Subject : Statistic and Probability Topic : Data Analysis (Regression) Instruction : Solve the given problem (Letter A-C) A. Is there a significant relationship between
Subject: Statistic and Probability Topic: Data Analysis (Regression) Instruction: Solve the given problem (Letter A-C)
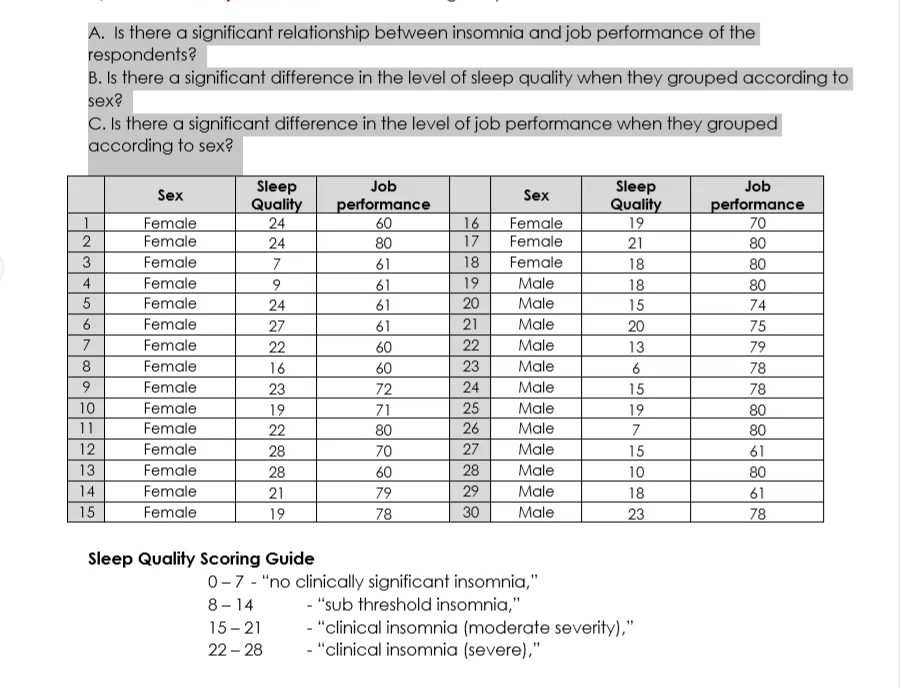
A. Is there a significant relationship between insomnia and job performance of the respondents? B. Is there a significant difference in the level of sleep quality when they grouped according to sex? C. Is there a significant difference in the level of job performance when they grouped according to sex? Sleep Job Job Sex Sex Sleep Quality performance Quality performance Female 24 60 16 Female 19 70 Female 24 80 17 Female 21 80 3 Female 7 61 18 Female 18 80 Female 9 61 19 Male 18 80 Female 24 61 20 Male 15 74 Female 27 61 21 Male 20 75 Female 22 60 22 Male 13 79 8 Female 16 60 23 Male 6 78 Female 23 72 24 Male 15 78 10 Female 19 71 25 Male 19 80 11 Female 22 80 26 Male 7 80 12 Female 28 70 27 Male 15 61 13 Female 28 60 28 Male 10 80 14 Female 21 79 29 Male 18 61 15 Female 19 78 30 Male 23 78 Sleep Quality Scoring Guide 0-7 - "no clinically significant insomnia," 8- 14 - "sub threshold insomnia," 15-21 - "clinical insomnia (moderate severity)," 22 - 28 - "clinical insomnia (severe)."Linear regression bivariate data- data involving two variables Least squares regression line-deviations from each dline that minimizes the sum of the squares of the vertical data point to the line y= ax +b where a=nExy- (Ex)(Zy)Ex^2- (EX)^2 and b=mean of y-a x mean of x ex X 6 8 10 5 4 Y 10 15 4 8 11 mean of x=6,6 Mean of y=9.8 a=14.1800340 b=-0.6637931034 equation of regression line is y= 14.1800340x -0.6637931034 if X=20 y= 14.1800340(20) -0.6637931034=155.316580 Correlation-degree of relationship of two variables coefficient of correlation r ranges between -1 to 1 r= 1 perfect positive r=-1 perfect negative r=0 no correlation positive correlation-as x increases y also increases negative correlation-as x increases y decreases and vice versas Pearson r=nExy- (Ex)(Ey)/(nEx^2- (EX)^2)(nzy^2- (EX)^2) Spearman p=1-6ED^2^2-nBinary and Multinomial Logistic Regression What is Logistic regression Logistic regression is a frequentlyused method as it enables binary variables, the suns of binary variables, or polyternous variables [variables with more than two categories] to be modeled {dependent variable]. It is frequently used in the medical domain [whether a patient will get well or not}, in sociology [survey analysis}, epidemiology and medicine, in quantitative marketing [whether or not products are purchased following an action} and in finance for modeling risks {scoring}. The principle of the logistic regression model is to link the occurrence or nonoccurrence of an event to explanatory variables. Models for logistic regression Logistic and linear regression belong to the same family of models called ELM {Generalized ljnear Models]: in both cases, an event is linked to a linear combination of explanatory variables. For linear regression, the dependent variable follows a normal distribution N (p, s} where p is a linear function of the explanatory variables. For logistic regression, the dependent variable. also called the response variable, follows a Bernoulli distribution for parameter p {p is the mean probability that an event will occur] when the experiment is repeated once, or a Binomial (n, p] distribution if the experiment is repeated n times [for example the same dose tried on n insects}. The probability parameter p is here a linear combination of explanatory variables. The must common functions used to link probability p to the explanatory variables are the logistic function [we refer to the Legit model} and the standard normal distribution function {the Mmodel}. Both these functions are perfectly symmetric and sigmoid: XLSTAT provides two other functions: the complementary Loglog function is closer to the upper asymptote. The qunction is on the contrary closer the axis of abscissa. The analytical expression of the models is as follows: - Losit: a = exptll I {1 + exptn . m p = 1H2rt Jm...|3}t explxzjzwx . Complementary Logrlog: p = 1 exp[exp[fi)i}] ' W P = skillWHEN 1littlhere BX represents the linear combination of variables {including constants}. The lmowledge of the distribution of the event being studied gives the likelihood of the sample. To estimate the 13 parameters of the model {the coefcients of the linear function}, we tryr to maximize the likelihood function Contrary to linear regression, an exact analytical solution does not exist. So an iterative algorithm has to be used. KETAT uses a NewtonRaphson algorithm The user can change the maximum number of iterations and the convergence threshold if desired. Separation problem In the example above' the treatment variable is used to make a clear distinction between the positive and negative cases. In such cases, there is an indeterminacy on one or mre parameters for which the variance is as high as the convergence threshold is low which prevents a condence interval around the parameter from being given. To resolve this problem and obtain a stable solution, Firth {1993} proposed the use of a penalized likelihood function )tleAT offers this solution as an option and uses the results provided by Heinze (2002}. If the standard deviation of one of the parameters is very high compared with the estimate of the parameter, it is recommended to restart the calculations with the 'Firth' option activated. The multinomial logit model The multinomial logit model, that conespond to the case where the dependent variable has more than two categories, has a different parameterization from the logit model because the response variable has more than two categories. It focuses on the probability to choose one of the J categories knowing some explanatory variables. The analytical expression of the model is as follows: Log[p{y 2] lxi} I pty :1 |xi}] : orj + [313; where the category 1 is called the reference or control category. All obtained parameters have to be interpreted relatively to this reference category. The probability to choose categorri is: Ply =J' Iii} = mini + BiiiiJ f [1 + 924 mink + Blew} For the reference category, we have: p[y :1 | xi] = 1 f ['I + 321.: amtok + [3%]
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance