

Question
The aim of this assignment is to program value iteration, policy iteration, and modified policy iteration for Markov decision processes in Python. a procedure for
The aim of this assignment is to program value iteration, policy iteration, and modified policy iteration for Markov decision processes in Python.
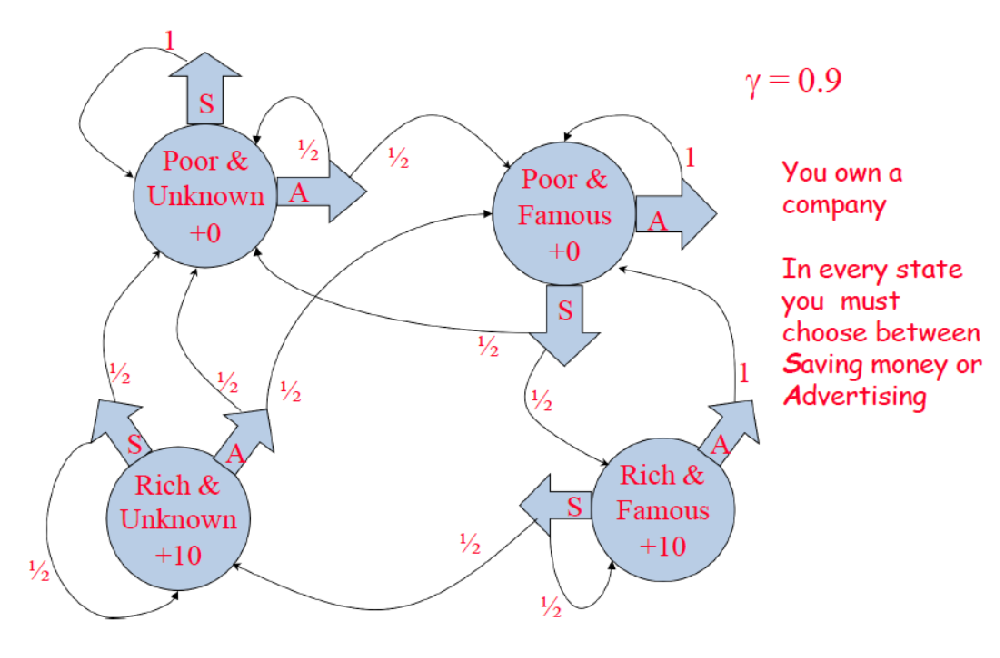
a procedure for the modified policy iteration def modifiedPolicyIteration () that has the following parameters: self,initialPolicy,initialV,nEvalIterations,nIterations,tolerance. Set nEvalIterations, nIterations, and tolerance to 5, np.inf and 0.01 as default values, respectively. o initialPolicy Initial policy: array of |S| entries o initialV -- Initial value function: array of |S| entries o nEvalIterations -- limit on the number of iterations to be performed in each partial policy evaluation: scalar (default: 5) o nIterations -- limit on the number of iterations to be performed in modified policy iteration: scalar (default: infinity) o tolerance -- threshold on +1 that will be compared to a variable epsilon (initialized to np.inf): scalar (default: 0.01) This procedure should return a policy. o policy -- Policy: array of |S| entries. o iteration the number of iterations performed: scalar o epsilon -- +1: scalar After defining your MDP class with all its members, you should instantiate an MDP object to construct the simple MDP as described in the given network: mdp = MDP(T,R,discount) o Transition function: |A| x |S| x |S'| array o Reward function: |A| x |S| array o Discount factor: scalar in [0,1)
Do it with the given parameters. Not the process !!!
You own a company In every state you must choose between Saving money or AdvertisingStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Design Application Development And Administration
Authors: Michael V. Mannino
4th Edition
0615231047, 978-0615231044