 1,909 USD USD Part B: Does the dataset contain any outliers? If so, which countries? Outliers: Yes of Countries that are outliers (Choose all that apply): Poland O United Kingdom There are no outliers Peru O China O The country is not an answer choice Part C: Describe the relationship between the number of broadband subscribers and GDP. Include plete description Fill in the blanksPart C: Describe the relationship between the number of broadband subscribers and GDP. Include a complete description of the shape. Fill in the blanks. There is a positive V relationship between GDP (in billions of USD) and the number of broadband subscribers. This relationship seems to be |linear vy with the exception of a few atypical points. Part D: Calculate and interpret the value of the correlation coefficient, r. 817888 X 0.771 (rounded to the nearest thousandth) Interpretation (fill in the blank): There is a moderate to strong positive v v relationship between GDP (in billions of USD) and the number of broadband subscribers. Calculator Submit QuestionSTAT_5A_Practice Score: 5.75/9 2/2 answered Question 2 Score on last try: 3.33 of 5 pts. See Details for more. You can retry this question below Continue using the broadband and GDP dataset, but now, turn on the option "Enable Dragging/Deleting of Points." Remove the observation for China by dragging the dot representing China off of the plot. Part A: What is the new mean GDP in billions of USD? 1,909 X USD Part B: How did the relationship between the number of broadband subscribers and GDP change? Edit Insert Formats B / U X X A A there is a clear trend in that countries with larger GDP have a larger number of broadband subscribers. Part C: Calculate and interpret the value of the correlation coefficient, r. r = (rounded to the nearest thousandth) Interpretation (Fill in the blank)
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance